
英伟达提出前馈网络融合技术:推理延迟降低1.7倍,token成本降低35倍!
![]() 前沿资讯
1742981712更新
前沿资讯
1742981712更新
![]() 0
0
大语言模型规模的持续扩大带来了前所未有的计算需求,尤其是在推理阶段,这一需求严重限制了模型的实际应用。传统的优化方法,如量化和蒸馏,虽有一定成效,但也存在明显的局限性,而混合专家(MoE)架构也并非适用于所有批量大小。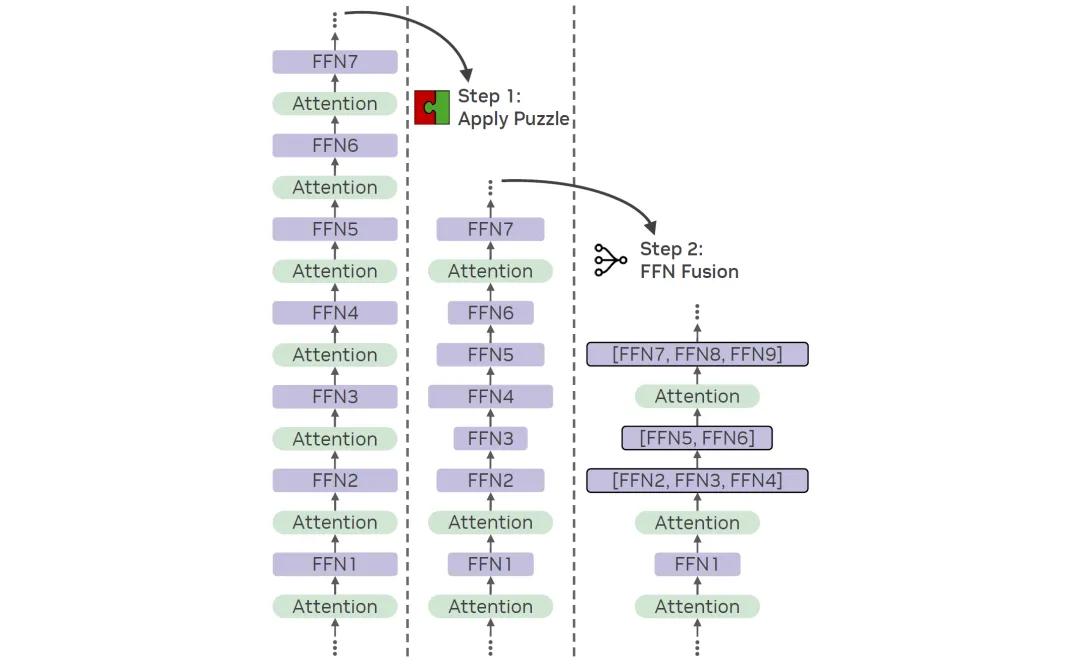
在此背景下,探索互补性的效率提升策略迫在眉睫。英伟达研究人员提出了一种前馈网络融合(FFN Fusion)技术,这是一种针对大语言模型的独特架构优化策略,旨在通过并行化前馈网络(FFN)层序列,显著降低推理延迟和处理成本。其核心要点在于,在移除特定注意力层(通常使用如Puzzle等方法)后,后续的FFN层之间展现出出乎意料的低层间依赖性。这些层随后可合并为一个更大的FFN层,从而能够在GPU上实现并行执行。
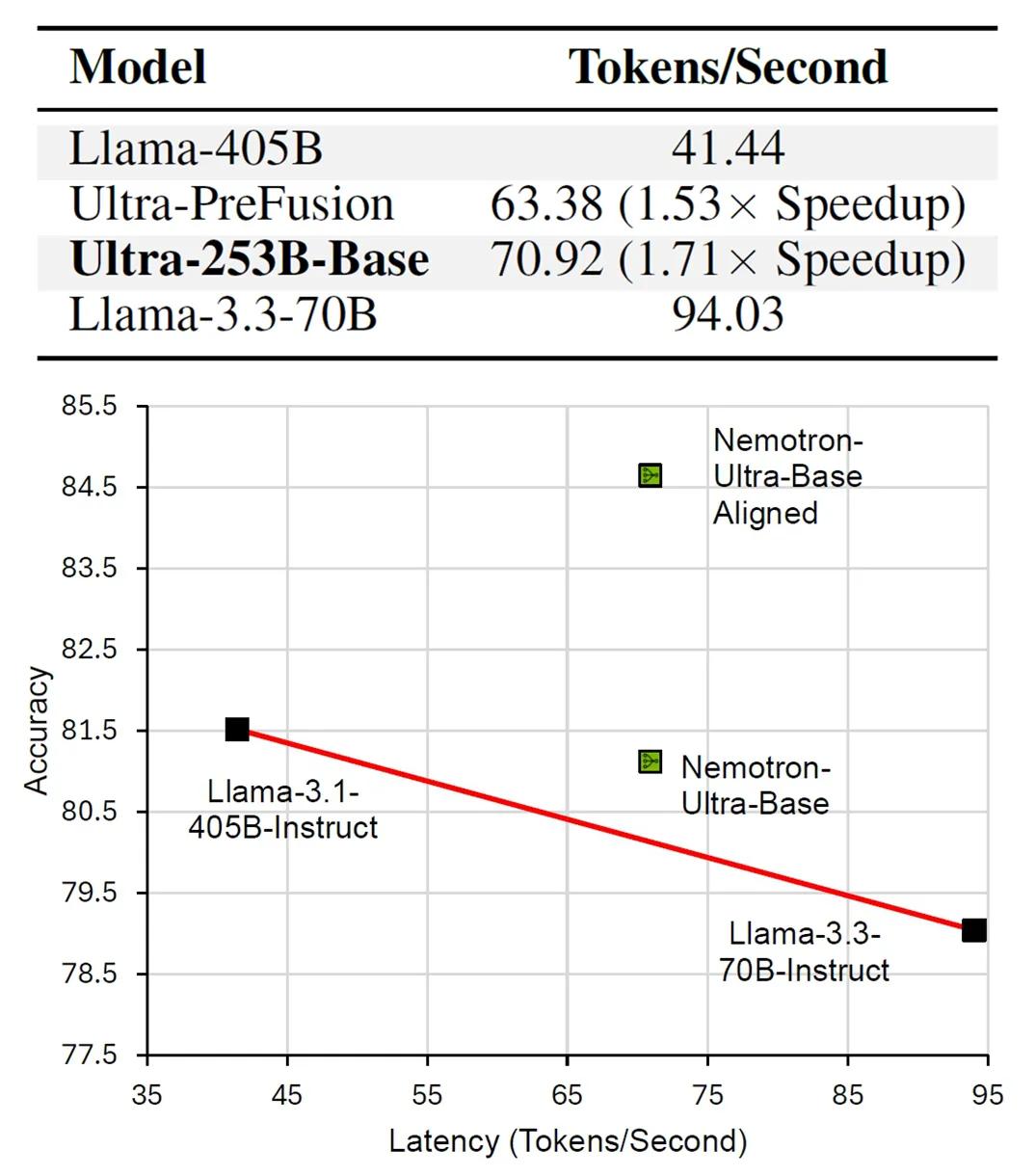
通过深入研究,他们利用适当连接的权重矩阵,正式证明了一系列FFN层在数学上等同于单个FFN层,这一理论突破为实践应用提供了有力支撑。研究人员以Llama-3.1-405B-instruct为基础,创建了一个Llama-Nemotron-Ultra-253B-base(Ultra-253B-base)模型,实验结果显示,Ultra-253B-base模型在推理延迟上实现了1.71倍的加速,每个token的成本降低了35倍,同时在多个基准测试中仍保持了较高的性能。这一成果意味着FFN融合技术能够在不牺牲模型性能的前提下,大幅提升模型的运行效率。
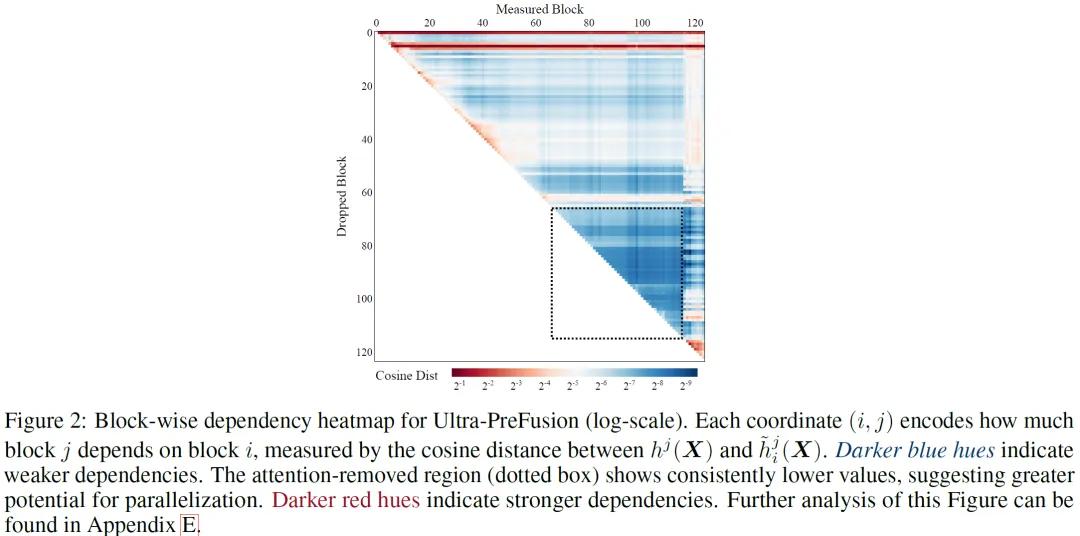
为了深入分析模型的性能,研究人员进行了成对块依赖性分析。他们通过计算一个块的贡献与移除另一个块后的贡献之间的余弦距离,来衡量不同Transformer块之间的依赖性。这种方法能够识别出相互依赖性低、适合并行化的块序列,尤其是那些仅由前馈网络(FFN)组成的序列。实验表明,较小的余弦距离表明块之间具有相对独立性,这一特性可用于增加并行计算。例如,当删除块i对块j的影响很小时,就可以利用这种独立性进行并行化处理。
此外,研究还发现,FFN融合技术可以与其他优化技术协同使用,并且在更大规模的模型中表现更为出色。令人惊喜的是,早期研究暗示,在某些情况下,甚至整个Transformer块都可以被并行化,这为神经架构设计开辟了全新的方向。
从应用前景来看,FFN融合技术能够使聊天机器人、机器翻译系统等更加高效地运行,为用户提供更快速、流畅的交互体验。在智能客服方面,能够快速理解客户问题并提供准确回答,提升客户满意度。在信息检索领域,可加速对大量文本的处理,提高搜索结果的准确性和返回速度。
然而,如同任何新兴技术一样,FFN融合技术也面临一些问题和需要考虑的因素。在追求效率提升的同时,如何确保模型的准确性不受到显著影响,是需要持续关注的问题。虽然当前研究表明该技术在保持模型性能方面表现良好,但随着应用场景的不断拓展和模型复杂度的增加,准确性与效率之间的平衡仍需进一步探索。
此外,硬件和软件对并行化的支持程度也会影响技术的推广应用。不同的GPU架构和软件框架在并行计算能力上存在差异,如何优化技术以适应各种硬件和软件环境,是实现广泛应用的关键。块并行化的复杂性也不容忽视,寻找最佳的融合策略需要深入研究和大量实验,以充分发挥技术的优势。
参考资料:https://arxiv.org/abs/2503.18908
 豫公网安备41010702003375号
豫公网安备41010702003375号