
DeepSeek背后的工程技术揭秘
![]() 前沿资讯
1738827615更新
前沿资讯
1738827615更新
![]() 0
0
随着人工智能技术的快速发展,各大研究机构和企业争相推出更高效、更强大的语言模型。来自DeepSeek的R1推理模型,更是引发了全球性的关注。R1的性能已经可与OpenAI的o1和Google的Flash 2.0等顶级模型媲美,并且训练成本仅为这些科技巨头的一小部分。通过《YC Decoded》节目的深入剖析,我们可以发现DeepSeek是如何在硬件资源有限的情况下推动其模型达到顶尖水准。

要理解R1的技术优势,首先需要从其基础模型V3开始。DeepSeek V3是去年12月发布的一款通用大语言模型,其通过几项关键技术优化不仅显著提升了训练效率,还大大降低了训练成本。
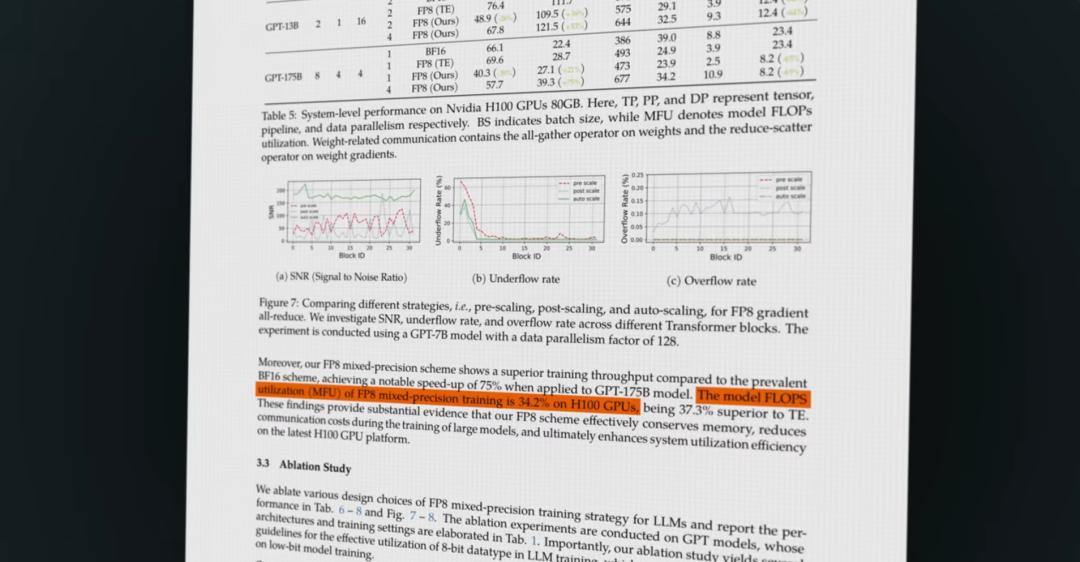
DeepSeek采用了8位浮点数(FP8)格式来进行原生训练,而传统的语言模型通常使用16位甚至32位浮点数。这种选择不仅节省了显存资源,还提高了训练期间的硬件利用率。然而,FP8计算不可避免地会带来数值误差。为了克服这一问题,DeepSeek提出了FP8累加修正技术,定期将计算结果合并回更高精度的FP32累加器中,从而防止小误差在计算过程中逐步放大。这种方法在保证模型性能的同时,极大地减少了计算所需的资源使用。
另一个值得关注的创新点是V3使用了混合专家架构。在传统模型中,每次预测都会激活所有的参数,而V3仅激活了需要的部分参数。例如,V3总共有6710亿参数,但一次预测中通常只会激活370亿参数。相比之下,Meta的LLaMA 3最大模型具有4050亿参数,但每次预测过程中需要激活全部参数。这种设计使得V3每次预测所需的计算量减少了11倍,而在性能上几乎没有明显的损失。
混合专家架构凭借其灵活的参数调度大幅减少了计算成本,但其训练过程往往因不稳定性而难以优化。为此,DeepSeek开发了一些新的技术手段来稳定模型的性能并提高训练效率。
深度学习模型中,注意力机制是计算资源的主要消耗点,而存储键值对(Key-Value Cache,简称KVCache)通常是显存占用的主要瓶颈。为了解决这一问题,DeepSeek在V2模型中首次提出了多头潜在注意力(MLA)技术,并在V3中充分利用。MLA将键值对压缩成潜在表示,仅在需要时才重新解压或计算。这使得KV Cache的存储需求减少了93.3%,同时生成效率提升了5.76倍。
另一项关键创新是多标记预测(MTP)。传统语言模型每次预测下一个单个Token,而MTP则能够一次性预测多个后续Tokens。这种方式不仅增加了训练信号的密度,也提供了更快的学习速度和数据效率。这种改进对推理阶段尤为重要,使得模型的生成过程更加连贯、流畅。
通过以上这些技术改进,DeepSeek V3成为当前市场上效率最高、性能最强的基础模型之一。

如果说V3是DeepSeek的基础,那么R1则是一次具有里程碑意义的扩展。R1专注于复杂问题的推理能力,这正是大多数传统大语言模型的弱点。
DeepSeek的R1模型与OpenAI的o1类似,主要依靠强化学习技术来专门训练模型的推理能力。在传统语言模型中,添加“逐步思考”(step-by-step reasoning)提示可以临时提高它们的逻辑推理能力,而推理模型则从根本上优化了这方面的技能,使得模型能够系统性地分解难题,并整段整段地推理。
与OpenAI等实验室较为复杂的强化学习方法不同,DeepSeek选择了一种极简化的方法。他们的训练流程并未使用大量的人类反馈或示例,而是设计了一套规则通过评分模型的输出质量(例如答案是否正确)来指导训练。这种方法基于DeepSeek于2024年2月在其数学论文中提出的“群体相对策略优化”(GRPO)技术。
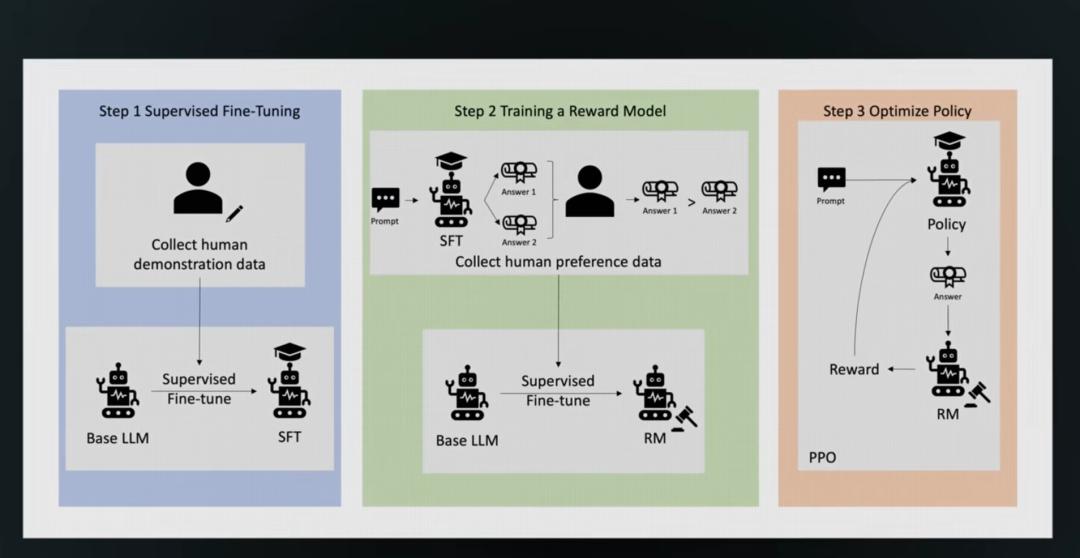
这个过程令人惊讶地看到了推理能力的自然涌现。在数千步强化学习过程中,R1的前身R10学会了链式推理(chain-of-thought),甚至它还在某些任务中表现出“顿悟”的特性,能够识别并修正自己的错误。
虽然GRPO在推理能力上表现出色,但最初版本的R10在输出过程中会随机混用中文和英文,导致其可读性较差。为了改进模型的表现,DeepSeek在强化学习前加入了冷启动训练阶段,使用结构化推理示例微调模型。这一策略使得R1的语言输出变得更加连贯,同时降低了用户接触模型时的学习门槛。
这套高效的技术策略让DeepSeek在资源受限的环境下成功实现了全球领先的推理能力。由于面临美国对高端GPU出口的限制,DeepSeek必须通过软件和算法的方式最大化现有硬件资源的利用率。例如,通常GPU集群在浮点数计算中大约只有35%的峰值利用率,而其余时间用来等待数据在缓存或集群间传输。DeepSeek通过FP8计算、MLA和混合专家等技术提升了GPU的利用效率,这对于硬件资源有限的公司和地区意义重大。
在大模型训练成本愈发高昂的今天,DeepSeek开创了一条强调算法优化和效率优先的新路径。他们引发的产业讨论远不止于技术本身,其发布的开源模型为开发者提供了一种低成本复现的可能性。例如,美国加州大学伯克利分校的一组研究人员仅花费30美元,便成功复现了DeepSeek的R10技术,并生成了在小规模模型上的复杂推理能力。
DeepSeek的成功展示了一种全新的研发范式:在硬件受限的条件下,通过极致优化与创新思路突破技术瓶颈。DeepSeek在V3和R1模型上的技术积累证明了开源和透明性同样能够推动前沿科技的发展。
这一切表明,人工智能领域仍然有极大的创新潜力可供挖掘,而新兴玩家依然有机会借助独特的技术路径改变行业格局。对于开发者和创业者而言,这是一个极佳的时代:训练成本正逐渐下降,开源工具不断丰富,模型的性能瓶颈也在新的优化方式下被打破。DeepSeek所带来的不止是一次技术风潮,也是对行业未来创新更多可能性的激励。这正是AI世界最激动人心的地方:变革仍在继续,机会就在眼前。
 豫公网安备41010702003375号
豫公网安备41010702003375号