
斯坦福大学公布榜单:通义千问开源模型Qwen2-72B排名最高
![]() 前沿资讯
1719132349更新
前沿资讯
1719132349更新
![]() 0
0
近日,斯坦福大学展示了大模型测评榜单HELM MMLU的最新结果,阿里巴巴的通义千问开源模型Qwen2-72B成绩卓越,超越了Llama3-70B,成为排名最高的开源大模型。
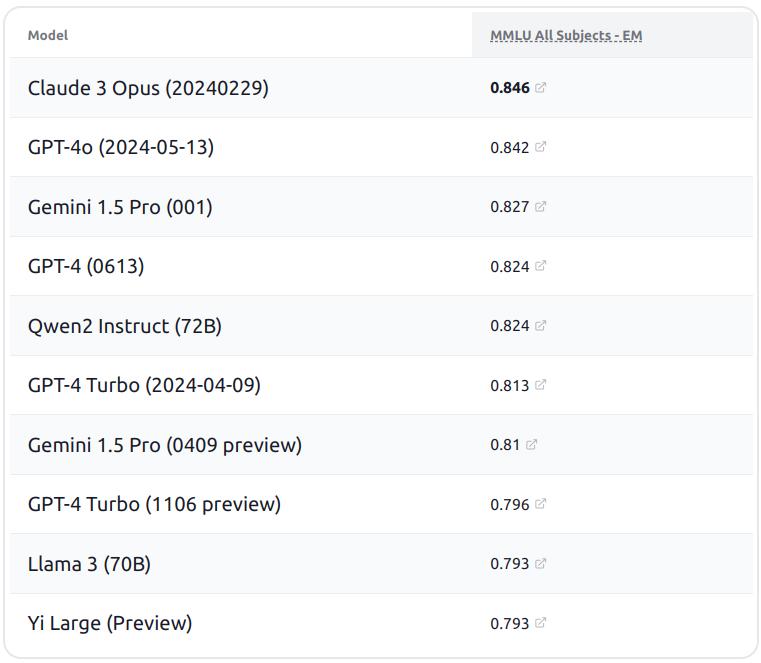
MMLU(Massive Multitask Language Understanding,大规模多任务语言理解)作为业界公认的大模型测评基准,覆盖了从基础数学到法律、历史等57个领域,意在全面评估模型在世界知识和问题解决方面的能力。然而,由于不同模型在测评中使用的技术标准不一,导致结果的一致性和可比性受到影响。为解决这一问题,斯坦福大学基础模型研究中心提出了HELM评估框架,创建了一种透明、可复现的评估方法。该方法基于HELM框架,对不同模型在MMLU上的评估结果进行标准化和透明化处理,比如,对所有参评模型都采用相同的提示词;对每项测试主题都给模型提供同样的5个示例进行情境学习等等。
在HELM MMLU的最新榜单中,斯坦福大学基础模型研究中心主任Percy Liang宣布,阿里巴巴的Qwen2-72B模型排名第五,仅次于Claude 3 Opus、GPT-4o、Gemini 1.5 pro、GPT-4,是排名第一的开源大模型,也是排名最高的中国大模型。
通义千问Qwen2模型于6月初开源,提供了5个不同尺寸的预训练和指令微调模型,以满足不同场景的需求。自开源以来,Qwen系列模型的下载量已超过1600万次。
 豫公网安备41010702003375号
豫公网安备41010702003375号