
谷歌研究团队重大发现:大语言模型与人类大脑语言处理机制存在紧密联系
![]() 前沿资讯
1周前更新
前沿资讯
1周前更新
![]() 0
0
谷歌研究团队联合普林斯顿大学、纽约大学和耶路撒冷希伯来大学,在语言处理领域的新研究成果发现,大语言模型内部的上下文嵌入与人类大脑在处理日常对话时的神经活动呈现线性对齐。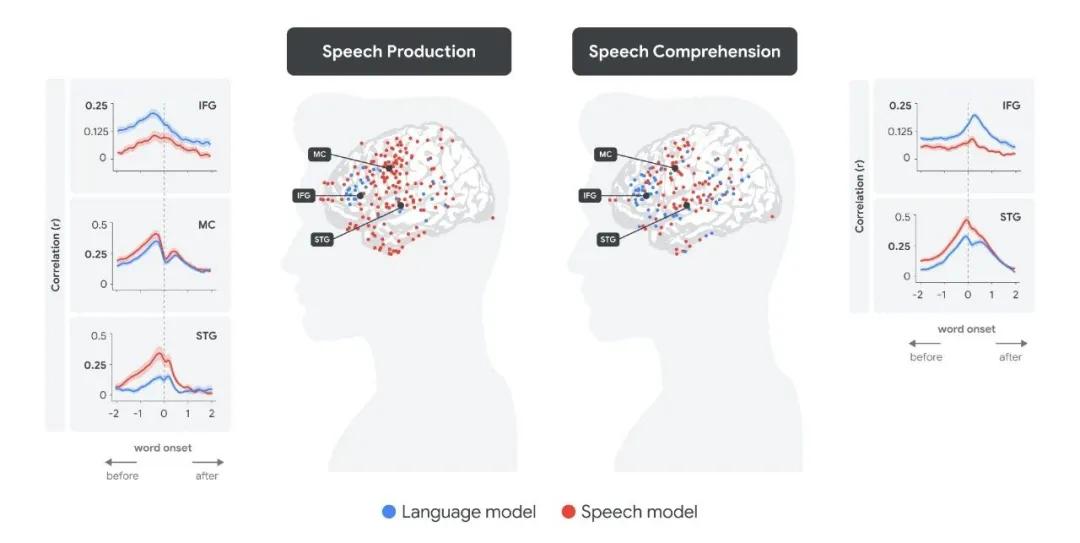
从理论上讲,大语言模型与人类语言处理机制有着本质区别。大语言模型不依赖于符号词性或句法规则,而是利用简单的自监督目标,通过下一个词预测,以及强化学习来生成语言输出,从而能够从现实世界的文本语料库中生成特定于上下文的语言输出,有效地将自然语音(声音)和语言(单词)的统计结构编码到多维嵌入空间中。然而,此次研究却揭示出两者之间存在诸多令人意想不到的关联。
研究团队利用颅内电极记录人们在自发对话时的神经活动,并将其与 Whisper 语音转文本模型生成的内部表示进行对比。对于每一个被听到或说出的单词,研究人员从模型中提取两种类型的嵌入:语音编码器产生的语音嵌入,以及解码器生成的基于单词的语言嵌入。
实验结果令人惊讶。在言语理解过程中,当听者听到单词时,最初语音嵌入能够预测沿颞上回(STG)言语区域的皮质活动,几百毫秒后,当听者开始理解单词含义时,语言嵌入则能预测布洛卡区(位于额下回,IFG)的皮质活动。而在言语产生过程中,顺序则相反:在说话者准备说出单词前约 500 毫秒,语言嵌入可预测布洛卡区的皮质活动;随后,在单词说出前,语音嵌入能预测运动皮层(MC)的神经活动;当单词说出后,语音嵌入又能预测颞上回听觉区域的神经活动。
全脑分析的定量结果进一步证实了这种紧密联系。研究人员根据语音嵌入和语言嵌入,预测单词出现前后不同时间点各个电极的神经反应,发现语言嵌入和语音嵌入在不同脑区的峰值出现时间与言语产生和理解的过程高度吻合。
此外,大语言模型与人类大脑在语言处理方面两者都试图在单词被说出前预测下一个单词,并且听者对预测的信心会影响听到单词后的惊讶程度(预测误差)。同时,大语言模型嵌入空间中单词之间的关系,与大脑在语言区域诱导的表示的几何结构也存在对齐关系。
不过,研究团队也指出,虽然大语言模型和人类大脑在处理自然语言时存在共同的计算原则,但它们的底层神经回路架构却差异显著。大语言模型的 Transformer 架构能够同时处理大量单词,而人类大脑的语言区域则倾向于逐个、循环、按时间顺序分析语言。
这些发现表明,深度学习模型可以基于统计学习、盲目优化以及对自然的直接拟合原则,为理解大脑处理自然语言的神经编码提供一个新的计算框架。同时,基于 Transformer 的语言模型的神经架构、语言数据的类型和规模、训练协议,与人类大脑在社会环境中自然习得语言的生物结构和发展阶段之间存在显著差异。
接下来,该研究团队的目标是创建受生物启发的创新人工神经网络,提高其在现实世界中处理信息和发挥功能的能力。他们计划通过调整神经架构、学习协议和训练数据,使其更好地匹配人类经验来实现这一目标。
参考资料:https://research.google/blog/deciphering-language-processing-in-the-human-brain-through-llm-representations/
 豫公网安备41010702003375号
豫公网安备41010702003375号