
英伟达提出基于测试时训练(Test-Time Training)层的视频生成技术,可生成一分钟的复杂多场景视频
![]() 前沿资讯
1744092544更新
前沿资讯
1744092544更新
![]() 0
0
当前,视频生成技术在视觉和物理真实感方面取得了显著进展,但最先进的视频Transformer模型大多只能生成单场景的短视频片段,难以构建复杂故事。例如,OpenAI的Sora、Meta的MovieGen、Google的Veo 2等公共API,生成视频的最长时长分别仅为20秒、16秒和8秒,且均无法自主生成复杂的多场景故事。其根本挑战在于长上下文处理,Transformer中自注意力层的成本会随上下文长度呈二次增长,这对于具有动态运动的视频生成而言尤为棘手。
为解决这一难题,英伟达联合斯坦福大学、加州大学圣地亚哥分校等机构的研究人员,创新性地引入了TTT层。TTT 层的核心思想是将隐藏状态本身设计为神经网络,突破了传统RNN层隐藏状态为固定大小矩阵的限制。通过自我监督学习,它能将历史上下文信息压缩到隐藏状态中,使得模型在处理长序列时,隐藏状态可以像机器学习模型的权重一样进行更新。在处理视频中连续的复杂场景时,TTT层能够不断学习和记忆前面场景的关键信息,从而在后续场景生成中保持逻辑连贯,传统方法难以实现。
TTT层的自我监督任务并非基于人工先验设定,而是采用端到端的学习方式,作为外部循环的一部分进行学习。通过对输入进行低秩投影等操作,让模型学习如何从部分信息中重建原始数据,从而挖掘数据维度之间的相关性,提升对复杂信息的处理能力。这种自适应的学习方式,使得TTT层能更好地适应不同的视频生成任务需求。
在实现过程中,研究人员以预训练的Diffusion Transformer(CogVideo-X 5B)为基础,添加TTT层并进行微调。为了使TTT层更好地融入模型,他们采用了门控机制,避免了在微调初期因随机初始化而导致的模型性能下降,同时运用双向策略,使TTT层能够在非因果的Diffusion模型中有效工作。此外,他们将视频结构化处理,划分为多个场景,每个场景包含多个3秒片段,让自注意力层在局部3秒片段上处理,而TTT层则对整个输入序列进行全局处理,有效平衡了计算效率和长上下文处理能力。
研究团队基于约7小时的《猫和老鼠》卡通片构建了一个文本到视频的数据集,精心标注故事板,着重强调复杂、多场景和长距离故事以及动态运动。在与Mamba 2、Gated DeltaNet、滑动窗口注意力层等强大基线模型的对比中,TTT层表现卓越。在对100个视频的人工评估中,TTT层生成的视频在连贯性、复杂故事讲述和动态运动呈现方面表现更优,平均比第二好的方法高出34 Elo点。
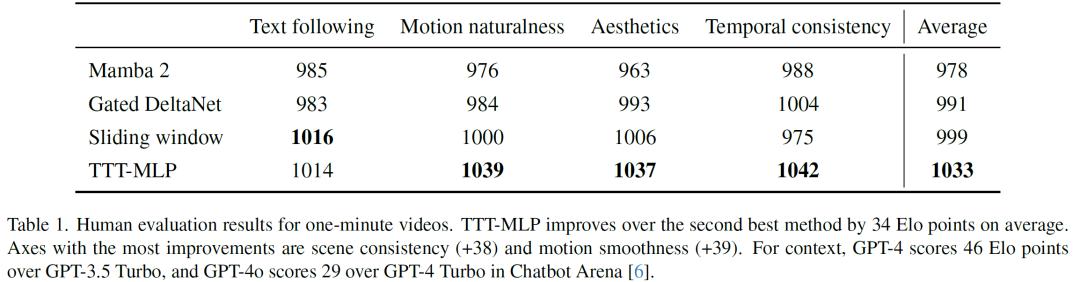
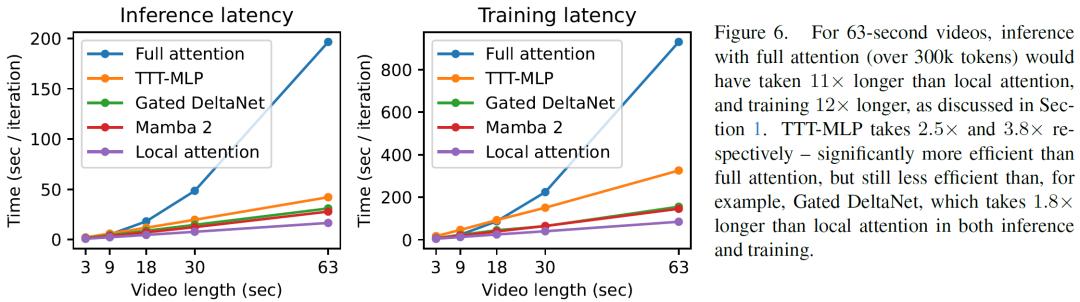
不过,该技术也存在一些局限性。在处理18秒视频时,具有线性(矩阵)隐藏状态的RNN层(如Gated DeltaNet和Mamba 2)表现更优。TTT-MLP的效率仍不如Gated DeltaNet和Mamba 2,生成的视频在运动自然度和美学方面还存在一些瑕疵,如物体有时会不自然地漂浮、光照变化与动作不一致等。
未来,研究团队计划从多个方向进一步优化该技术。一是通过优化寄存器压力和改进异步操作的编译器感知实现,提升TTT-MLP内核的效率;二是探索更好的集成策略,将TTT层更有效地融入预训练模型,以提高生成视频的质量并加速微调过程;三是尝试将隐藏状态实例化为更大的神经网络,如Transformer,从而实现更长视频的生成。
参考资料:chrome-extension://lbcbipoloacjakecofjkohgllhojdhhp/assets/pdf-viewer/web/viewer.html?file=https%3A%2F%2Ftest-time-training.github.io%2Fvideo-dit%2Fassets%2Fttt_cvpr_2025.pdf
 豫公网安备41010702003375号
豫公网安备41010702003375号