
Meta推出“连续思维链Coconut”技术,提供两种推理方式,可显著提升模型推理能力
![]() 工具推荐
1733905420更新
工具推荐
1733905420更新
![]() 0
0
大语言模型已展现出卓越的推理能力,然而,当前大语言模型在推理方面存在一个根本性的制约因素:其训练目标中的下一个标记预测任务,使得大语言模型在进行推理时必须以单词标记的形式来呈现推理过程。例如,流行的思维链(CoT)推理方法就是通过提示或训练大语言模型用自然语言逐步生成解决方案,但这种基于语言的推理方式与人类认知结果形成鲜明对比。

诸多神经影像学研究表明,在各类推理任务中,人类大脑中负责语言理解和产生的语言网络,在很大程度上处于不活跃状态,进一步的证据显示,人类语言主要是为了交流而非推理。大语言模型使用语言进行推理时暴露出一个显著问题:在推理链中,每个推理标记所需的推理量差异巨大,但当前模型架构在预测每个标记时几乎分配相同的计算资源。推理链中的大多数标记仅仅是为了保证文本的流畅性,对实际推理过程的贡献微乎其微,一些关键标记的生成则需要复杂的规划,这对大语言模型构成了巨大挑战。虽然先前已有研究尝试解决这些问题,如通过提示大语言模型生成简洁的推理链,或者在生成关键标记前进行额外的推理,但这些解决方案仍局限于语言空间内,未能触及根本问题。理想情况下,这些模型应能在无语言约束的情况下自由推理,仅在必要时将结果转化为语言。
为了让大语言模型能在更自由的空间里推理,Meta研究人员提出了一个新方法:Coconut(连续思维链)。这个方法能够让大语言模型能在“用语言表达”和“在潜在空间思考”这两种模式之间切换。在“用语言表达”的时候,模型就像平常一样,一个词一个词地接着生成句子;而在“在潜在空间思考”的时候,模型会把刚刚想的东西(也就是最后一个隐藏状态)直接当作下一步的输入,这个就叫做“连续思维”。模型会用<bot>和<eot>这两个特殊符号来标记什么时候开始和结束这种特殊的思考模式。不过要注意的是,在特殊思考的时候,模型不会把这个思考过程转化成语言。
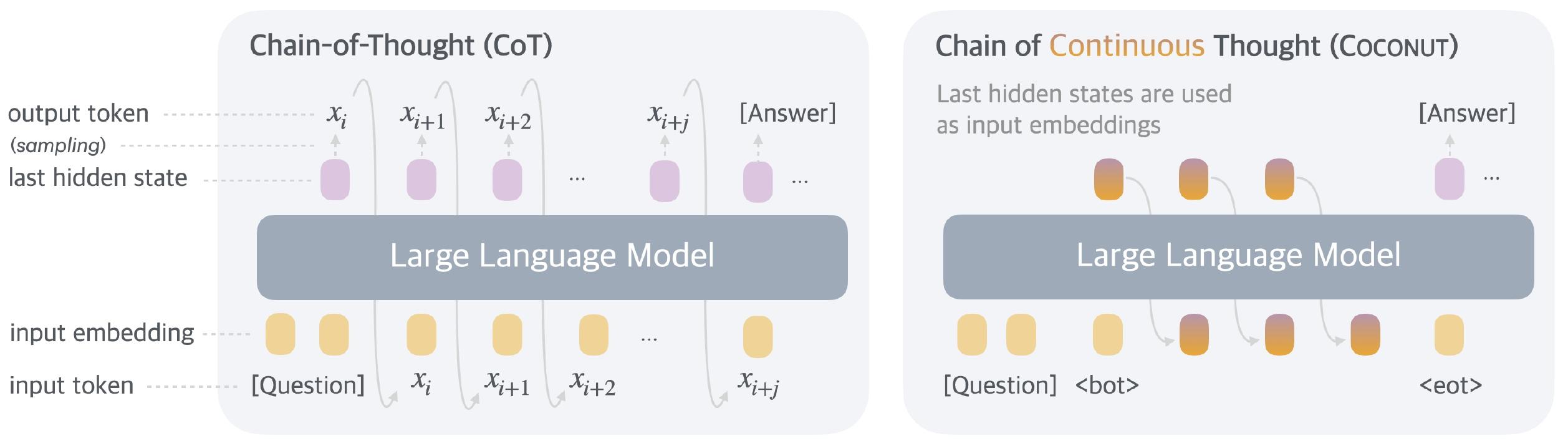
训练的时候,重点放在让模型解决问题上,给模型一个问题,让它通过思考得出答案。研究人员使用了一种多阶段的训练方法,根据语言CoT数据来指导模型的连续思维。一开始,模型先在普通的CoT例子上学习,后面的阶段,到了第k阶段,就把CoT里前面k个推理步骤换成k×c个连续思维(c这个数字可以控制用多少个连续思维来替换一个普通的语言推理步骤)。每次训练阶段切换的时候,优化器的状态也会重新设置,还会在合适的地方插入<bot>和<eot>这两个符号来把连续思维包起来。训练的时候,会把问题和连续思维上的损失盖住一部分,这样做是为了让模型能更好地预测后面的推理,让模型能学到比我们平常说话更有效的推理方法,连续思维是可以调整的,也能反过来影响前面的步骤。

推理的时候,和普通的语言模型差不多,就是在特殊思考模式下,直接把最后隐藏状态当作下一步输入。对于<eot>这个符号,研究人员想了两种办法:一种是训练模型自己判断什么时候结束特殊思考;另一种是简单地把特殊思考固定到一个长度。实验的时候为了简单,就用了第二种办法。
为了看看提出的Coconut方法好不好用,研究人员在三个数据集上做了实验,主要观察模型给出的答案的准确性,还有推理效率。
实验用了GSM8k(数学推理)、ProntoQA和ProsQA(逻辑推理)这三个数据集。数学推理的GSM8k里是小学水平的数学题,更像真实世界里会遇到的问题;逻辑推理的ProntoQA和ProsQA,需要根据条件判断结论对不对,ProsQA是研究人员新构造的数据集,它的问题更难,需要模型好好规划和搜索才能找到答案。
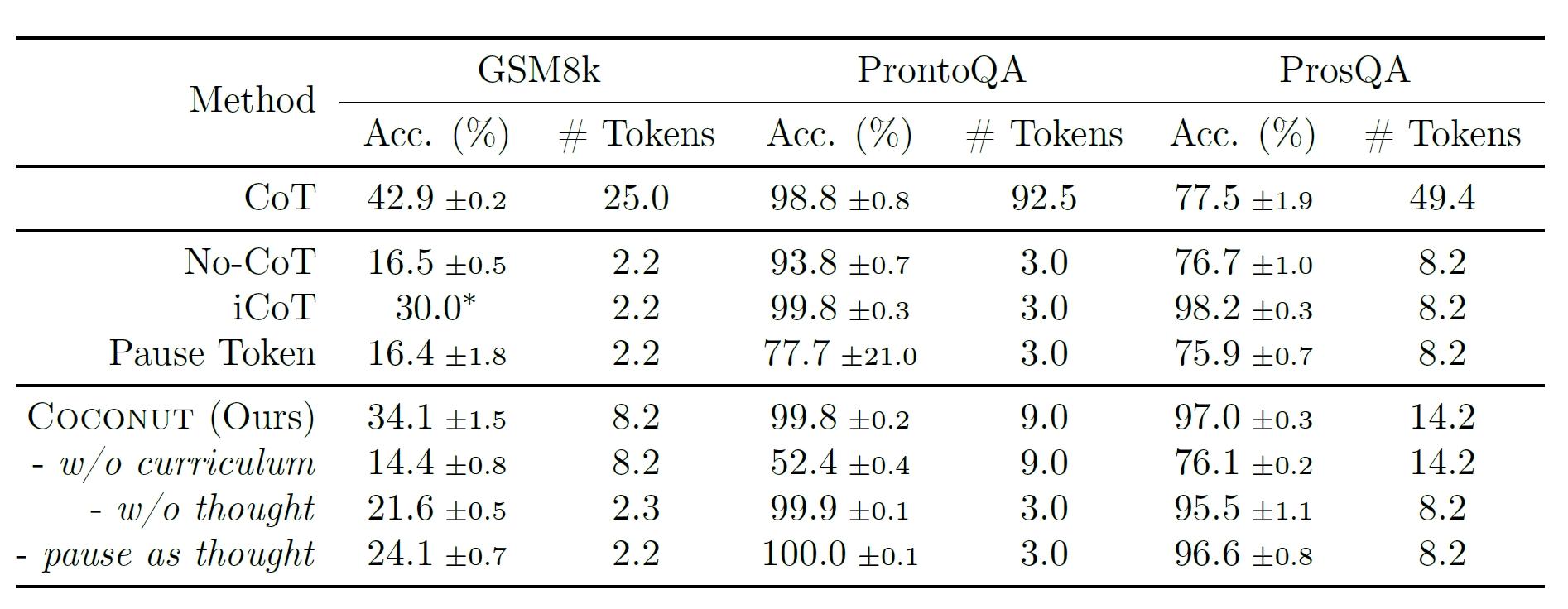
实验里对比了好几种方法。基线方法有CoT(用完整推理链训练语言模型,推理时先输出推理链再给答案)、No-CoT(直接生成答案,不用推理链)、iCoT(用语言推理链训练,慢慢去掉前面的推理步骤,最后直接给答案)、Pausetoken(在问题和答案间插<暂停>标记来增加计算能力)。Coconut也有几个变体,w/ocurriculum(直接用最后阶段只有问题和答案的数据训练)、w/othought(多阶段训练但不用连续思想)、Pauseasthought(用<暂停>标记代替连续思想,其他和Coconut一样的多阶段训练)。
结果显示,连续思想确实能让大语言模型推理变得更好,Coconut比No-CoT表现好,在ProntoQA和ProsQA上甚至比CoT还好。比如说在GSM8k实验里,增加连续思想的数量(用c来控制,从0到1再到2),模型性能就越来越好,表明在潜在空间里连续思考也能像CoT那样一环扣一环增强推理能力,而且在像ProsQA这种需要好好规划的任务里,Coconut和它的变体以及iCoT比CoT强的多,表明潜在空间推理在规划多的任务里很有优势。
 豫公网安备41010702003375号
豫公网安备41010702003375号