
腾讯推出 VoCo-LLaMA,利用大模型压缩视觉信息
![]() 工具推荐
1719221617更新
工具推荐
1719221617更新
![]() 1
1
由清华大学深圳国际研究生院、腾讯 ARC 实验室和 UC Santa Cruz 的研究人员共同开发的 VoCo-LLaMA 可将数百个视觉tokens有效压缩为单个tokens,同时最大限度地减少视觉信息的损失。该方法在大语言模型的视觉tokens和文本tokens之间引入了特殊的 "视觉压缩"(VoCo)tokens,使模型本身能够压缩和提炼视觉tokens。
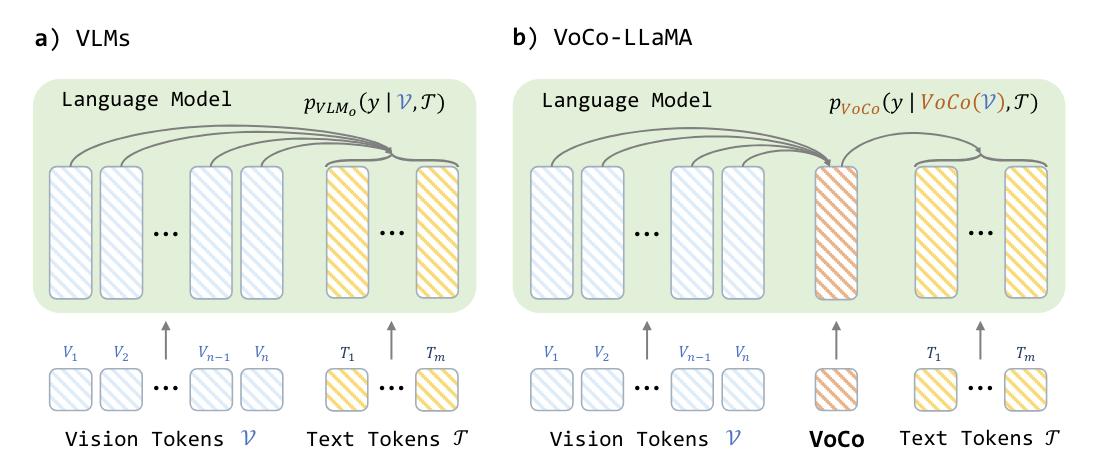
使用 VoCo-LLaMA,可以实现 576 倍的压缩率,同时在 GQA、MMBench 和 VQAv2 等常见视觉理解基准测试中保持 83.7% 的性能。压缩后的tokens还能显著提高效率:缓存存储量减少 99.8%,FLOPs 减少 94.8%,推理时间缩短 69.6%。
通过利用注意力蒸馏,VoCo-LLaMA 将大语言模型对未压缩的视觉tokens的理解提炼到压缩 VoCo tokens。这有助于在没有专门的跨模态模块的情况下进行有效压缩。这种方法可以通过在标准视觉指令调整过程中修改注意力掩码而轻松实现,无需额外的训练阶段。在 MSVD-QA 和 MSRVTT-QA 等视频基准测试中,VoCo-LLaMA 通过捕捉压缩视频帧tokens间的时间相关性,表现优于之前的压缩方法。
VoCo-LLaMA 虽然优势明显,但也有其局限性。它削弱了模型理解未压缩tokens的能力,在处理各种细粒度压缩级别时也很吃力。但它为克服视觉语言模型的上下文窗口瓶颈提供了一条途径,从而实现更多可扩展的多模式应用。
去年,苹果公司发表了一篇题为 "LLM in a Flash: Efficient Large Language Model Inference with Limited Memory "的论文,概述了如何在 DRAM 有限的设备上运行大语言模型。看来,苹果也在使用压缩技术为边缘用例优化大语言模型。
 豫公网安备41010702003375号
豫公网安备41010702003375号