
谷歌推出COA框架,利用智能体协作来攻克长文本任务
![]() 工具推荐
1737707161更新
工具推荐
1737707161更新
![]() 2
2
当下,大语言模型展现出了强大的能力,在众多场景中都有出色表现。但遇到涉及长文本的任务时,它们就显得力不从心。像问答、文档总结、代码补全等任务,常常需要处理整本书籍、长篇文章的内容,对些模型来说是个不小的挑战。
为了解决大语言模型处理长上下文任务的难题,目前主要有两种常见策略。一种是减少输入长度,比如通过检索增强生成(RAG),它能检索出相关的文本片段,但检索准确率不高,可能导致大语言模型获取的信息不完整,影响任务结果。另一种是扩大模型的上下文窗口限制,然而窗口变长后,模型又难以聚焦在解决任务所需的关键信息上,出现“中间迷失”等问题。
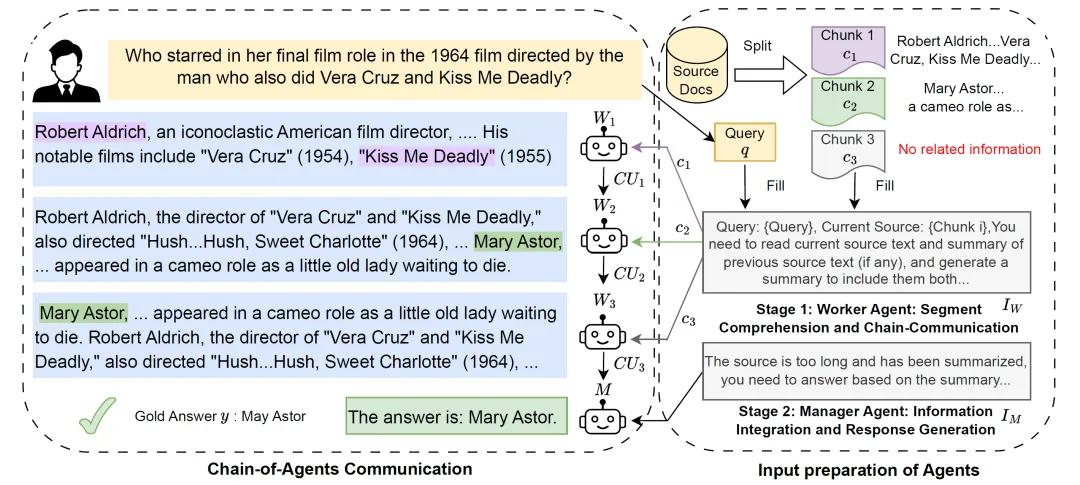
针对这些问题,谷歌研究人员提出了一种全新的框架:Chain-of-Agents(CoA),该框架的灵感来源于人类在有限大脑工作记忆下处理长文本的方式。CoA由多个worker agent和一个manager agent组成。在处理任务时,长文本会先被分成多个片段,worker agent依次处理这些片段,每个worker agent会接收前一个agent传递的信息,并把处理后的有用信息传递给下一个agent。经过多个worker agent的协作,最后由manager agent整合所有信息,生成最终的答案。
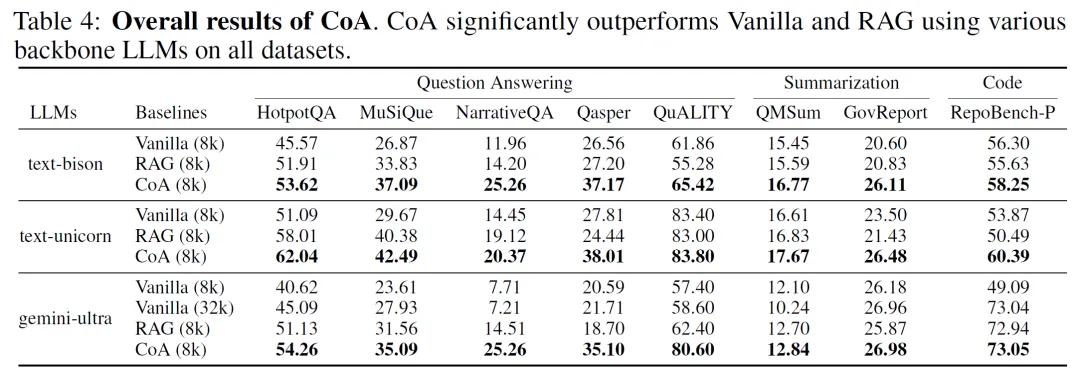
为了验证CoA的效果,研究人员进行了大量实验。他们选择了九个包含不同长上下文任务的数据集,涵盖问答、总结和代码补全领域,使用了包括PaLM 2、Gemini 1.0、Claude 3等在内的六种模型作为基础模型。实验中,CoA与两种强大的基线方法进行对比:一种是直接将所有输入喂给模型的Full-Context方法;另一种是RAG方法。结果令人惊喜,CoA在所有数据集上都表现出色,比基线方法有显著提升,最高可提高10%的性能。
研究人员还对CoA进行了深入分析。他们发现,当RAG无法检索到正确答案时,CoA能大幅提升性能;当输入文本更长时,CoA的优势更加明显;CoA还能有效缓解“中间迷失”现象,通过多智能体协作实现复杂的长上下文推理。此外,消融实验表明,manager agent在CoA中起着至关重要的作用,并且从左到右的阅读顺序效果最佳。
研究人员也指出了它的一些局限性。例如,当前模型的通信效率还有提升空间,可以通过微调或上下文学习来改进;CoA目前还没有探索像辩论或复杂讨论这样的通信方式;运行CoA的成本和延迟也可以进一步降低。未来的研究可以朝着这些方向努力,让CoA变得更强大、更高效。CoA为解决长上下文任务提供了一种创新且有效的方法,它简单易用、可解释性强,还能降低成本。这一框架为语言模型在长文本处理领域的应用开辟了新的道路。
 豫公网安备41010702003375号
豫公网安备41010702003375号