
小红书开始发力!70亿参数Vision-R1大放异彩,推理能力直逼OpenAI o1
![]() 前沿资讯
1741674012更新
前沿资讯
1741674012更新
![]() 0
0
增强语言模型的复杂推理能力一直是人工智能领域的重大挑战,也是迈向通用人工智能(AGI)的关键路径。在多模态语言模型领域,虽然已有研究探索了思维链(CoT)推理的应用,但由于缺乏自然的人类认知过程,如质疑、反思和检查,这些方法在复杂视觉推理任务上的表现仍不尽如人意。

受DeepSeek-R1通过强化学习成功诱导大语言模型自涌现复杂认知推理能力的启发,华东师范大学和小红书的研究研究人员试图探索强化学习在提升多模态大语言模型推理能力方面的潜力。然而,直接使用强化学习训练多模态大语言模型面临诸多困难,如缺乏大规模高质量的多模态数据,难以有效激活模型的复杂推理能力。另外,研究人员发现,直接应用强化学习时,模型很难生成冗长、复杂的CoT推理,并且随着训练时间的延长,模型虽然会尝试使用更长的推理过程来解决难题,但这反而会导致性能下降。
为解决这些问题,研究团队提出了推理型多模态大语言模型:Vision-R1,其核心在于将冷启动初始化与强化学习训练相结合。研究团队利用现有多模态大语言模型和DeepSeek-R1,通过模态桥接和数据过滤的方法,构建了一个包含20万个样本的高质量多模态CoT数据集Vision-R1-cold dataset,该数据集无需人工标注,且模拟了人类的认知行为,为Vision-R1提供了冷启动初始化数据。

针对冷启动初始化后模型出现的过度思考优化问题,即正确推理过程集中在较短的CoT推理序列,研究团队提出了渐进式思维抑制训练(PTST)策略,并结合组相对策略优化(GRPO)和硬格式化结果奖励函数,引导模型在强化学习过程中逐步学习正确和复杂的推理过程。
实验结果显示,Vision-R1在多个多模态数学推理基准测试中表现卓越。在广泛使用的MathVista基准测试中,70亿参数的Vision-R1-7B模型准确率达到73.5%,仅比领先的推理模型OpenAI o1低0.4%。在复杂数学推理子任务上,Vision-R1-7B的几何推理、代数推理和几何问题解决得分分别为80.3%、79.0%和83.2%,平均准确率比基础模型Qwen-2.5-VL-7B提高了10%以上。在更具挑战性的MathVerse和MM-Math基准测试中,Vision-R1-7B分别排名第一和第二。其中,在MathVerse测试中,Vision-R1-7B展现出了类似人类的质疑和自我反思思维过程,在推理过程中会对自己的思路进行检查和修正(“Aha moment”),有效提升了其在复杂数学问题上的解题能力。
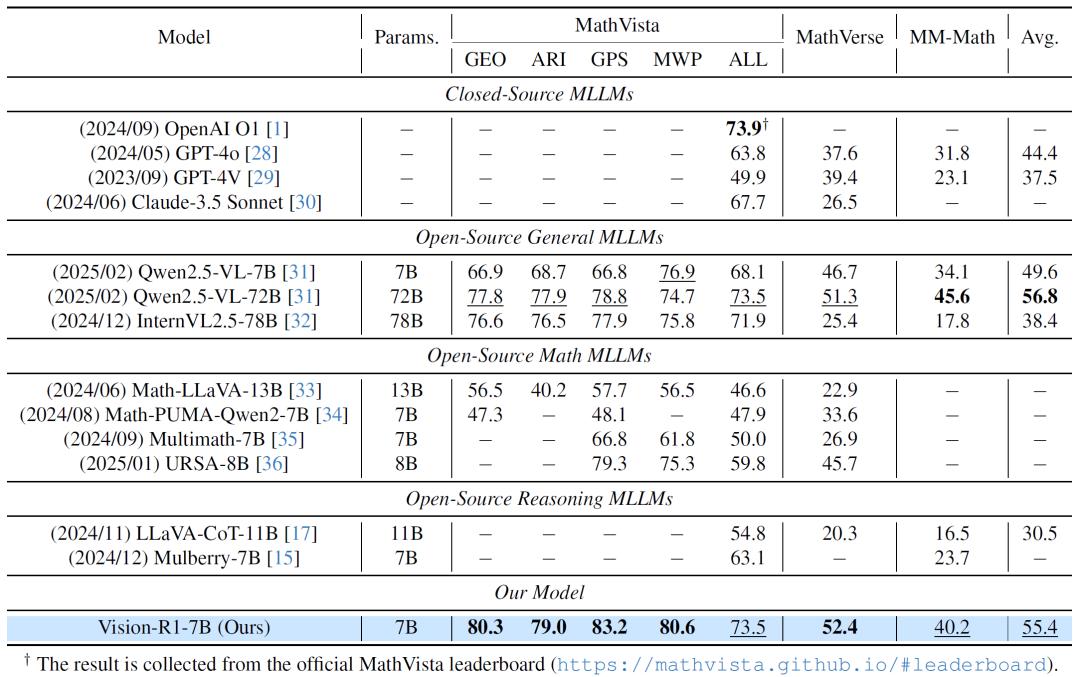
此外,对Vision-R1-cold数据集的质量分析表明,该数据集包含了比以往多模态CoT数据集更高比例的人类认知过程,有效提升了模型的泛化能力。消融实验也证明了Vision-R1在平衡CoT复杂性和准确性方面的显著优势。研究团队表示,此次研究成功提升了多模态大语言模型的推理能力,他们将继续探索如何进一步优化模型,推动多模态大语言模型在更多复杂任务中的应用。
参考资料:https://arxiv.org/abs/2503.06749
 豫公网安备41010702003375号
豫公网安备41010702003375号