
阿里团队提出“过程奖励模型” ,可以更好的监督模型的推理过程
![]() 前沿资讯
1737538598更新
前沿资讯
1737538598更新
![]() 0
0
数学推理一直是一个极具挑战性的领域。想象一下,一个聪明的学生在解数学题时,即使最终答案正确,但推理过程可能漏洞百出,大语言模型的情况也是如此。它们在解决数学问题时可能会犯错误,比如计算失误或逻辑混乱。为了解决这个问题,阿里研究人员开发了一种名为“过程奖励模型”(Process Reward Models, PRMs)的技术,用来监督模型的推理过程,帮助它们识别并纠正错误。
过程奖励模型的作用类似于一个严格的老师,它的任务是检查语言模型在解题过程中的每一步是否正确。如果发现错误,过程奖励模型会提醒模型进行修正。这种方法的核心在于,它不仅关注最终答案是否正确,更注重解题过程的合理性。然而,开发有效的过程奖励模型并非易事,主要面临两大挑战:数据标注和评估方法。
开发过程奖励模型的第一个难题是数据标注。为了训练过程奖励模型,我们需要大量的标注数据来告诉模型哪些步骤是正确的,哪些是错误的。但标注这些数据非常耗时且成本高昂。因此,研究人员尝试用自动化方法来生成标注数据,其中一种常用的方法是蒙特卡洛(Monte Carlo, MC)估计。
蒙特卡洛估计的原理听起来很巧妙:通过模拟多个可能的未来步骤,来判断当前步骤是否有可能导致正确答案。然而,这种方法有一个致命的缺陷就是它依赖于语言模型自身的性能。如果模型本身就不够可靠,那么它可能会从错误的步骤中得出正确答案,或者从正确的步骤中得出错误答案。这就导致了标注数据的不准确,进而影响了过程奖励模型的训练效果。研究人员在实验中发现,使用MC估计训练的过程奖励模型在识别错误步骤方面表现不佳,尤其是在复杂的数学问题上。
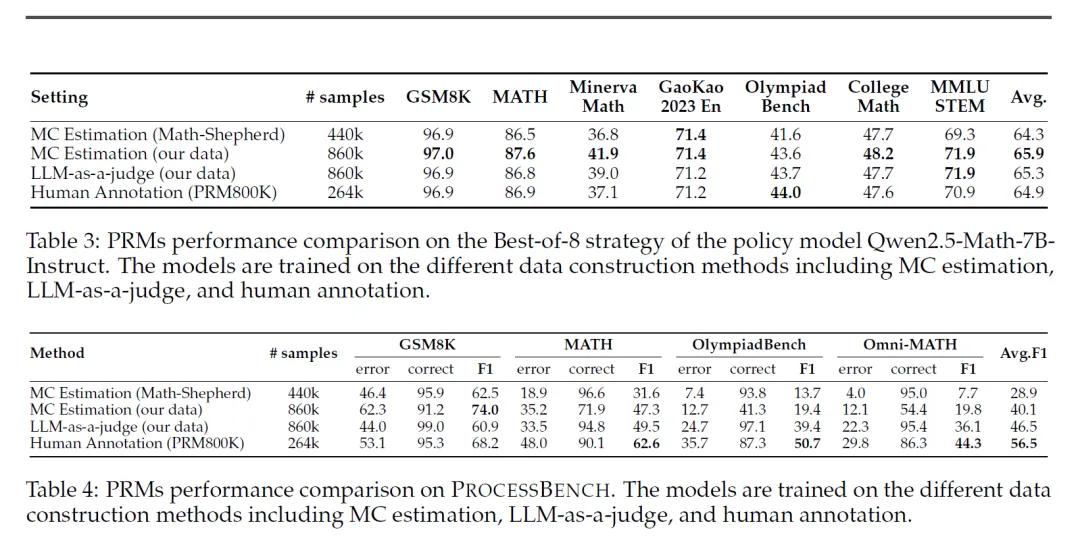
为了解决这个问题,研究人员提出了一种新的方法:融合用大型语言模型作为裁判“LLM-as-a-judge”和MC估计。具体来说,他们让一个强大的语言模型(比如Qwen2.5-72B-Instruct)来判断每个步骤的正确性,并与MC估计的结果进行对比。只有当两种方法都一致认为某个步骤是错误的时候,才会保留这个标注数据,这种方法被称为“共识过滤机制”。
经验证,共识过滤机制的效果非常显著。虽然经过过滤后数据量减少了,但数据的质量和一致性得到了极大提升。实验结果显示,经过共识过滤的过程奖励模型在识别错误步骤方面的能力大幅增强,甚至超过了仅使用MC估计或LLM-as-a-judge单独训练的模型。
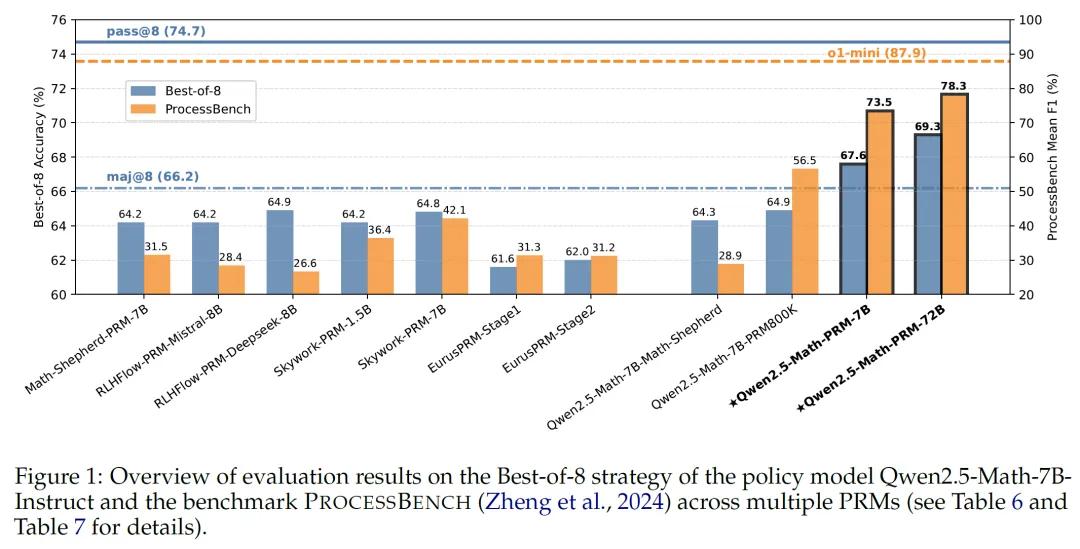
开发过程奖励模型的第二个挑战是评估方法。以往的研究主要使用“最佳N选1”(Best-of-N)策略来评估过程奖励模型的性能。这种方法的原理是从N个候选答案中选择得分最高的一个,但它的局限性在于只关注最终答案,而忽略了推理过程。这就导致了一个问题:即使模型的推理过程是错误的,只要最终答案正确,它仍然会被认为是好的答案,这种评估方式显然与过程奖励模型的初衷背道而驰。
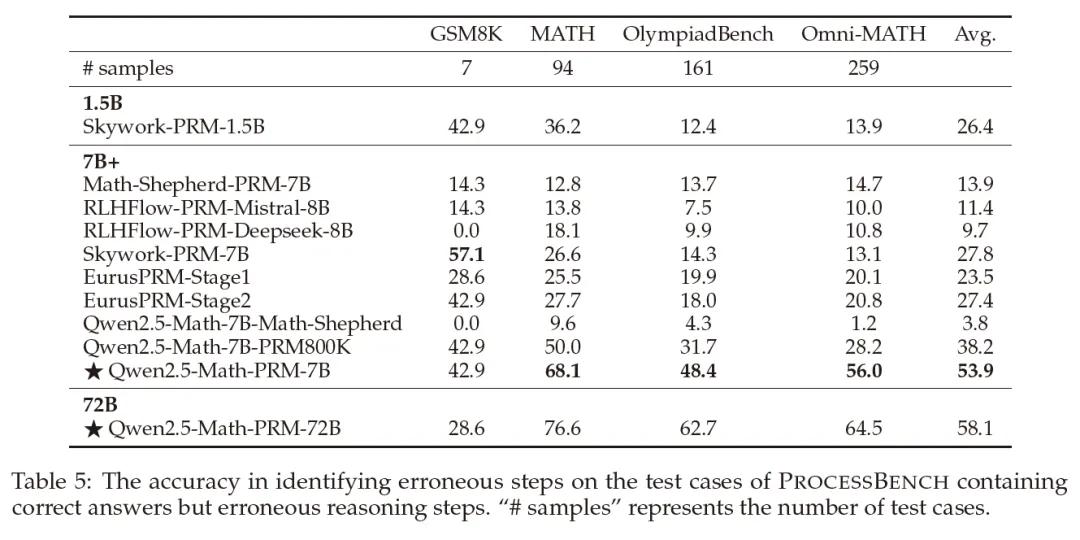
为了更全面地评估过程奖励模型的性能,研究人员引入了一个新的基准测试:PROCESSBENCH。PROCESSBENCH要求模型不仅要判断最终答案是否正确,还要识别推理过程中的第一步错误在哪里,这种方法更加注重推理过程的合理性,能够更准确地评估过程奖励模型的能力。
通过结合Best-of-N和PROCESSBENCH的评估结果,研究人员发现了一个有趣的现象:一些在Best-of-N评估中表现良好的过程奖励模型,在PROCESSBENCH中却表现不佳,表明这些模型虽然能够生成正确的答案,但它们的推理过程并不总是可靠的。而经过共识过滤训练的过程奖励模型则在这两种评估中都表现出色。
通过共识过滤机制和全面的评估框架,研究人员成功开发了一个新的PRM模型:Qwen2.5-Math-PRM。这个模型在Best-of-N和PROCESSBENCH评估中都取得了优异的成绩,优于现有的其他开源模型。这一成果不仅为数学推理领域带来了新的突破,也为未来的研究提供了宝贵的指导。
 豫公网安备41010702003375号
豫公网安备41010702003375号