
苏州大学团队提出Chain-of-Tools方法,提升大语言模型工具学习能力
![]() 前沿资讯
1743055978更新
前沿资讯
1743055978更新
![]() 0
0
苏州大学研究团队提出了一种全新的工具学习方法Chain-of-Tools(CoTools),能让冻结的大语言模型在思维链(CoT)推理过程中高效利用大量未见工具。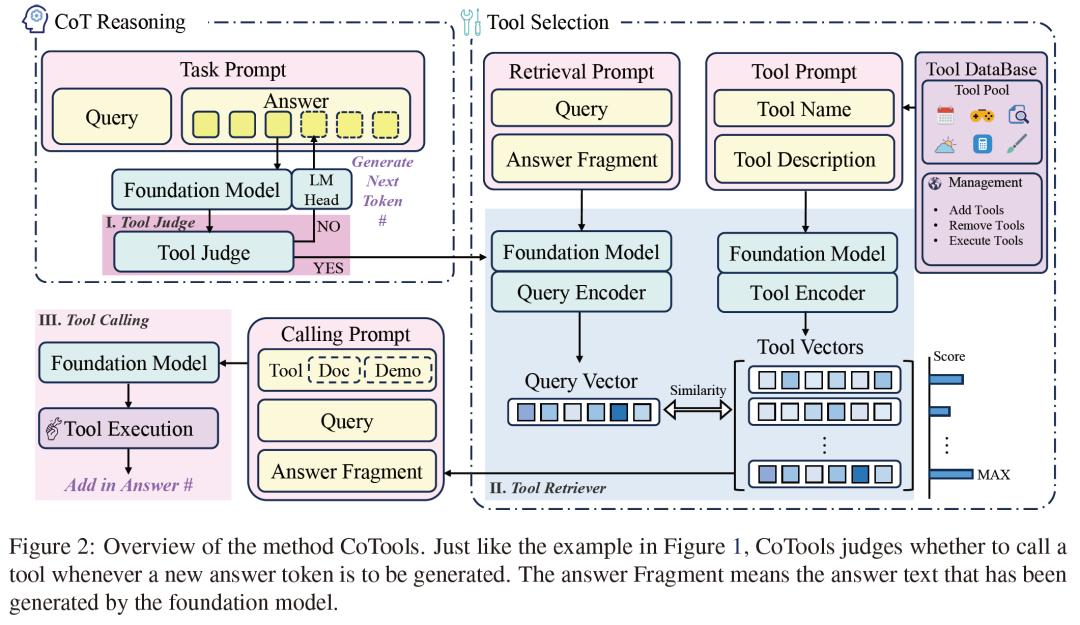
随着大语言模型在现实应用中的广泛使用,开发自主智能体系统成为学术和工业界的热门焦点。虽然大语言模型擅长逻辑推理和问题拆解,但仍无法完成诸多特定任务,如数学公式计算、绘画等。为拓展其应用场景,工具学习任务致力于探索如何让大语言模型在推理过程中更好地利用外部工具。目前,主流的工具学习方法主要有基于微调的方法和基于上下文学习的方法,但它们分别存在只能使用训练数据中见过的工具、推理效率较低等问题。
CoTools则创新性地解决了这些难题。该方法充分利用“冻结的大语言模型”强大的语义表示能力,在CoT推理中实现工具调用,且能应对包含未见工具的庞大灵活工具池。那什么是“冻结的大语言模型”?简单来说,就是模型在完成初始训练后,不再对其内部参数权重进行任何更改。其优势在于能保持模型原始的泛化能力,避免因微调带来的一系列负面问题。比如,在某些应用场景中,微调可能会导致模型过于适应特定任务数据,从而在其他类似但有差异的任务上表现不佳,而冻结的大语言模型能规避这种情况。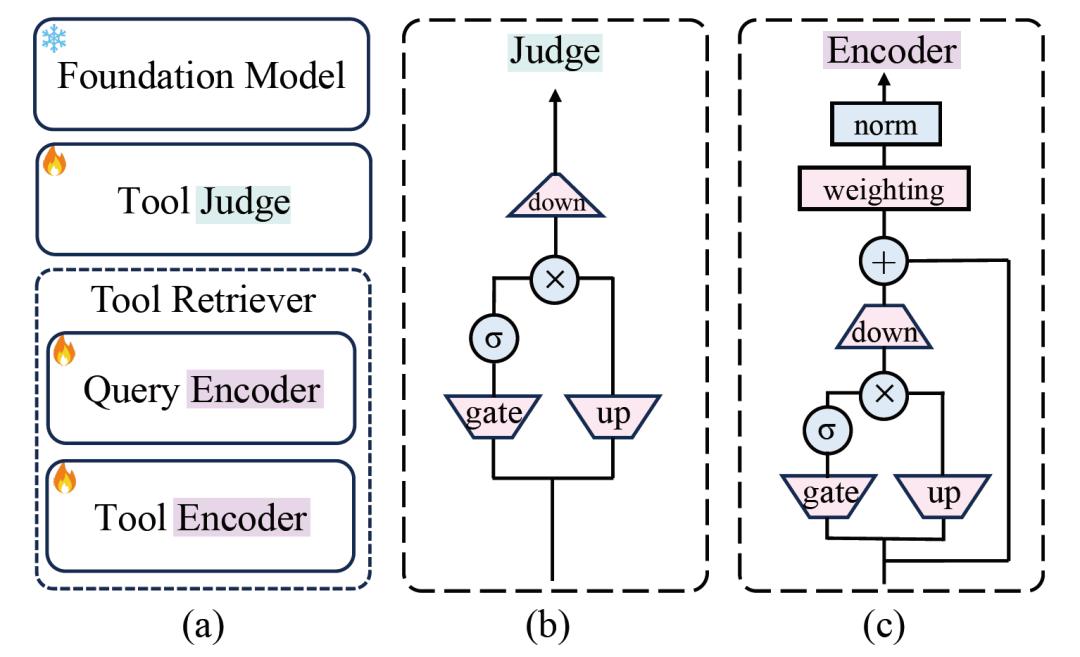
CoTools核心结构包含Tool Judge(工具判断器)、Tool Retriever(工具检索器)和Tool Calling(工具调用)三个部分。Tool Judge用于判断在答案生成的特定位置是否调用工具,Tool Retriever基于查询和已生成的答案片段选择最合适的工具,Tool Calling则通过上下文学习提示填充所选工具的参数、执行工具并获取返回值。在训练过程中,Tool Judge作为序列标注任务进行训练,Tool Retriever采用对比学习方法训练,整个过程无需对基础模型进行训练,避免了影响模型原有的泛化能力。
为验证CoTools的有效性,研究团队构建了新数据集SimpleToolQuestions(STQuestions),该数据集包含1836个工具,专注于在大量未见工具场景下评估模型的工具选择性能。研究人员在两个数值推理基准测试(GSM8K-XL和FuncQA)和两个基于知识的问答基准测试(KAMEL和SimpleToolQuestions)上展开实验。结果显示,CoTools在各个基准测试中均优于基线方法,尤其在处理大规模工具和未见工具时表现出色。
在数值推理任务中,基于不同基础模型的CoTools在GSM8K-XL和FuncQA数据集上,与其他方法相比效果显著。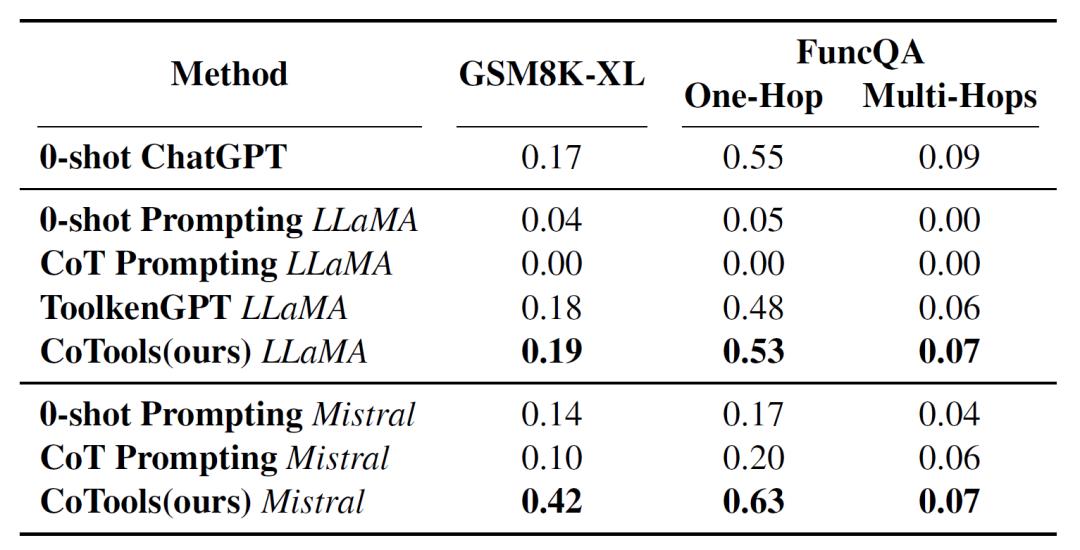
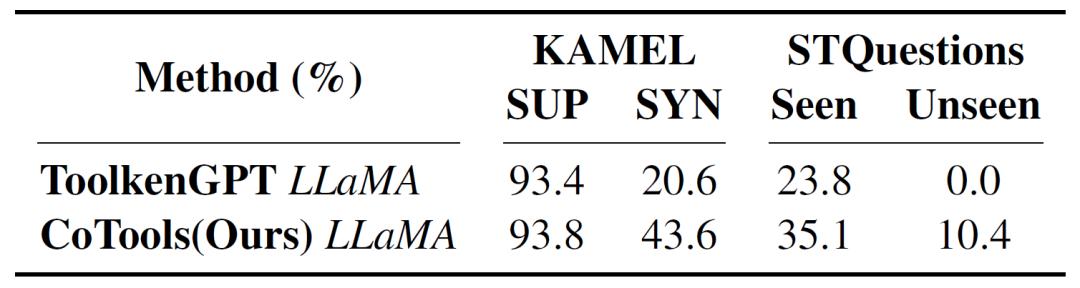
在基于知识的问答任务中,对于有大量黄金训练数据的KAMEL(sup),CoTools和其他方法表现都不错,而在合成训练集KAMEL(syn)上,CoTools比ToolkenGPT的性能高出20%以上。在处理STQuestions数据集中的未见工具时,CoTools的top1准确率达到10.41%,top5准确率为33.68%,而ToolkenGPT的top1准确率为0.0%。此外,研究还发现了模型输出隐藏状态中对工具选择起关键作用的维度,有助于增强模型的可解释性。
研究团队也指出了当前研究的局限性。例如,尚未对包含多个返回值的工具进行实验,并且由于缺乏大规模可实现工具的数据集,未能在大规模真实工具集上尝试完整的工具学习过程。该研究的代码和数据已在https://github.com/fairyshine/Chain-of-Tools上开源,供学界和业界进一步研究和应用。
参考资料:https://arxiv.org/abs/2503.16779
 豫公网安备41010702003375号
豫公网安备41010702003375号