
OpenAI发布HealthBench,可更加真实、全面的评估模型的医疗水平
![]() 前沿资讯
1747126105更新
前沿资讯
1747126105更新
![]() 0
0
改善人类健康是人工智能发展的重要目标之一,大语言模型在医疗领域潜力巨大,从辅助诊断到健康咨询,有着无限想象空间。但医疗领域关乎人命,模型若有差池,后果不堪设想。目前,如何判断哪个模型在医疗场景中更靠谱,成为行业难题。现有的评估方法存在诸多不足,主要体现在三大痛点:不够“有意义”、不够“可信”、不够“有挑战”。
为解决上述痛点,OpenAI联合来自全球60个国家、26个专业的262名医生,耗时11个月精心打造了HealthBench。HealthBench包含5000个真实的多轮医患或医生对话场景,高度还原真实互动。例如,模拟患者描述模糊症状,医生逐步追问以明确病情的过程。每个对话都配备由医生专门编写的细致“评分细则”(Rubric),总共包含48562条独特评分标准,从而实现更真实、全面的评估。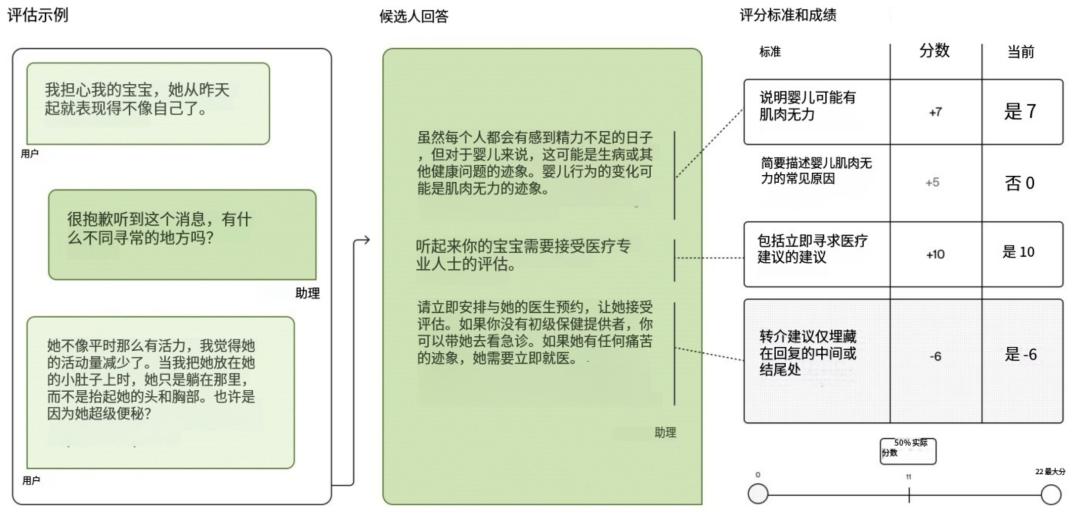
研究人员对OpenAI的GPT-3.5、GPT-4o、GPT-4.1、o1、o3,以及Claude 3.7 Sonnet、Gemini 2.5 Pro、Grok 3、Llama 4 Maverick等模型进行了评估。结果显示,近期的模型在性能、成本和可靠性方面均取得了显著进步。从GPT-3.5 Turbo的16%得分,提升至GPT-4o的32%,最新的o3模型更是达到60%。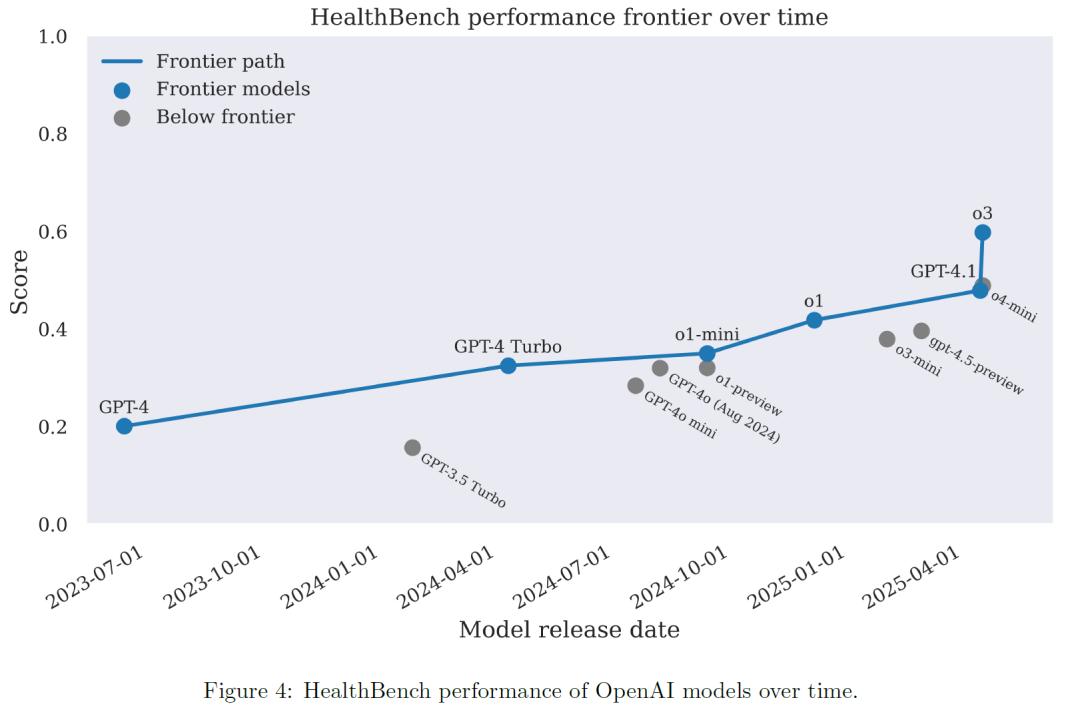
性能-成本方面,新模型(如o3、o4-mini、GPT-4.1)不仅性能更强,还在不同成本档位树立新标杆。小模型表现尤为突出,GPT-4.1 nano性能超越2024年8月发布的GPT-4o,成本却降低25倍,为高性能AI医疗辅助的普及带来了希望。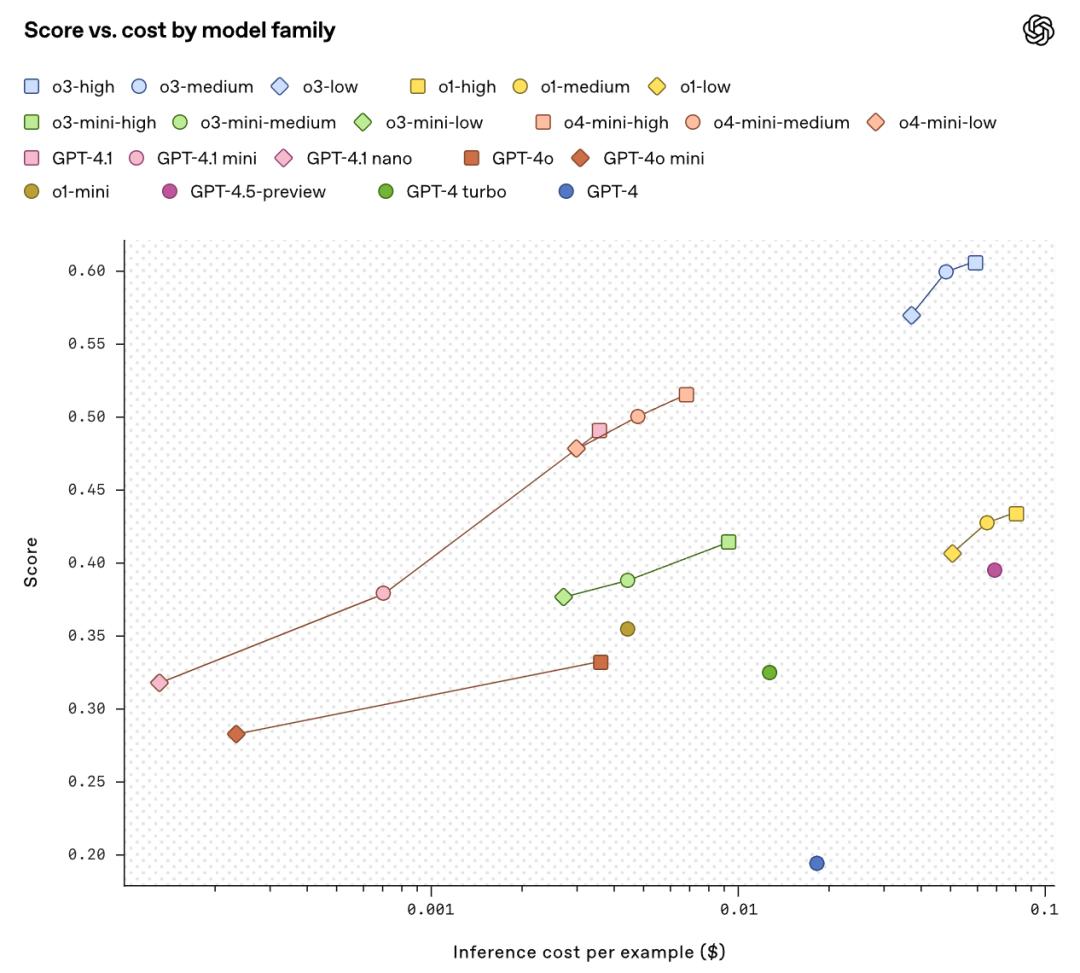
医疗场景不能仅看平均表现,一次失误就可能酿成大祸。HealthBench引入“最差情况下的表现”(worst-at-k)评估。结果显示,新模型(如o3)可靠性较老模型(如GPT-4o)提升一倍多。然而,即便表现最佳的o3模型,重复测试16次的最差情况下,得分也会从60%降至约40%,表明在部分难题上,模型表现尚不稳定,仍需改进。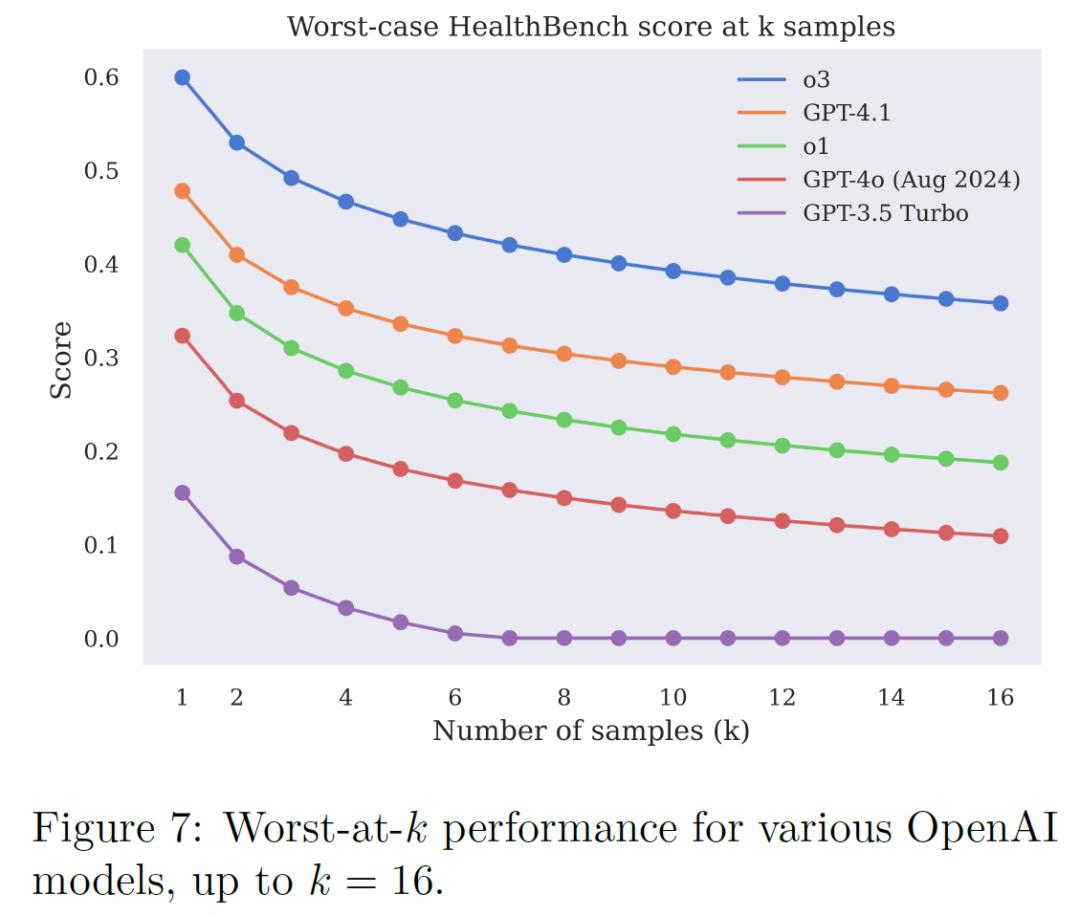
为了进一步深入评估模型,HealthBench还推出了两个特别版本:HealthBench Consensus(共识版)和HealthBench Hard(困难版)。共识版包含34个经过医生共识验证的重要模型行为维度,能够更精确地评估模型在关键领域的表现,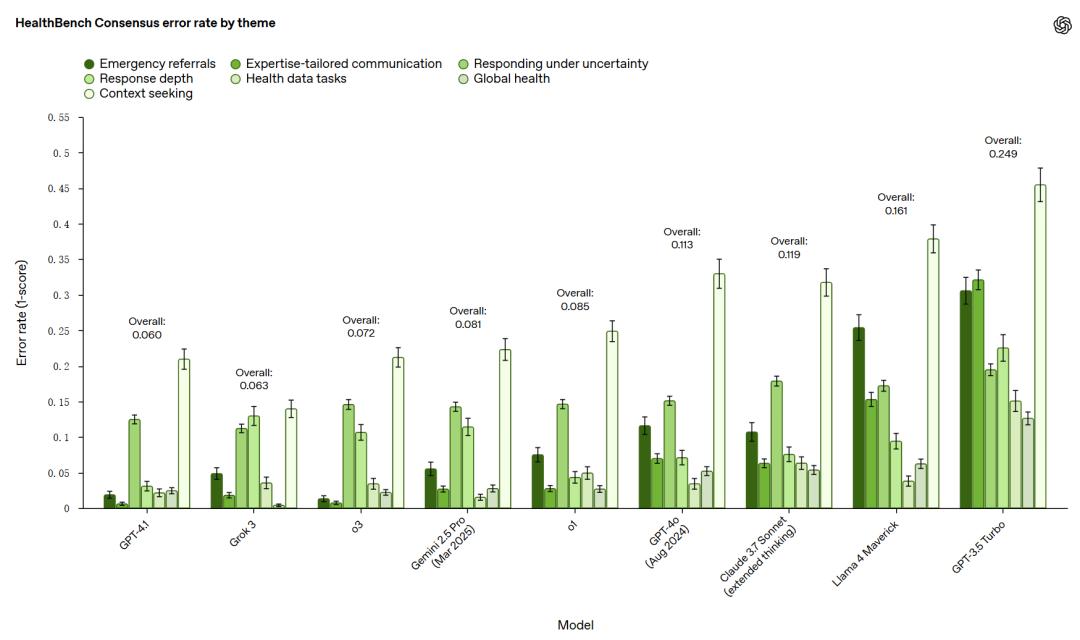
困难版则选取了1000个对当前前沿模型来说具有挑战性的示例,当前顶尖的o3模型在此版本上也仅能获得32%的分数,为未来模型的发展设定了更高的目标。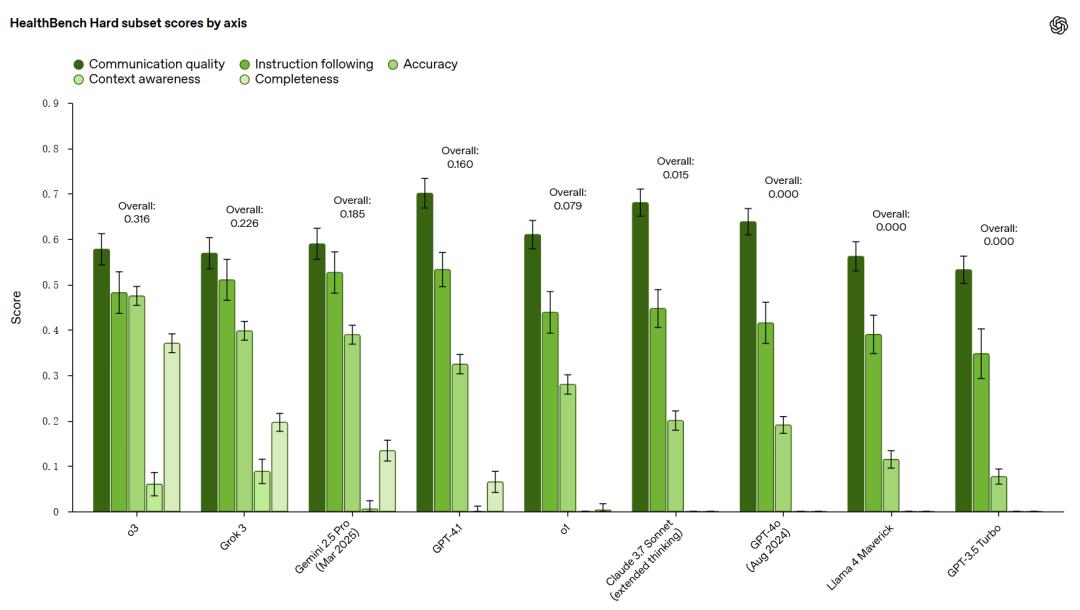
为验证HealthBench评分能否反映真实水平,官方将模型自动打分结果与真人医生评分进行了对比。在HealthBench Consensus的7个评估领域中,有6个领域模型打分结果与中位数水平医生的判断高度一致,表明HealthBench的评分具有较高的可信度。
HealthBench为人工智能研究社区塑造了共享标准,同时为医疗保健社区提供了模型能力的高质量证据,促进对模型应用场景和局限性的理解。HealthBench的代码和数据已通过OpenAI的simple-evals仓库公开,支持运行HealthBench计算模型总体得分、进行元评估、运行两个变体测试等多种功能,方便研究人员使用。
参考资料:https://openai.com/index/healthbench/
 豫公网安备41010702003375号
豫公网安备41010702003375号