
DeepSeek-V3发布,计算效率极高,是llama 3系列的14倍!
![]() 工具推荐
1735293378更新
工具推荐
1735293378更新
![]() 2
2
DeepSeek最新发布的DeepSeek-V3是一个拥有671B参数的Mixture-of-Experts(MoE)语言模型,每个token激活37B参数,为了实现高效的推理和成本效益的训练,该模型采用了多头潜在注意力(MLA)和DeepSeekMoE架构。该模型采用了无辅助损失的负载平衡策略,并设置了多token预测训练目标以增强性能。
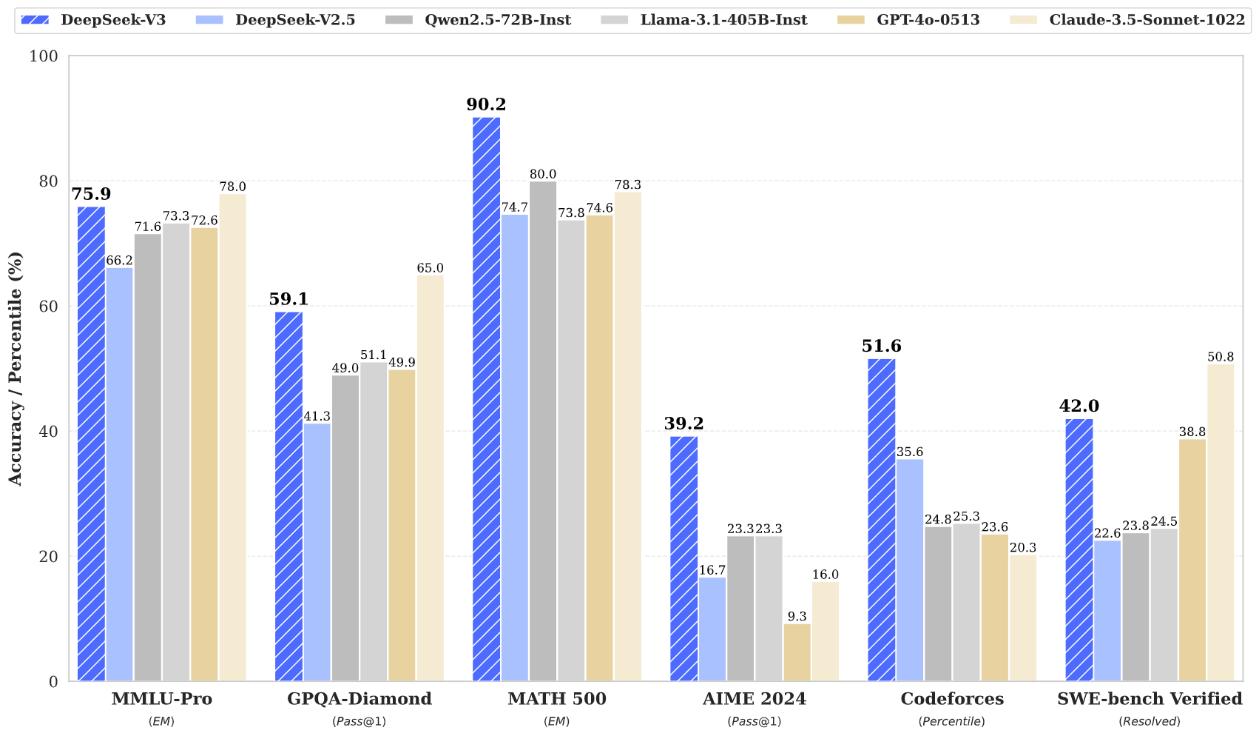
在预训练阶段,该模型在14.8万亿高质量token上进行了预训练,随后进行了监督式微调和强化学习阶段以充分发挥其能力。DeepSeek-V3一个创新之处在于其预训练效率。它采用了FP8混合精度训练框架,这是首次在极大规模模型上验证了FP8训练的可行性和有效性。通过算法、框架和硬件的协同设计,DeepSeek-V3克服了跨节点MoE训练中的通信瓶颈,实现了全计算通信重叠。在后训练阶段,DeepSeek-V3从DeepSeek R1系列模型中提取推理能力,尤其是从长链推理(CoT)模型中提取,并将这些能力蒸馏到标准模型中。
DeepSeek-V3的预训练过程展现了极高的效率和成本效益。根据官方数据,整个预训练阶段仅消耗了266.4万H800 GPU小时,与此相对的是,Llama 3系列模型的计算预算则多达3930万H100 GPU小时,足以训练DeepSeek-V3至少14次。

在性能表现上,DeepSeek-V3极为出色,与领先的闭源模型相比也毫不逊色,甚至在某些任务上有所超越。其多语言处理能力卓越,在多语言编程领域完成率从17%提升至 48.4%,超越Claude 3.5 sonnet,在Aider多语言排行榜中跃居第二名,在语言翻译、文本生成及语境理解等方面优势显著。在 GLUE、SQuAD 等权威评测中,该模型成绩优异,部分细分领域甚至超越顶尖模型。在多模态能力方面,通过升级的OCRvL2技术,它在图像文字识别和格式处理上实现质的飞跃,有力支持多模态交互。DeepSeek-V3提供了两种模型下载选项,分别是DeepSeek-V3-Base和DeepSeek-V3,两者都拥有671B总参数和37B激活参数,上下文长度为128K。
据悉,DeepSeek是由幻方资本支持,这是一家使用AI来指导其交易决策的国内量化对冲基金。幻方构建了自己的服务器集群进行模型训练,最新的一个集群拥有10000个英伟达A100 GPU,耗资约一亿人民币。幻方创始人梁文峰旨在通过DeepSeek实现“超智能”AI。
 豫公网安备41010702003375号
豫公网安备41010702003375号