
Search-o1框架:给推理模型套个“智能助手”,专治推理链条中的不确定性问题
![]() 前沿资讯
1737282809更新
前沿资讯
1737282809更新
![]() 0
0
如今,大型推理模型通过大规模强化学习,在长步骤推理方面已经表现得相当出色。这些模型在推理的时候,会像人类思考复杂问题一样,把问题一点点分解开,形成一个长长的内部推理链条,然后一步一步地找答案。
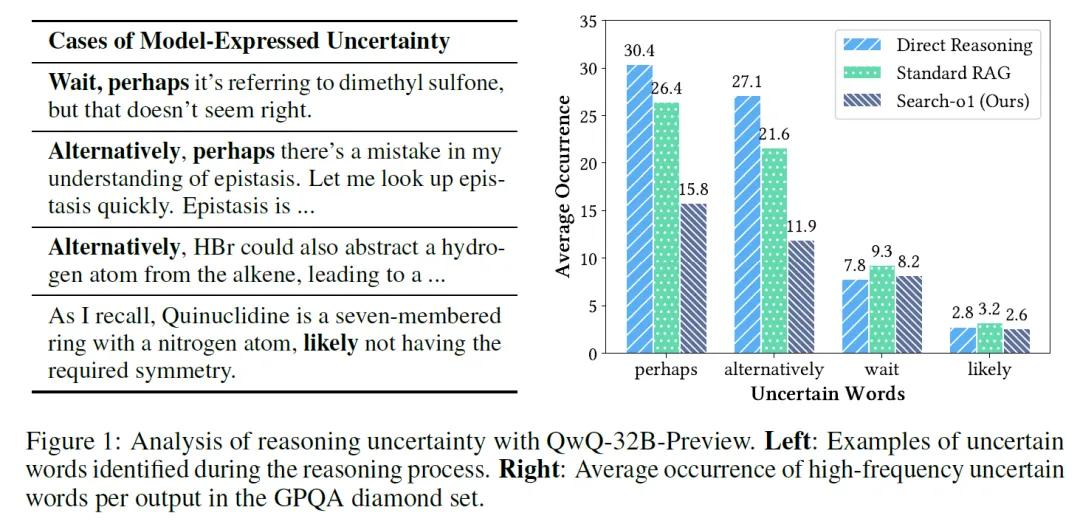
但是,当推理链条变得很长的时候,常常会碰到知识不够用的情况。如果在推理过程中某个知识点不知道,那这个错误就会像滚雪球一样,在整个推理过程中不断扩大,导致最后得出的答案完全不对。为了搞清楚这个问题有多严重,研究者们做了一些实验。他们发现,在一些很难的推理问题中,比如QwQ-32B-Preview模型,每次推理的时候,推理链条中不确定的词,如“perhaps”,平均出现次数能达到30.4。
为了解决这个问题,来自中国人民大学和清华大学的研究人员设计了一个Search-o1框架。当人类在解决难题时,如果遇到不知道的知识点,我们可能会去查资料、问朋友,Search-o1框架提供了同样的能力,当这些模型在推理过程中遇到不确定的知识点时,Search-o1能让它们主动去检索外部的知识,就像是给模型配备了一个随时可以查阅的“知识库”。
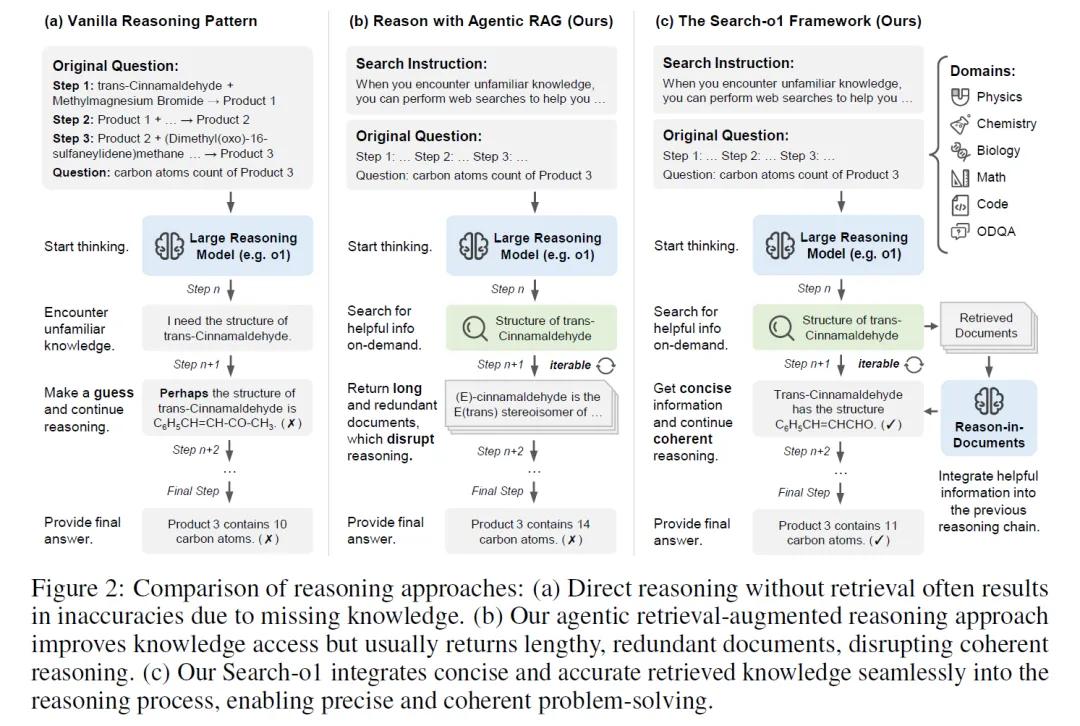
Search-o1框架中有两个核心组件。第一个是基于代理的检索增强生成(RAG)机制。这个机制就像是模型的“智能助手”,当模型在思考过程中觉得某个知识点不太确定时,这个“助手”就会跳出来,帮助模型生成一个搜索查询,然后去外部的知识库中寻找相关信息。这样,模型就可以根据找到的新知识,继续它的推理过程。
但是,仅仅找到知识还不够,因为有时候找到的信息可能会很冗长,包含很多模型并不需要的内容。这就引出了Search-o1框架的第二个核心组件——Reason-in-Documents模块。这个模块的作用就像是一个“信息过滤器”,它会对检索到的文档进行深入分析,提取出对当前推理步骤真正有用的信息,然后把这些精炼后的知识整合进模型的推理链中。这样,模型就能在保持推理连贯性的同时,利用外部知识来完善自己的推理。
在实验部分,研究人员对Search-o1框架进行了全面的测试,以评估其在复杂推理任务中的表现。这些任务涵盖了科学、数学和编程等多个领域,同时还包括了六个开放域问答基准测试。实验结果显示,Search-o1在这些任务中都展现出了卓越的性能。
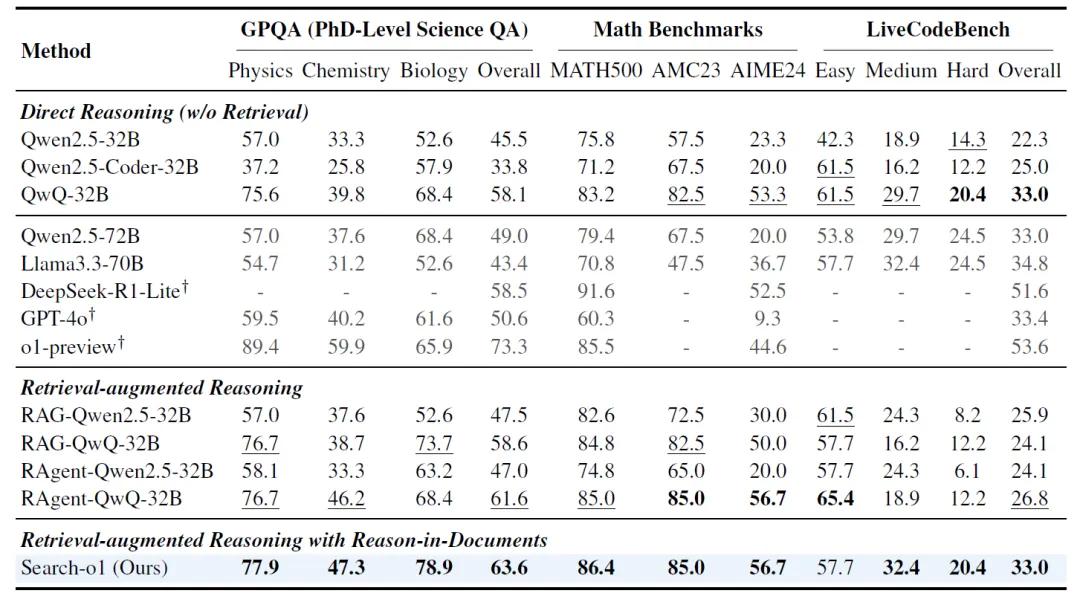
在GPQA这个博士级别的科学多项选择问答数据集上,Search-o1的通过率达到了63.6%,远超其他基线方法。在数学基准测试中,包括MATH500、AMC2023和AIME2024,Search-o1在AIME2024这个难度较高的数据集上通过率达到了56.7%,显示出其强大的数学推理能力。在编码能力基准测试LiveCodeBench中,Search-o1在中等难度问题上的通过率达到了32.4%,同样优于其他模型。
在开放域问答任务上,Search-o1也表现出色。在单跳问答数据集Natural Questions(NQ)和TriviaQA上,Search-o1的EM(Exact Match,精确匹配)值分别达到了34.0%和63.4%,而在多跳问答数据集HotpotQA、2WikiMultihopQA(2WIKI)和MuSiQue上,Search-o1的EM值更是达到了58.0%,远超其他基线方法。
此外,实验还分析了检索文档数量对Search-o1性能的影响。结果表明,随着检索文档数量的增加,Search-o1在处理复杂推理任务时的性能得到了显著提升。即使只检索一个文档,Search-o1的性能也能超过直接推理和使用十个检索文档的标准RAG模型,充分展示了基于代理的搜索和Reason-in-Documents策略的有效性。
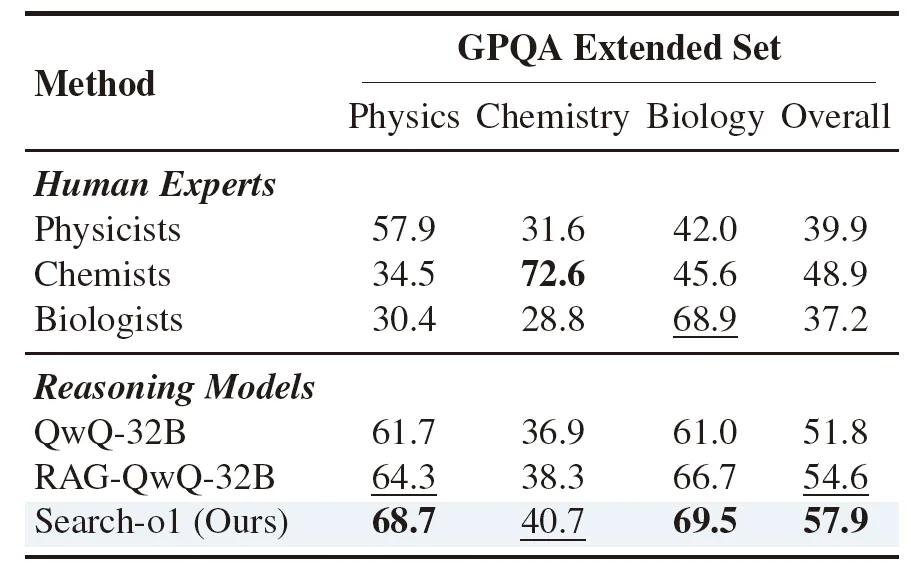
在与人类专家的比较中,Search-o1在GPQA扩展集上的整体性能超过了人类专家(57.9%),在物理(68.7%)和生物(69.5%)两个子领域的表现也优于人类专家,尽管在化学子领域稍逊于化学家(40.7% vs. 72.6%),但从多领域综合表现来看,Search-o1仍然具有很强的竞争力。
Search-o1框架的高效性和可扩展性为未来的智能系统发展提供了新的思路。它不仅能够提升现有模型的性能,还为构建更加复杂、更加智能的系统奠定了基础。该框架有望推动人工智能技术向更深层次、更广泛的应用方向发展。
 豫公网安备41010702003375号
豫公网安备41010702003375号