
Sky-T1:不到3300元,打造媲美o1预览版的推理模型
![]() 工具推荐
1736751273更新
工具推荐
1736751273更新
![]() 0
0
加州大学伯克利分校NovaSky团队推出了一款Sky-T1-32B-Preview推理模型。该模型在推理和编码基准测试中的表现与o1预览版不相上下,而且其训练成本还不到450美元(约3300元)。

当前,在推理方面极为出色的模型如o1和Gemini 2.0等,能够凭借生成较长的内部思维链等方式解决复杂任务。但是,这些模型的技术细节与模型权重并不对外开放,严重阻碍了学术和开源社区的参与。面对这一现状,不少团队积极探索,像Still-2和Journey在数学领域训练的开源权重推理模型取得了一定成果。NovaSky团队同样致力于提升基础模型和指令微调模型的推理能力,并成功让Sky-T1-32B-Preview在数学和编码领域都展现出强大的竞争力。
为推动整个社区的共同进步,NovaSky团队秉持完全开源的理念,他们将所有的细节毫无保留地开源,涵盖数据、代码、模型权重等关键内容。社区成员能够轻松在单个代码库中构建数据、训练并评估模型,同时获取用于训练的17000条数据、技术报告以及320亿参数的模型权重。
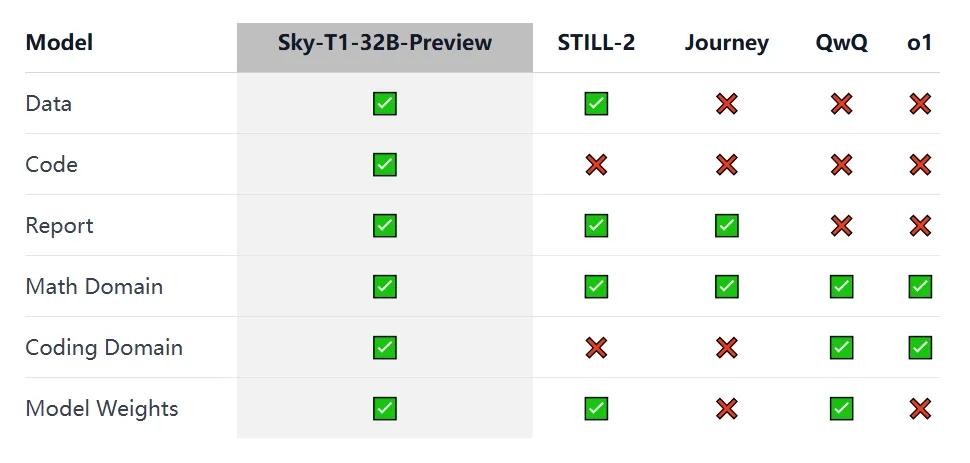
在数据整理环节,该团队使用推理能力与o1预览版相当的开源模型QwQ-32B-Preview生成训练数据。他们精心挑选数据组合,使其覆盖多个需要推理的领域,并采用拒绝采样程序提升数据质量。为了便于解析,该团队受Still-2启发,利用GPT-4o-mini将QwQ的输出痕迹重新格式化为规范版本,经过处理,模型在APPS数据集上的准确率得到了极大提升。最终,训练数据包含来自APPS和TACO的5000条编码数据、来自NuminaMATH数据集中AIME、MATH和奥林匹克竞赛子集的10000条数学数据,以及来自Still-2的1000条科学和谜题数据。
训练过程中,该团队选择对没有推理能力的开源模型Qwen2.5-32B-Instruct进行微调。模型训练3个epoch,学习率设为1e-5,批量大小为96。借助8张H100显卡和DeepSpeed Zero-3卸载技术,仅需19小时即可完成训练,成本约450美元,训练工具则选用了Llama-Factory。
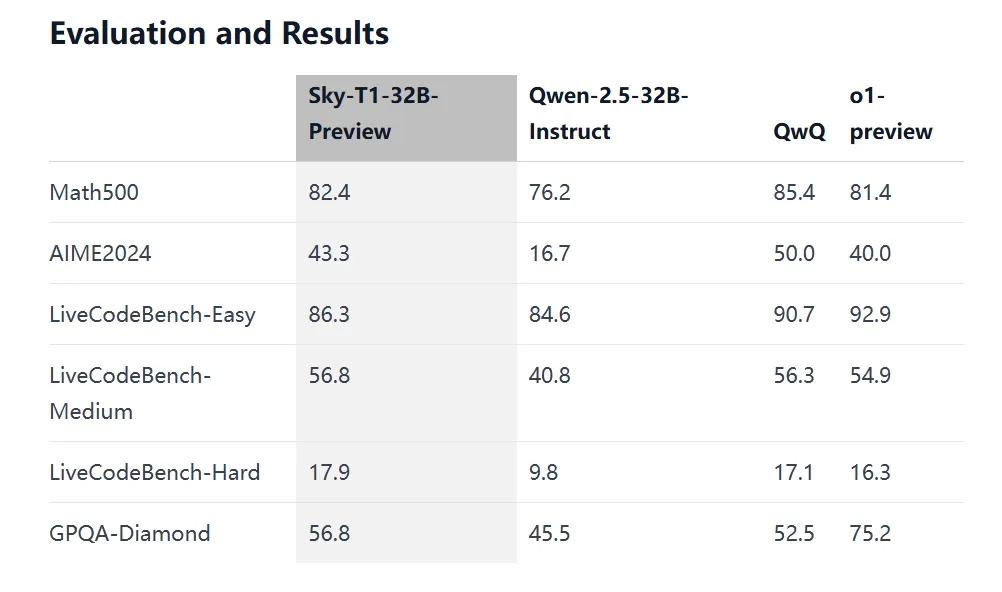
从评估结果来看,Sky-T1-32B-Preview在多个测试项目中表现优异。在Math500测试中,得分达到82.4;AIME2024测试里,准确率为43.3%;LiveCodeBench-Easy、LiveCodeBench-Medium和LiveCodeBench-Hard测试中,得分分别为86.3、56.8和17.9;在GPQA-Diamond测试中,也获得了56.8的成绩。
此外,该团队在研究过程中还发现,模型规模和数据组合对模型性能有着重要影响。较小规模的模型(70亿和140亿参数)虽然在训练后有一定性能提升,但经常生成重复内容,限制了其实际效果。而数据组合方面,单纯使用数学题训练320亿参数模型时,AIME24准确率大幅提升,但加入编码数据后,准确率反而下降。通过丰富数据类型,平衡数学和编码任务的数据比例,模型在两个领域的表现都得到了优化。
NovaSky团队表示,Sky-T1-32B-Preview模型仅仅是其探索开源推理模型的开端。未来,他们将聚焦于研发更高效且推理性能强劲的模型,并探索先进技术以提升模型在测试时的效率与准确性。
 豫公网安备41010702003375号
豫公网安备41010702003375号