
DeepSeek-R1发布,英伟达高级研究科学家:一家非美国公司正在延续OpenAI的最初使命
![]() 工具推荐
1737447622更新
工具推荐
1737447622更新
![]() 2
2
近年来,大语言模型发展极为迅速,像Anthropic、Google、OpenAI等都在不断推进迭代进化,使得模型与通用人工智能之间的差距日益缩小。在模型训练的完整流程里,后训练环节变得越来越关键,它能在相对节省计算资源的情况下,提高模型在推理任务上的准确性,使其更好地符合社会价值观和用户偏好。
就拿推理能力来说,OpenAI的o1系列模型率先引入了推理时缩放的方法,通过延长思维链推理过程,在数学、编码、科学推理等诸多任务中都取得了显著进步。然而,对于研究人员而言,如何在测试时有效地进行缩放依旧是个亟待解决的难题。之前已经有不少人尝试了各种办法,像过程奖励模型、强化学习、对蒙特卡洛树搜索和束搜索等搜索算法进行研究。遗憾的是,这些方法在通用推理性能上都没能达到OpenAI o1系列模型的水平。
在这样的背景下,国内DeepSeek AI另辟蹊径,决定采用纯强化学习来提升语言模型的推理能力。他们的目标是探究语言模型在没有任何监督数据辅助的情况下,能否自主发展出推理能力,重点关注模型在纯强化学习过程中的自我进化情况。在以往的研究中,语言模型的推理能力通常依赖于大量的监督数据进行微调(Supervised Fine-Tuning,SFT)。这些监督数据虽然能够显著提升模型的性能,但其收集和标注过程往往耗时且成本高昂。此外,监督数据的依赖也可能限制模型的自主探索能力。
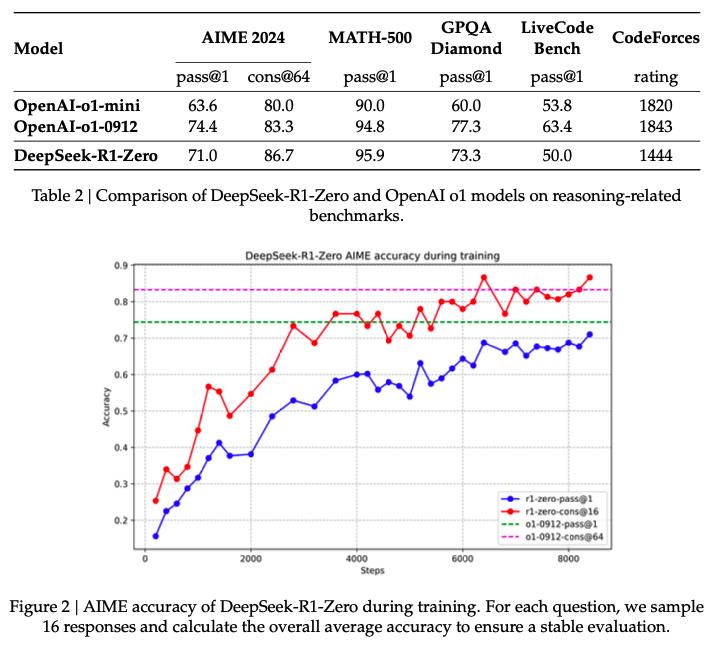
具体操作时,DeepSeek研究团队选择DeepSeek-V3-Base作为基础模型,运用GRPO作为强化学习框架,以此来提高模型在推理方面的表现。GRPO(Group Relative Policy Optimization)是一种高效的强化学习算法,可以通过优化策略模型来提升语言模型的推理能力,同时避免传统强化学习中批评者模型(critic model)带来的高计算成本。在训练DeepSeek-R1-Zero模型的过程中,出现了令人惊喜的现象,模型自然而然地产生了许多强大且有趣的推理行为。经过数千次的强化学习步骤后,DeepSeek-R1-Zero在推理基准测试中的成绩非常突出。比如在AIME2024测试中,其pass@1分数从一开始的15.6%快速提升到了71.0%,如果采用多数投票的方式,分数还能进一步提高到86.7%,能够和OpenAI-o1-0912的性能相当。
在训练过程中,DeepSeek-R1-Zero展示了显著的自我进化能力。随着训练的进行,模型逐渐学会了更复杂的推理行为,例如反思(重新评估之前的步骤)和探索多种解题方法。这些行为并非人为编程,而是模型在与强化学习环境互动中自然产生的。此外,研究者们还观察到了一个有趣的“顿悟时刻”:模型在某一阶段学会了重新评估初始解题方法,并分配更多时间进行思考。这一现象不仅展示了模型推理能力的增长,也体现了强化学习在激发模型自主探索复杂问题解决策略方面的强大潜力。
但是,DeepSeek-R1-Zero也存在一些问题,像生成内容的可读性较差,还会出现语言混合的情况。为了解决这些问题并进一步提升推理性能,该团队又开发了DeepSeek-R1。研究人员先是收集了数千条冷启动数据,用这些数据对DeepSeek-V3-Base模型进行微调,以帮助模型更好地进入强化学习阶段。之后,再按照DeepSeek-R1-Zero的训练方式进行推理导向的强化学习。当强化学习过程快要达到收敛状态时,作者利用拒绝采样的方法,结合DeepSeek-V3在写作、事实问答、自我认知等领域的监督数据,创建新的SFT数据,然后用这些新数据重新训练DeepSeek-V3-Base模型。经过这一系列操作后,得到的DeepSeek-R1模型在性能上已经能够和OpenAI-o1-1217一较高下。
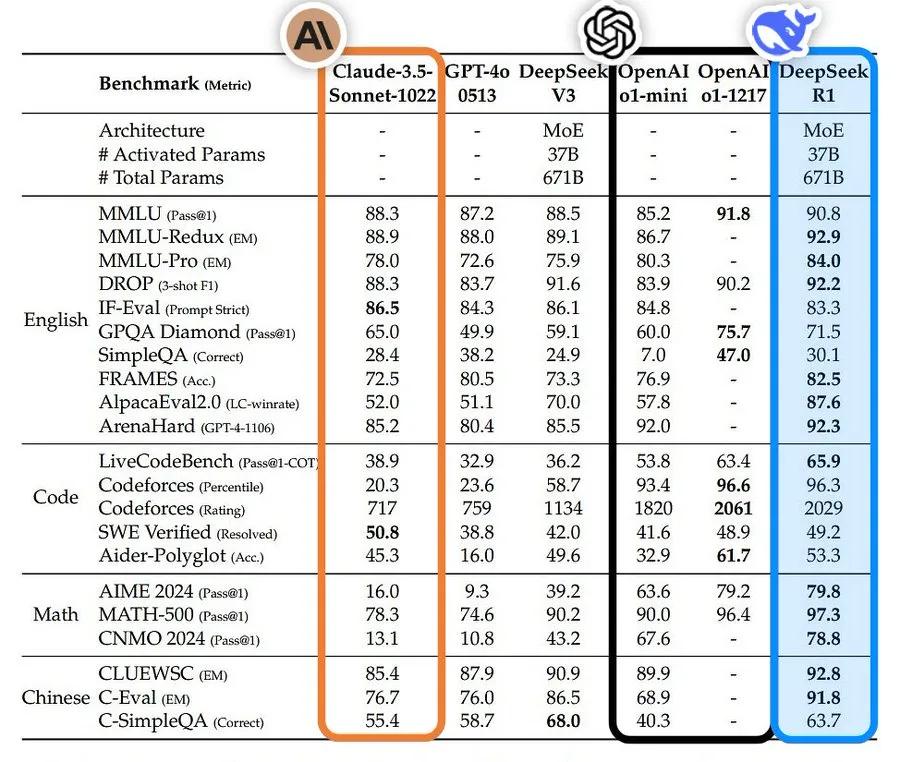
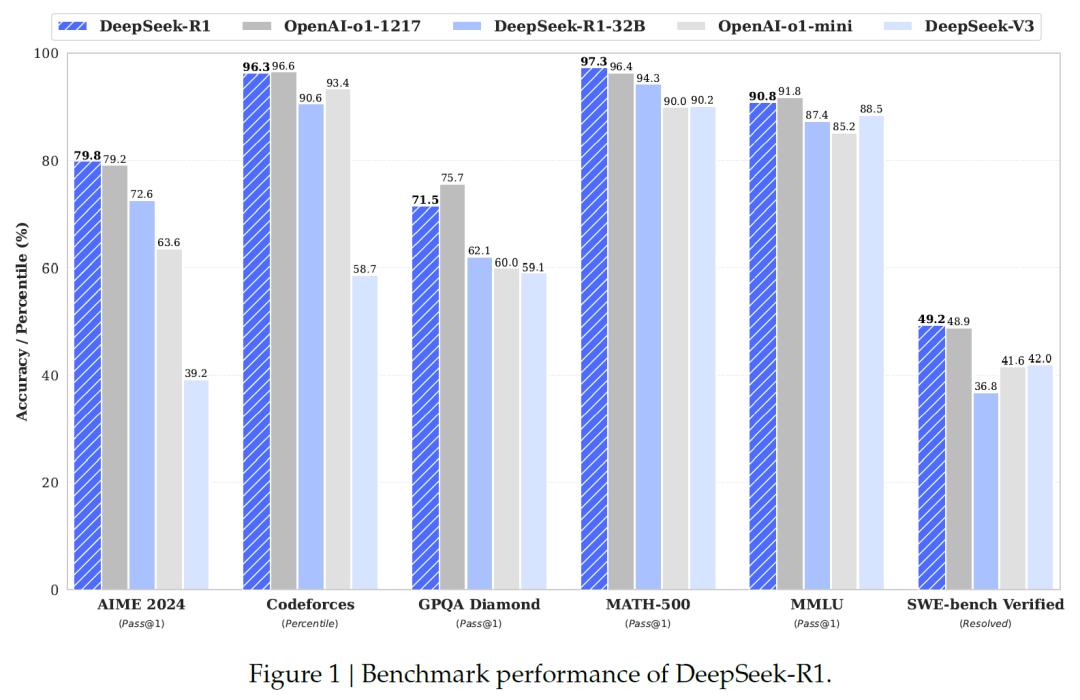
不仅如此,研究团队还进一步研究了如何将DeepSeek-R1的推理能力传递给更小的密集模型。他们以Qwen2.5-32B为基础模型进行实验,结果发现直接从DeepSeek-R1进行蒸馏得到的模型,其性能要比在Qwen2.5-32B上直接应用强化学习更好。这充分表明大模型所发现的推理模式对于提升小模型的推理能力有着极为关键的作用。
研究团队还将基于Qwen2.5和Llama系列的1.4B、7B、8B、14B、32B和70B等蒸馏模型开源,为研究社区提供了重要的资源。这些蒸馏模型在性能上表现优异,例如DeepSeek-R1-Distill-Qwen-7B在AIME2024测试中达到了55.5%的成绩,超过了QwQ-32B-Preview;DeepSeek-R1-Distill-Qwen-32B在AIME2024测试中成绩为72.6%,在MATH-500测试中达到94.3%,在LiveCodeBench测试中为57.2%,这些成绩都远超之前的开源模型,甚至能和o1-mini相媲美。

英伟达高级研究科学家Jim Fan在社交网站上评论说:“我们正处于这样一个时间线中:一家非美国公司正在延续OpenAI的最初使命——真正开放、前沿的研究,赋予所有人力量。这看似不合常理。最具戏剧性的结果往往最有可能发生。DeepSeek-R1不仅开源了一系列模型,还公开了所有训练秘诀。它们或许是首个展示强化学习飞轮实现重大且持续增长的开源项目。影响力既可以通过“在内部实现人工超级智能”或者像“草莓项目”这样神秘的名称来达成,也可以简单地通过公布原始算法和matplotlib学习曲线来实现。”
我正在阅读这篇论文:完全由强化学习驱动,根本没有监督微调(“冷启动”)。让人想起AlphaZero——从零开始精通围棋、将棋和国际象棋,而不是先模仿人类大师的走法。这是这篇论文最重要的收获。使用通过硬编码规则计算的真实奖励。避免使用任何强化学习容易被钻空子的学习奖励模型。随着训练的进行,模型的思考时间稳步增加——这不是预先编程的,而是一种涌现特性!出现了自我反思和探索行为。采用GRPO而非PPO:它从PPO中移除了评论者网络,转而使用多个样本的平均奖励。这是减少内存使用的简单方法。需要注意的是,GRPO也是DeepSeek在2024年2月发明的……多么厉害的团队。
 豫公网安备41010702003375号
豫公网安备41010702003375号