
Meta发布VideoJAM框架,生成的体操运动终于不再“鬼畜”
![]() 工具推荐
1738743550更新
工具推荐
1738743550更新
![]() 1
1
在视频生成领域,很多模型生成的运动视频总是不尽人意。比如,让模型生成一个体操运动员动作的视频,生成的画面里往往会出现运动员肢体变形、多胳膊少腿这种奇怪情况;在生成一个人转呼啦圈的视频中,可能会出现呼啦圈直接穿过人体的现象,这明显不符合现实中的物理规律;还有旋转运动,比如一个人转手中的小玩具,生成的画面也很难把简单的重复转动动作表现好,看起来特别不连贯。就连慢跑这样常见的运动,生成的视频里也会出现一些奇怪的问题,比如跑步的人老是用同一条腿迈步。
为什么会这样的鬼畜场景?经研究发现,问题出在模型的训练目标上。通常模型训练的时候,通过对比生成的视频和原始视频之间的差异来计算损失,这个差异主要基于像素来衡量,这就导致模型更关注视频的外观特征,像颜色、纹理这些,因为这些对像素差异的影响比较大。而像运动的动态变化、物理规律这些时间信息,对像素差异的贡献比较小,模型就不太重视,所以生成的视频运动就不连贯。研究人员做了个实验,他们把一段视频的帧顺序打乱,然后和正常的视频一起输入到模型里,看看模型的反应。结果发现,模型几乎没办法区分这两个视频,它根本没察觉到视频的时间顺序已经被打乱。
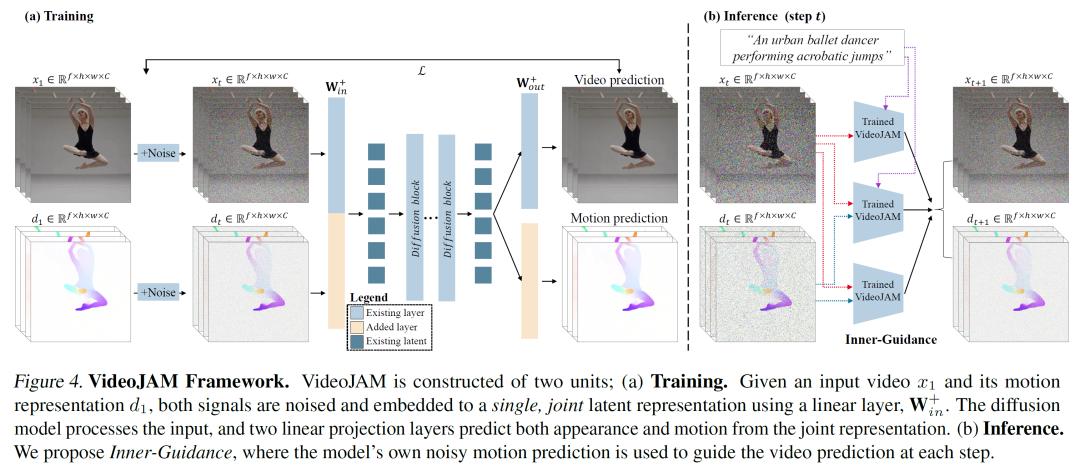
针对这些问题,Meta研究人员提出了一个叫做VideoJAM的新框架,这个框架主要做两件事。
在训练的时候,它让模型学习一种既能表示视频外观又能表示运动的联合表示。他们给模型添加了两个线性层,一个在输入的时候把视频和运动的信息融合成一个统一的表示,另一个在输出的时候从这个统一表示里提取出运动预测。这样一来,模型的训练目标就变成了预测联合外观-运动分布,让模型更加依赖添加的运动信号。
在推理阶段,也就是模型生成视频的时候,研究人员提出了Inner-Guidance这个机制。因为直接把运动预测作为辅助信号输入到模型里,并不能保证模型一定会按照这个信号来生成连贯的运动。所以,Inner-Guidance通过修改扩散模型的采样分布,把模型自己预测的运动作为一个动态的引导信号,让模型在生成视频的时候更倾向于生成符合运动规律的画面。
为了验证VideoJAM的效果,研究人员做了很多实验。他们找了多个开源和商业模型来和VideoJAM进行对比,同时,他们还专门构建了两个基准测试,一个叫VideoJAM-bench,用来测试视频运动连贯性;另一个是Movie Gen,用来进一步验证结果的可靠性。在实验中,研究人员不仅用一些自动评估指标来衡量,还使用了很多人工来对生成的视频进行评价。
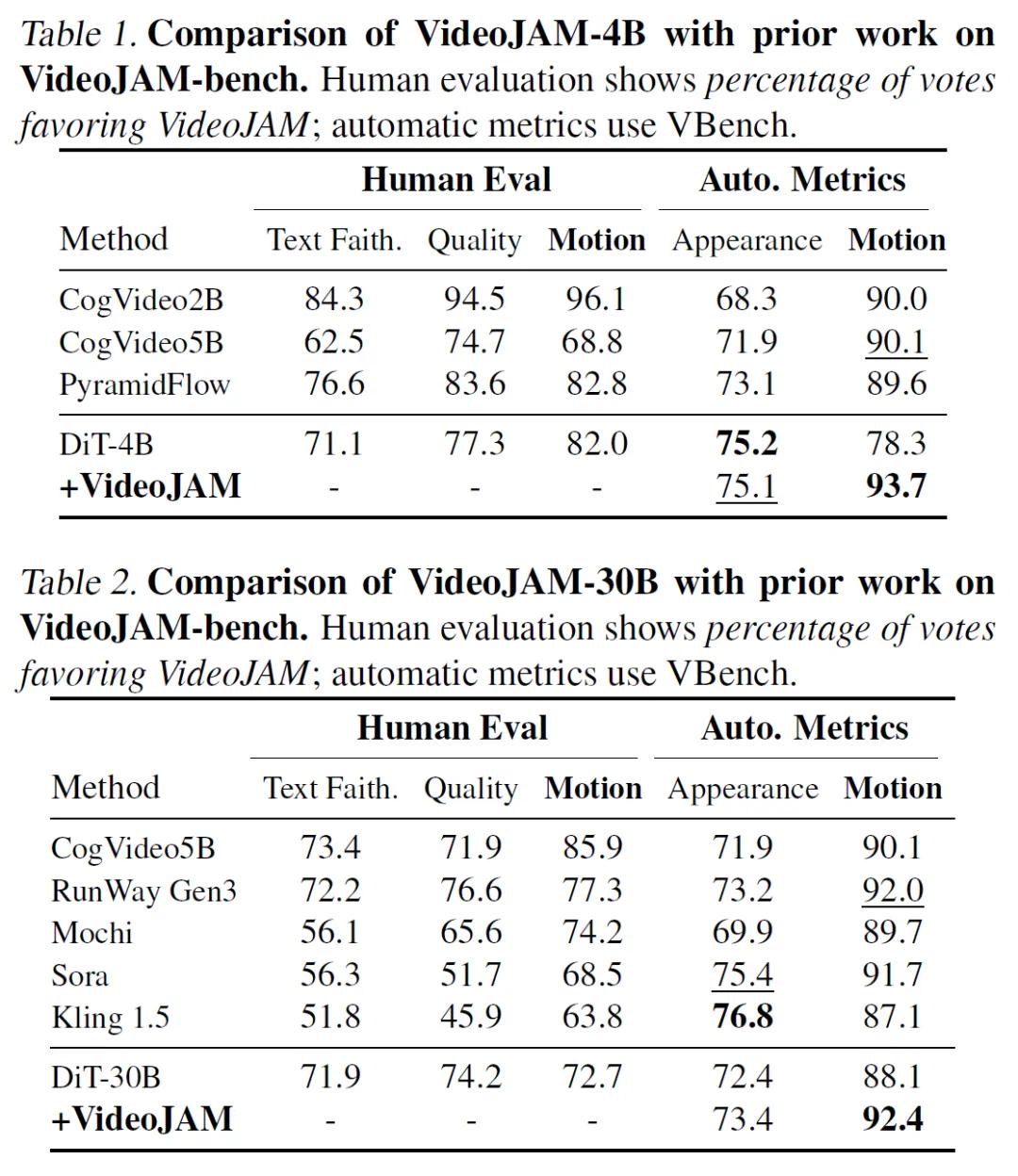
实验结果显示,VideoJAM的效果特别好。不管是与小模型还是大模型相比,它都能显著提高视频的运动连贯性。普通模型在处理基本运动、复杂运动还有物理相关的运动时,都会出现各种各样的问题,比如运动方向错误、动作不自然、违背物理规律等,而VideoJAM生成的视频,运动更加连贯,也更符合物理规律。在自动评估指标和人工评价中,VideoJAM在运动连贯性方面都远远超过了其他模型,就算是和它所基于的基础模型(DiT-4B和DiT-30B)相比,也有很大的提升。
不过,VideoJAM也存在一些局限性。由于计算资源的限制,VideoJAM在训练的时候分辨率不高,而且用的运动表示是RGB格式,当画面里的运动物体占比很小的时候,会导致模型很难捕捉到运动信息。另外,VideoJAM在运动表示上虽有改进,但还是缺乏对物理规律的明确编码,所以在处理复杂的物体交互时也会有困难,比如在表现足球运动员踢球时,运动员的脚和球接触的瞬间,模型可能处理得不太准确。
VideoJAM框架为解决视频模型运动生成的问题提供了新的思路和方法。它通过让模型学习联合外观-运动表示,以及在推理时使用Inner-Guidance机制,有效地提高了视频的运动连贯性。虽然还有一些局限性,但它为未来视频模型的发展开辟了新的方向,让我们离生成更加真实、连贯的视频又近了一步。
参考资料:https://arxiv.org/abs/2502.02492
 豫公网安备41010702003375号
豫公网安备41010702003375号