
月之暗面推出最新“开源”轻量级视觉语言模型:Kimi-VL和Kimi-VL-Thinking
![]() 前沿资讯
1744279245更新
前沿资讯
1744279245更新
![]() 0
0
随着人工智能快速发展,人们对AI助手的期望已从传统纯语言交互,转变为更符合现实世界多模态本质的交互方式。在此背景下,新一代多模态模型应运而生,如GPT4o和Google Gemini,它们具备感知和解释视觉输入以及处理语言的能力。但开源社区中大型视觉语言模型(VLMs)的发展,相较于纯语言模型在可扩展性、计算效率和先进推理能力等方面,仍较为滞后。
纯语言模型已采用高效可扩展的混合专家(MoE)架构,并实现复杂的长思维链推理,但多数开源视觉语言模型(如Qwen2.5-VL和Gemma-3)仍依赖密集架构,不支持长思维链推理。早期基于MoE的视觉语言模型,像DeepSeek-VL2和Aria,也存在架构和能力上的局限,前者采用传统固定大小视觉编码器,支持的上下文长度有限,后者在细粒度视觉任务上表现欠佳,且二者均不具备长思考能力。因此,开发一款能有效整合结构创新、稳定性能和增强长思考推理能力的开源视觉语言模型迫在眉睫。月之暗面团队基于此,正式提出了高效开源视觉语言模型Kimi-VL。
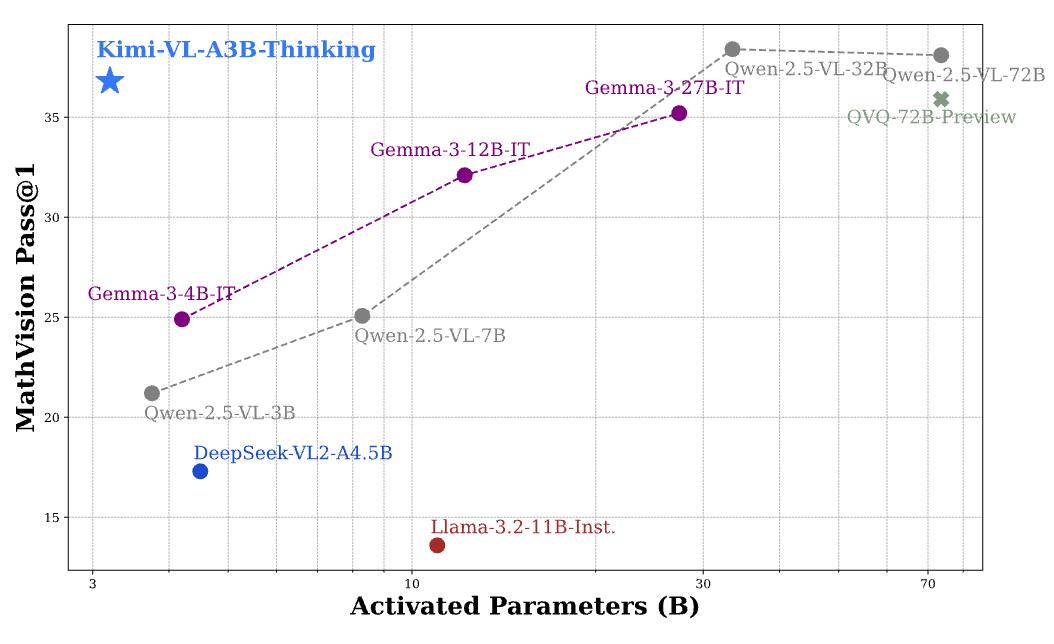
Kimi-VL基于混合专家(MoE)架构,总参数160亿,推理时仅激活28亿参数(Kimi-VL-A3B),在多模态推理方面表现出色,能与参数规模大10倍的模型媲美。在多项基准测试中成绩优异,在MMMU验证集上得分57.0%,超越DeepSeek-VL2,与Qwen2.5-VL-7B和Gemma-3-12B-IT相当;在MathVista基准测试中达到68.7%,超过GPT-4o和Qwen2.5-VL-7B等。
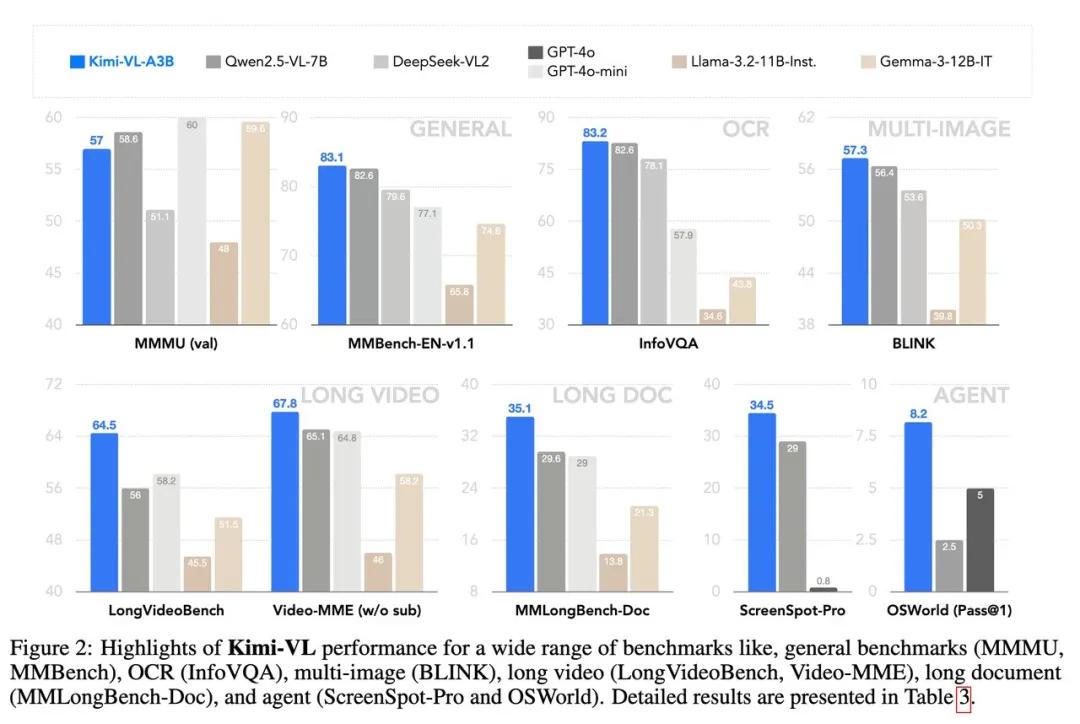
长上下文处理能力突出,拥有128K扩展上下文窗口,能有效处理各种长输入,在长视频和长文档理解方面优势明显。在LongVideoBench和MMLongBench-Doc基准测试中,分别取得64.5分和35.1分的成绩,远超类似规模的竞争对手。
视觉感知清晰准确,采用原生分辨率视觉编码器MoonViT,可处理超高分辨率视觉输入,在InfoVQA和ScreenSpot-Pro测试中,得分分别达到83.2和34.5。在各类视觉语言场景中,包括视觉感知、视觉世界知识、OCR、高分辨率OS截图等方面,都展现出全面的竞争能力。
基于Kimi-VL,月之暗面团队进一步推出长思考变体Kimi-VL-Thinking。通过长思维链监督微调(SFT)和强化学习(RL)训练,该模型具备强大的长程推理能力。在MMMU、MathVision和MathVista基准测试中,分别取得61.7分、36.8分和71.3分,为高效多模态思维模型树立新标杆。
Kimi团队表示,Kimi-VL的推理能力在典型应用中表现出色,但在需要多步推理或深度上下文理解的复杂任务中,尚未达到理论上限。虽然拥有128K扩展上下文窗口,但由于注意力层参数有限(仅相当于3B模型),在处理极长序列或大量上下文信息的先进应用时,长上下文能力仍显不足。未来,团队将通过扩大模型规模、扩展预训练数据和改进后训练算法等方式持续优化,推动多模态人工智能在研究和工业领域的广泛应用。
参考资料:https://huggingface.co/collections/moonshotai/kimi-vl-a3b-67f67b6ac91d3b03d382dd85
 豫公网安备41010702003375号
豫公网安备41010702003375号