
字节跳动开源发布Seed-Coder模型家族
![]() 前沿资讯
1747041832更新
前沿资讯
1747041832更新
![]() 0
0
在编程领域,将语言模型应用于代码生成和处理的设想逐渐成为现实,代码模型能够理解人类的编程意图,并根据给定的需求自动生成代码,该技术的出现极大地提高了编程效率,减少了人为错误,降低了软件开发成本。
但,传统的开源模型在获取代码预训练数据时,大多采用依赖人工的方式。比如针对不同编程语言手工编写过滤规则,或者耗费大量人力进行数据标注来训练质量过滤器。从可扩展性角度看,通过传统方式手工编写的规则难以适应快速变化的编程语言生态,扩展到多种语言时成本也极高。在准确性方面,传统方式也容易受到人工主观因素的影响,导致数据偏差,而且随着语言种类和数据量的增加,维护成本也会大幅上升。据相关研究表明,采用人工标注数据训练的模型,在某些特定任务上的错误率相比理想状态可能会高出10%-20%。这些传统方式严重阻碍了代码模型的进一步发展和应用。
在这样的背景下,字节跳动的Seed-Coder项目应运而生。Seed-Coder摒弃了传统的过度依赖人工的模式,借助模型对代码数据进行评分和过滤,并构建了一套包含6万亿标记的代码预训练语料库。这些数据被分为文件级代码、仓库级代码、提交数据和代码相关网页数据四类,为后续模型训练提供了丰富素材。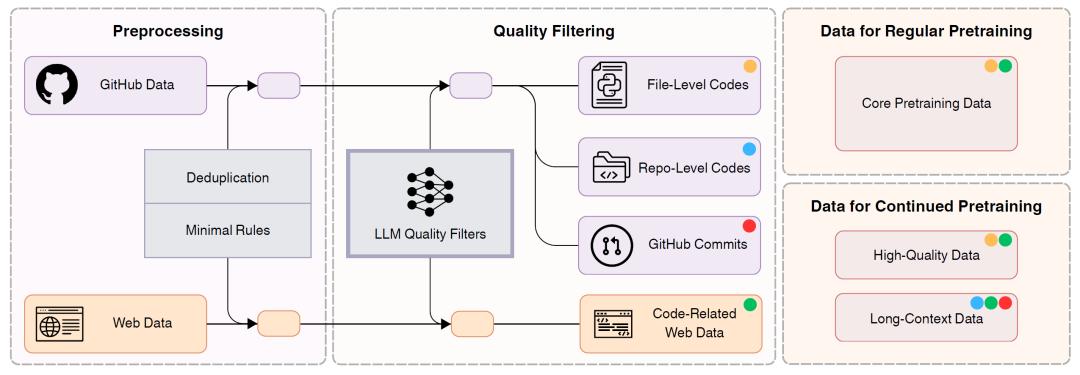
基于这一创新的数据管道,Seed-Coder家族应运而生,Seed-Coder包含基础、指令和推理模型,参数规模为80亿。
Seed-Coder-8B-Base是Seed-Coder系列的基础模型,专为代码生成任务进行预训练,参数量约8.2亿,采用Llama-3结构,拥有36层,隐藏层大小为4096,中间层大小为14336,运用Grouped Query Attention(GQA),查询头为32个,键值头为8个,不使用绑定嵌入。
Seed-Coder-8B-Instruct模型基于基础模型进行指令微调,通过在大规模合成数据上进行监督微调(SFT)和直接偏好优化(DPO),增强了对各种指令的理解和执行能力。
Seed-Coder-8B-Reasoning模型借助Long-Chain-of-Thought(LongCoT)强化学习技术,提升了在复杂编码任务中的多步推理能力。
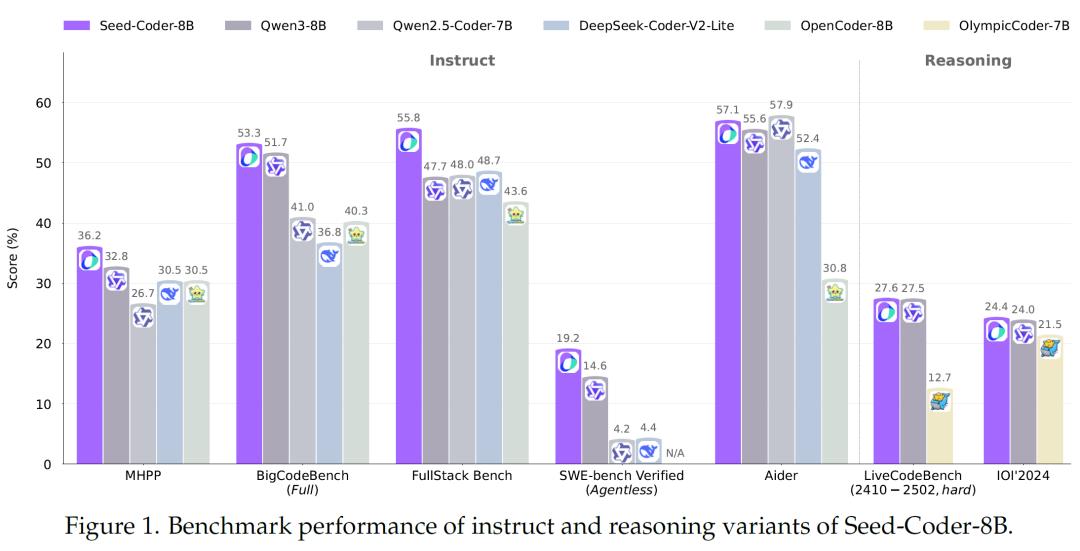
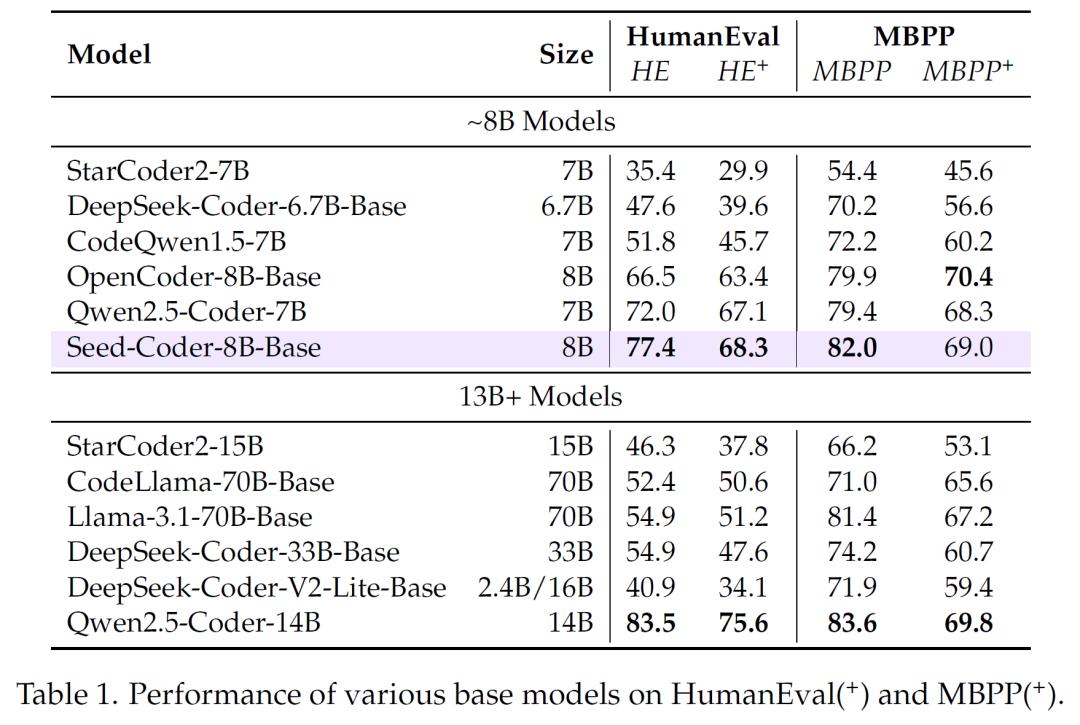
经过在多个权威基准测试中的严格评估,Seed-Coder在代码生成、代码补全、代码编辑、代码推理和软件工程任务等方面均展现出卓越的性能。在代码生成任务上,Seed-Coder-8B-Base模型在HumanEval和MBPP等基准测试中,超越了许多同规模甚至更大规模的开源模型。
在多语言代码生成能力评估中,该模型在8种主流编程语言中的7种上表现优异。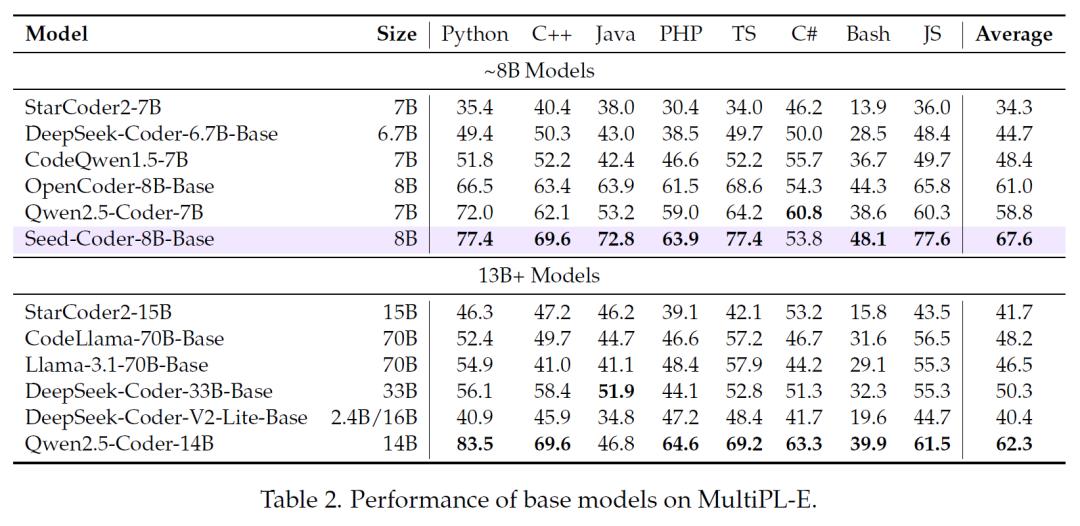
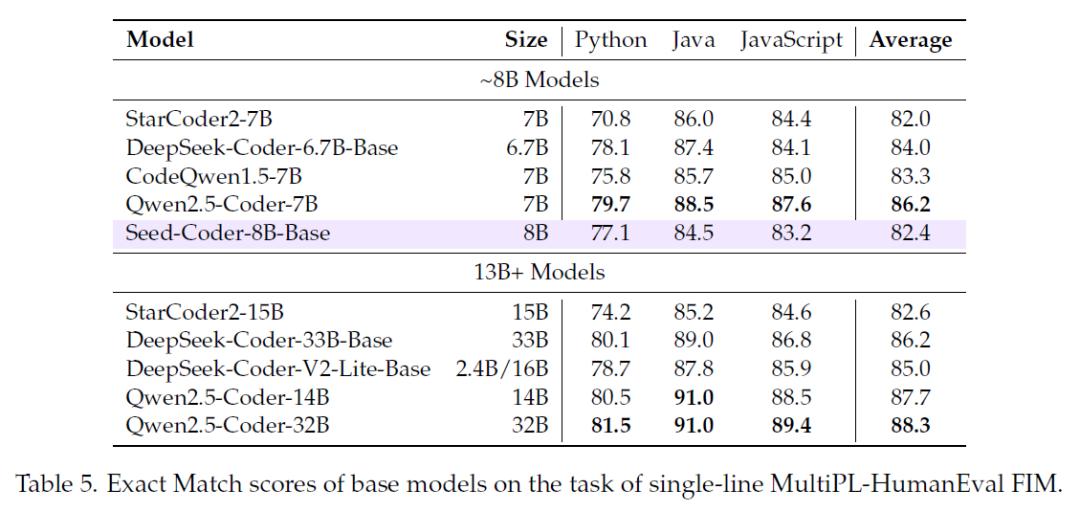
在代码补全任务中,使用CrossCodeEval、RepoEval和Single-line MultiPL-HumanEval FIM等基准进行测试,Seed-Coder-8B-Base在同规模模型中优势明显。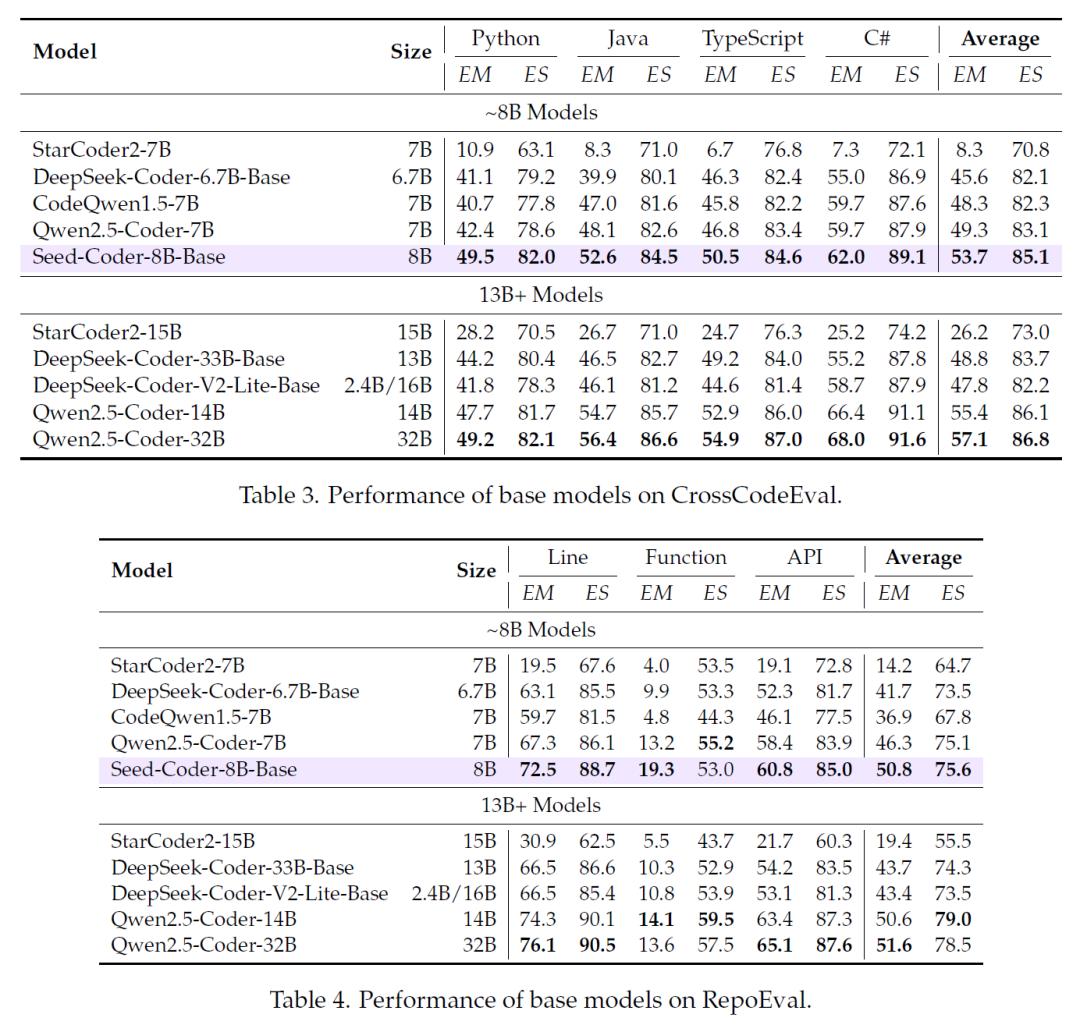
在实际应用场景中,Seed-Coder同样表现出色。在软件工程任务的评估中,面对SWE-bench Verified和Multi-SWE-bench mini等基准测试,Seed-Coder-8B-Instruct模型在解决真实世界GitHub问题和跨多种编程语言解决问题的能力上,超越了其他同规模模型,甚至在某些方面超过了更大规模的模型。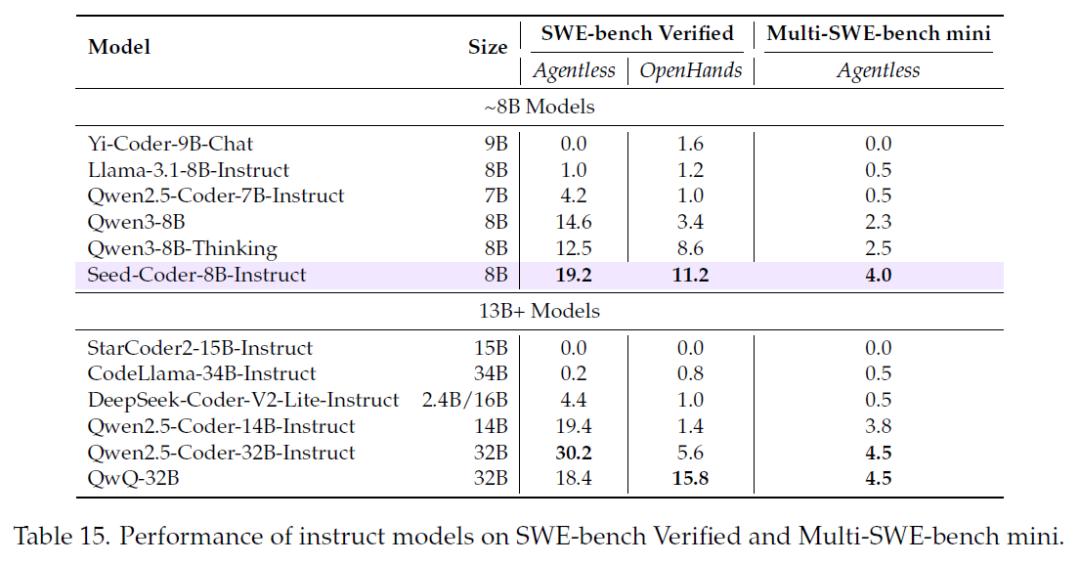
字节跳动表示,发布Seed-Coder旨在为开源社区提供有价值的研究见解。Seed-Coder目前主要专注于编码任务,在通用自然语言理解和处理更广泛任务方面存在一定局限性。未来,未来,字节跳动计划进一步改进模型,提升其在不同规模下的编码能力,为开发者和研究人员带来更多惊喜。
参考资料:https://huggingface.co/posts/merterbak/312981101349702
 豫公网安备41010702003375号
豫公网安备41010702003375号