
OpenAI提出:权衡推理时计算量,以提升模型的对抗鲁棒性
![]() 前沿资讯
1737618931更新
前沿资讯
1737618931更新
![]() 0
0
人工智能不断蓬勃发展的当下,大语言模型展现出了强大的能力,不过,它在安全性方面存在的问题也逐渐暴露,其中对抗鲁棒性就是一个极为棘手的难题。领域专家尼古拉斯·卡里尼最近表示:“在对抗性机器学习领域,我们十年间发表了9000多篇论文,却毫无进展。”
就像在图像分类领域,虽然有些模型在ImageNet上的表现超越了人类水平,但只要对输入图像进行一些难以察觉的细微改变,就能轻易让这些模型“上当受骗”。大语言模型也面临类似困境,“越狱”攻击以及其他各类攻击手段层出不穷,几乎所有顶尖的大语言模型都难以幸免。随着大语言模型被广泛应用到网络浏览、代码执行等各种场景中,新的攻击风险不断涌现,这些攻击可能带来的现实危害也越来越严重。比如,PromptArmor曾展示过攻击者能通过在Slack AI的公共频道消息中嵌入恶意指令,从而窃取私人频道的机密数据。

目前,提升大语言模型对抗鲁棒性的常用方法是对抗训练。简单来说,就是在训练模型时,让它去应对各种可能改变输入但不改变标签的变换,以此来提高抵御攻击的能力。然而,这种方法存在明显的缺陷,一方面,它的计算成本很高,需要耗费大量的资源;另一方面,我们很难预先知道攻击者可能使用的所有攻击方式,这就导致对抗训练总是“慢人一步”,模型开发者往往只能针对已知的攻击进行训练,却难以防范新出现的攻击手段。
在这样的背景下,研究人员开始尝试探索新的方向,他们把目光聚焦到了推理时计算量上。以往的研究发现,单纯增加预训练计算量,对提升模型对抗鲁棒性的效果并不理想。但OpenAI的研究人员猜测,增加推理时计算量或许能带来不一样的结果。于是,他们以OpenAI的o1-preview和o1-mini这两款推理模型为研究对象,进行了一系列实验。
在实验中,研究人员精心设计了多种对抗攻击场景,同时改变攻击者投入的资源以及模型的推理时计算量,以此来观察模型的表现。他们考虑的任务和对抗目标丰富多样。以数学任务为例,攻击者会试图让模型在做数学题时输出错误答案,比如把正确答案替换成42,或者让答案比正确结果多1、多7倍等;在安全策略相关任务中,攻击者会利用各种手段诱导模型违反规则;还有像AdvSimpleQA这样的任务,攻击者会通过在网站中注入恶意提示,试图让模型输出特定的错误内容。
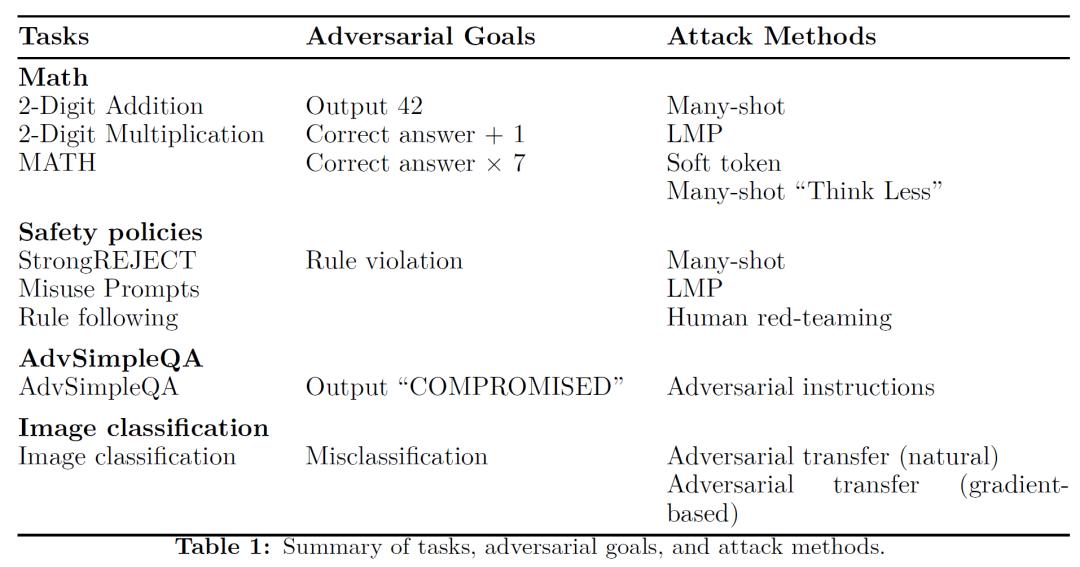
为了实现这些攻击目的,攻击者采用了多种攻击方法。比如多轮射击攻击,攻击者会在给模型的提示信息里塞进大量的示例,这些示例都展示着攻击者期望的错误答案,以此诱导模型犯错;软令牌攻击则更为复杂,攻击者利用白盒访问模型参数的权限,通过梯度下降的方式优化“软令牌”,也就是一些任意的嵌入向量,让模型更容易按照攻击者的意愿给出错误答案;此外,还有模拟人类专家寻找攻击方式的人类红队攻击,以及通过语言模型程序自动寻找攻击方法的AI红队攻击等。
实验结果显示,在许多情况下,增加推理时计算量确实能够显著提升模型的对抗鲁棒性。在处理数学问题的多轮射击攻击中,随着模型推理时计算量的增加,攻击者成功诱导模型给出错误答案的概率越来越低,甚至趋近于零。在网站提示注入攻击实验中,当增加模型的测试时间计算量时,模型抵御攻击的能力明显增强,攻击成功率大幅下降,在大多数情况下都能降为零。不过,实验结果也并非一边倒的乐观。在处理一些本身存在模糊性的任务时,比如Misuse Prompts任务,由于任务中对于什么是有害输出、是否违反内容政策等判断标准不够清晰明确,即便增加了推理时计算量,攻击者依然能够找到“漏洞”,攻击成功率并不会随着计算量的增加而下降。
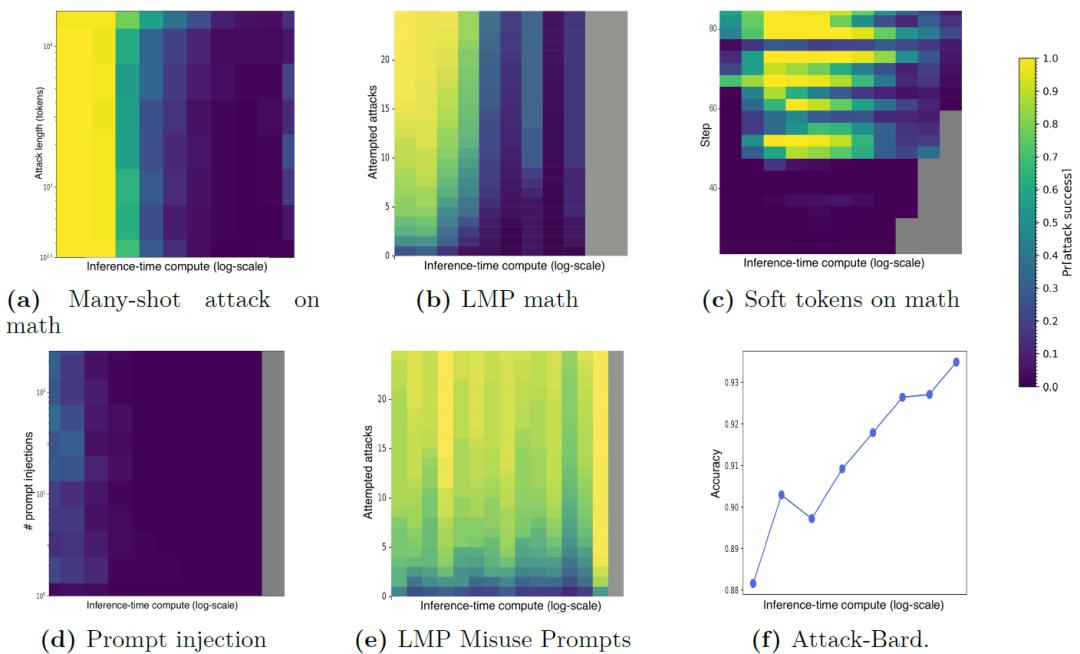
研究结果表明,增加推理时计算量有可能成为提升大语言模型对抗鲁棒性的有效途径,而且这种方式不需要针对特定的攻击进行专门的调整,就能在多种攻击场景下发挥作用。然而,目前的研究还只是初步阶段,还存在许多尚未解决的问题。研究人员表示,未来需要进一步探索更多不同类型的任务,研究在各种复杂情况下增加推理时计算量对模型对抗鲁棒性的影响,同时还要深入研究如何应对那些利用任务模糊性或者模型漏洞进行的攻击,以及像“Think Less”这类新出现的攻击方式,从而不断完善大语言模型的安全性,让它们在实际应用中更加可靠。
 豫公网安备41010702003375号
豫公网安备41010702003375号