
OpenAI推出新一代音频模型API,价格最高的文本转语音模型,使用成本每分钟1毛
![]() 前沿资讯
1742534839更新
前沿资讯
1742534839更新
![]() 0
0
在过去几个月,OpenAI持续发力,不断提升基于文本的智能体的能力,推出了Operator、深度研究(Deep Research)智能体、计算机使用(Computer-Using)智能体以及集成内置工具的响应API等成果。然而,要让智能体真正发挥作用,不应仅局限于文本交互,如果能够通过自然的口语进行有效沟通,体验将会更佳。为此,他们将目光投向语音交互领域,致力于通过自然口语与智能体进行更深入、直观的沟通。

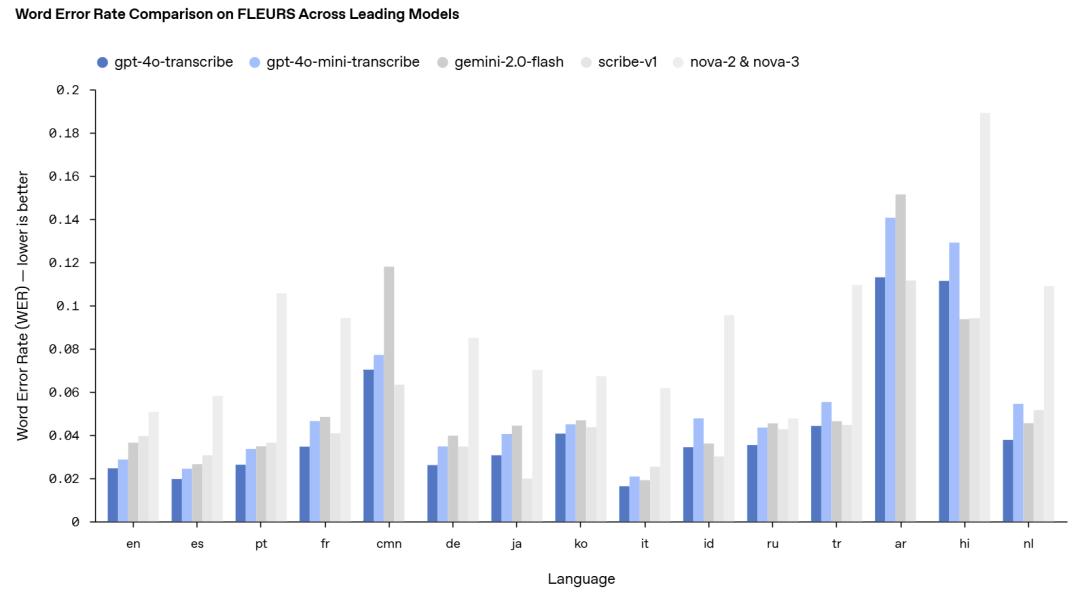
今天凌晨,OpenAI宣布推出全新的“语音转文本”和文“本转语音”音频模型API。新的语音转文本模型:gpt-4o-transcribe和gpt-4o-mini-transcribe,在词错误率、语言识别和准确性方面均优于原始的Whisper模型。在多个权威基准测试中,尤其是在涵盖100多种语言的多语言语音基准测试FLEURS中,这些新模型展现出了更低的词错误率(WER),可实现更高的转录准确性和更广泛的语言覆盖范围。无论是处理带有口音的语音、嘈杂环境中的声音,还是不同语速的话语,新模型都能更精准地捕捉语音细节,减少误识别,极大地提高了转录的可靠性。
新的文本转语音模型gpt-4o-mini-tts首次能够进行双重指令,开发者不仅可以指定要说的内容,还能决定说话的方式,如语调、语速、语气等。这使得生成的语音更加自然、生动,能够更好地适配不同的应用场景和用户需求。这一突破为语音智能体的定制化开辟了新边界,让各种定制应用都成为可能。不过,目前这些文本转语音模型仅限于人工预设的语音,OpenAI会对其进行严格监测,确保符合使用标准。
模型训练方面,OpenAI表示,新音频模型基于GPT-4o和GPT-4o-mini架构,利用专门的真实音频数据集进行广泛预训练,从而能够更深入地理解语音的细微差别,在与音频相关的任务中实现卓越的性能。他们改进了蒸馏技术,实现从大型音频模型到小型高效模型的知识转移,利用先进的自博弈方法,蒸馏数据集有效地捕捉了现实的对话动态,复制了真实的用户与智能体之间的交互,让较小模型也能提供出色的对话质量和响应能力。在语音转文本模型中,引入强化学习范式,这种方法显著提高了精度,减少了幻觉现象,将转录准确性提升到了最先进的水平,使模型在复杂语音识别场景中表现卓越。
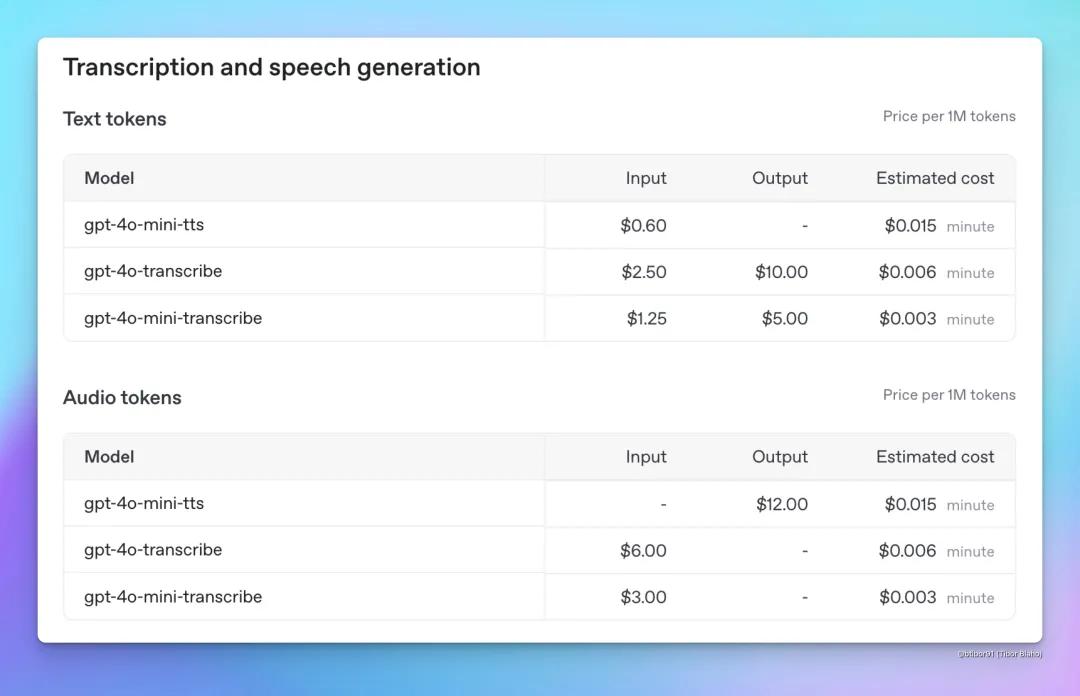
三个模型的API价格方面:
gpt-4o-transcribe(语音转文本模型):按文本tokens算,每100万tokens输入费用2.5美元,输出每100万tokens费用10美元;按音频tokens算,每100万tokens输入费用6.00美元。按时间计费,使用该模型每分钟成本是0.006美元。
gpt-4o-mini-transcribe(语音转文本模型):按文本tokens计算,每100万tokens输入费用为1.25美元,输出每100万tokens费用5.00美元;按音频tokens计算,每100万tokens输入费用是3.00美元。按时间计费,使用这个模型每分钟成本为0.003美元。
gpt-4o-mini-tts(文本转语音模型):按文本tokens计算,每100万tokens输入费用是0.60美元;按音频tokens计算,每100万tokens输出费用为12.00美元。以时间计费,使用该模型每分钟成本是0.015美元。
对于不熟悉语音智能体概念的人来说,语音智能体是一种能代表用户或开发者独立行动的人工智能系统。常见的文本智能体,如网站右下角的聊天框,用户可以通过输入文字询问产品目录或订单信息,而语音智能体则将这种交互方式转变为语音形式,用户可以通过打电话与AI语音进行交流。语音智能体的应用场景十分广泛,其中语言学习体验是一大热门方向。在语言学习中,语音智能体可以指导发音、制定课程计划,并与学习者进行模拟对话,帮助他们提升语言能力。
开发者构建语音智能体主要有两种方式。一种是采用更前沿的端到端语音模型,这类模型能够直接理解音频并直接回复语音,速度极快。另一种则是链式方法,即先使用语音转文本模型将用户的语音转化为文字,再由文本模型(如GPT-4)进行处理,生成合适的文本回复,最后通过文本转语音模型将回复以语音形式输出。链式方法因其模块化特性深受开发者喜爱,他们可以根据不同的应用场景选择最佳的模型组件进行搭配,同时这种方式也更容易实现高可靠性,且上手难度较低。
OpenAI表示这些新的音频模型现已向所有开发者开放。对于已经在使用基于文本的模型构建对话体验的开发者来说,添加语音转文本和文本转语音模型是构建语音智能体的最简单方法。OpenAI对智能体SDK进行了大幅更新,这一更新也让广大开发者降低了语音智能体的开发门槛,使他们能够更快地将现有的文本智能体项目拓展到语音交互领域。
参考资料:https://openai.com/index/introducing-our-next-generation-audio-models/
 豫公网安备41010702003375号
豫公网安备41010702003375号