
奖励模型:AI发展的关键驱动力
![]() 前沿资讯
1746780049更新
前沿资讯
1746780049更新
![]() 0
0
随着深度学习技术的不断进步,大语言模型在自然语言处理(NLP)等领域取得了显著进展。然而,如何有效评估模型生成响应的质量,成为了亟待解决的问题。早期的监督学习方法虽能通过标注数据训练模型生成高质量响应,但在面对复杂多变的用户偏好、语义理解深度等评估机制时,这种方法逐渐暴露出局限性。在此背景下,奖励模型应运而生。
奖励模型的核心思想,是深度借鉴强化学习中的“奖励信号”机制,引导模型生成更贴合人类偏好的输出内容。它就像是一个“裁判”,对生成的每个响应分配一个奖励值,以直观地反馈模型生成内容的质量或符合人类偏好的程度。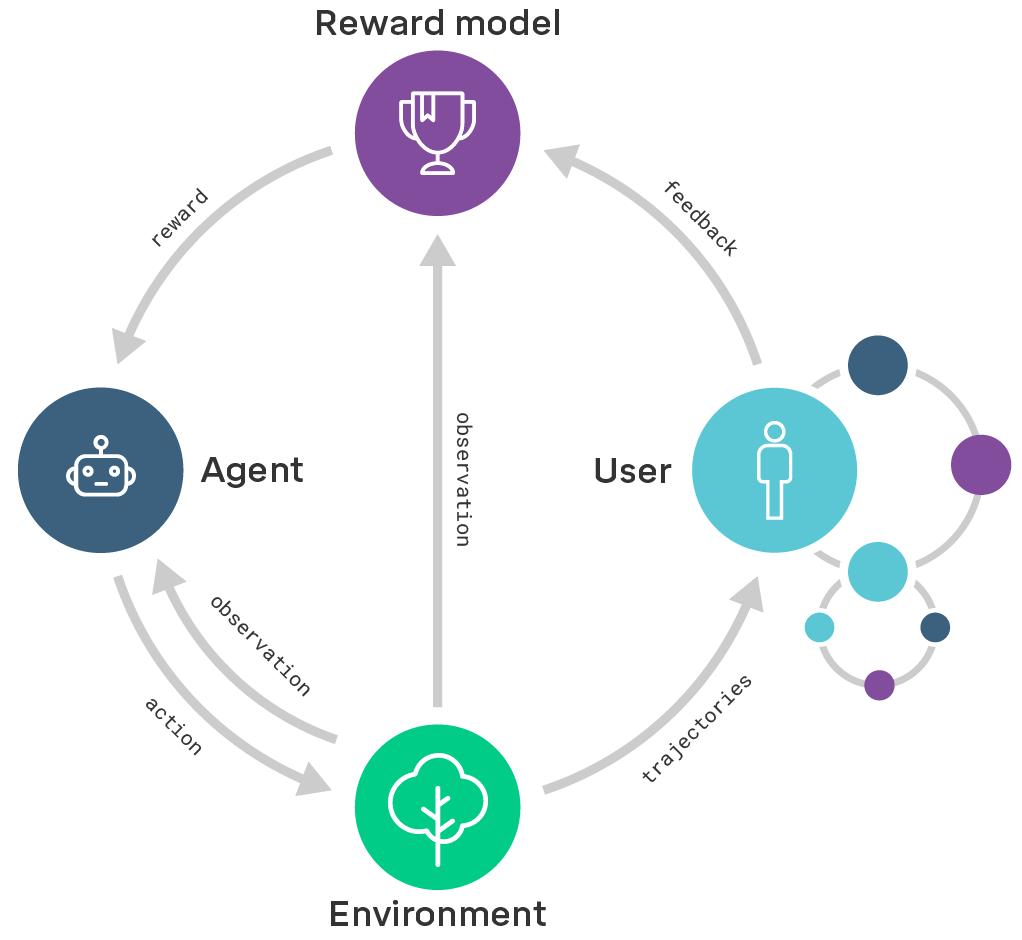
奖励模型与强化学习的结合,尤其是人类反馈强化学习(RLHF)的应用,极大地推动了人工智能技术的发展。在人类反馈强化学习框架中,奖励模型的运作流程精细且严谨:首先,运用监督微调(SFT)技术对预训练语言模型进行优化,让模型能够根据用户提示,生成相对高质量的响应内容。接着,利用经过监督微调训练的基础模型,针对同一提示生成多个候选响应,再由专业的标注团队从多个角度对这些响应进行质量评估,基于大量的人类反馈数据训练出一个奖励模型。最后,借助强化学习算法(如近端策略优化算法PPO),依据奖励模型给出的评分,对基础模型进行进一步优化。在这个循环往复的过程中,奖励模型通过对生成响应的精准打分,帮助模型深入学习人类的语言使用习惯、价值偏好,从而显著提升生成内容的质量和实用性。
随着研究的深入,奖励模型的形式日益多样化。目前,最常见的奖励模型主要有两种:结果奖励模型(Outcome Reward Model,ORM)和过程奖励模型(Process Reward Model,PRM)。结果奖励模型主要关注最终结果的质量,即评估模型生成的输出是否满足目标要求,通过对生成的最终答案进行评分来衡量模型表现。而过程奖励模则不仅关注最终答案,还对模型的推理过程进行评分,在生成答案的过程中逐步激励或惩罚模型,引导模型朝着更可解释、更稳定的推理路径发展。
大语言模型在执行自然语言处理任务时,常出现与用户意图不一致的情况,如编造事实、生成有害内容等。因此,让模型更好地遵循用户指示,实现与用户意图的精准对齐,成为了当前AI研究的关键方向。
通过对人类反馈进行微调来对齐语言模型的方法,主要涵盖监督微调、奖励模型训练和基于奖励模型的强化学习三个步骤。以InstructGPT为例,实验数据显示,经过对齐优化后的InstructGPT模型,在遵循用户指示的准确率上提升了30%,有害输出的比例降低了40%,内容真实性也显著提高。更令人惊叹的是,在大多数实际应用场景中,参数规模相对较小,仅拥有13亿参数的InstructGPT模型,其综合表现甚至超越了拥有1750亿参数的原始GPT-3模型,充分展示了奖励模型在优化模型性能方面的强大威力。
随着AI技术向更多领域的拓展延伸,奖励模型有望带来更多突破性进展,持续推动人工智能技术迈向新的高度。
 豫公网安备41010702003375号
豫公网安备41010702003375号