
字节跳动推出多模态基础模型Seed1.5-VL,性能超越众多竞品
![]() 前沿资讯
1747189051更新
前沿资讯
1747189051更新
![]() 0
0
视觉语言模型已成为实现通用人工智能在虚拟和物理环境中感知、推理和行动的基础范式。通过统一视觉和文本模态,其在多模态推理、图像编辑、GUI代理、自动驾驶、机器人等领域推动了研究进展。不过,当前的视觉语言模型在人类水平的通用性方面仍存在较大差距,尤其在3D空间理解、对象计数、想象性视觉推理和交互式游戏等任务中表现不足。字节跳动的研究团队针对这些问题,开发了Seed1.5-VL模型,旨在提升多模态理解和推理的通用性。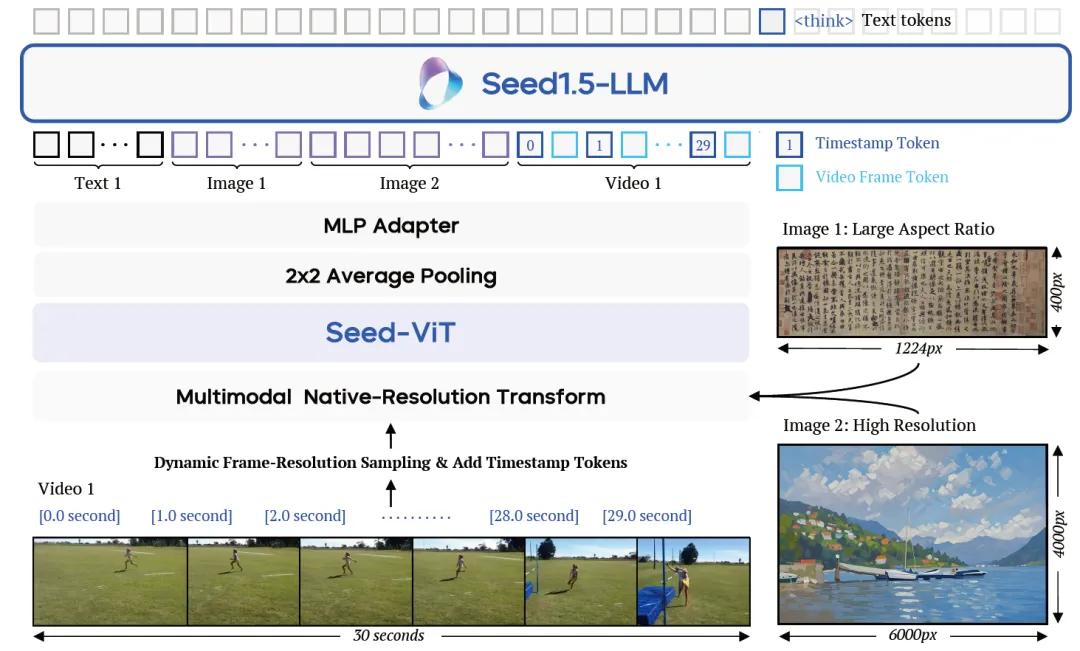
Seed1.5-VL由一个5.32亿参数的视觉编码器和一个具有200亿活跃参数的混合专家(MoE)语言模型组成。架构相对紧凑,但它在60个公共基准测试中的38个中达到了最先进的性能,涵盖视觉推理、视频理解、图形用户界面(GUI)控制等多个领域。在一些以智能体为中心的任务中,如GUI控制和游戏玩法,Seed1.5-VL的表现优于包括OpenAI CUA和Claude 3.7在内的领先多模态系统。
在模型设计方面,Seed1.5-VL视觉编码器支持动态图像分辨率,并使用2D RoPE进行位置编码,能够灵活适应不同尺寸的图像。同时,为了处理视频输入,模型引入了动态帧分辨率采样策略,可根据内容复杂度和任务需求调整采样帧率和分辨率,并在每个视频帧前添加时间戳标记,增强对动态视觉内容的理解。
训练数据的多样性和质量是提升模型能力的关键。为此,字节跳动构建的数据集包含数万亿的多模态标记,涵盖图像、视频、文本和人机交互数据等多种类型。针对不同的能力需求,数据被分类处理,通过筛选和增强技术处理通用图像文本对,利用合成数据提升光学字符识别(OCR)能力等,有效解决了多模态数据标注稀缺的问题。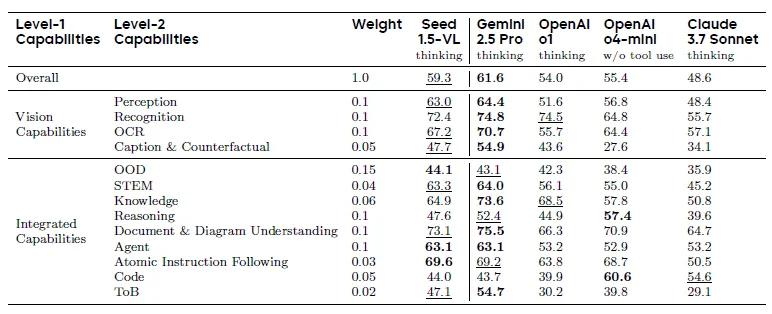
在训练过程中,Seed1.5-VL采用了分阶段的训练方法,包括预训练和后训练。预训练阶段通过多种任务和数据类型,使模型学习到广泛的视觉知识和核心视觉能力,后训练阶段则通过监督微调(SFT)和强化学习(RL),结合人类反馈和可验证的奖励信号,进一步提升模型的指令跟随和推理能力。此外,字节跳动还开发了一系列训练优化技术,如混合并行ism、工作负载平衡和并行感知数据加载等,提高了训练效率和稳定性。
未来,字节跳动将继续致力于模型的改进,计划通过增加模型参数和训练计算量,以及探索将图像生成能力融入基础模型等方式,进一步提升Seed1.5-VL的性能。
参考资料:https://arxiv.org/abs/2505.07062
 豫公网安备41010702003375号
豫公网安备41010702003375号