
韩科院提出ΔAttention:可在保持98.5%稀疏性的同时有效恢复准确性
![]() 前沿资讯
1748083361更新
前沿资讯
1748083361更新
![]() 1
1
Transformer的自注意力机制虽然强大,但时间复杂度随序列长度呈二次增长,导致长文本推理时计算成本极高。为降低计算负担,学界提出稀疏注意力方法,通过仅计算注意力矩阵中的部分关键元素来提升效率。然而,这类方法普遍存在性能下降问题。例如,在RULER基准测试中,采用滑动窗口的稀疏注意力模型在处理13.1万token的长序列时,准确率较全注意力模型下降超过50%。
研究团队发现,性能下降的核心原因在于稀疏计算导致注意力输出的分布偏移,这种偏移使得解码阶段的查询向量(Query)无法与预填充阶段的键向量(Key)正确对齐,尤其在需要精确检索早期信息的任务中,如UUID键值对匹配,传统稀疏方法准确率甚至降至0%。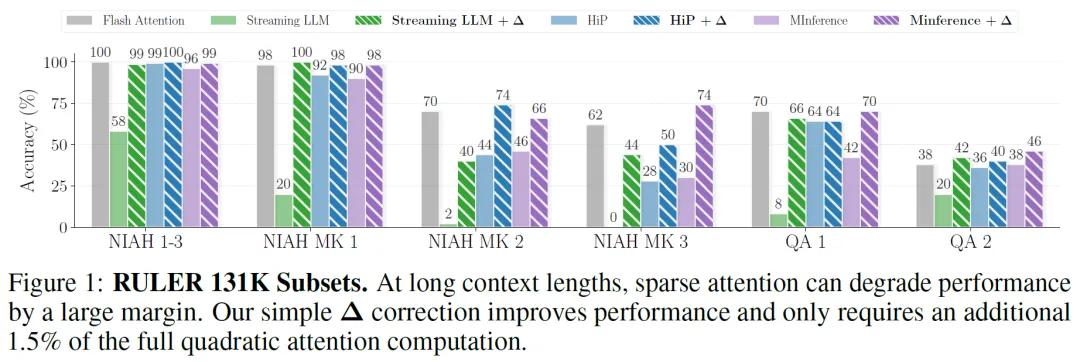
针对上述问题,韩国科学技术院(KAIST)联合DeepAuto.ai的研究团队提出ΔAttention,其核心思想是通过计算稀疏注意力与全注意力输出的差异(Δ),将稀疏输出的分布向全注意力靠拢。
具体步骤为:选取少量查询向量计算全注意力与稀疏注意力的输出差异,再将差异值重复应用于相邻查询输出以调整分布,且该方法无需修改现有稀疏注意力内核,仅在推理阶段增加轻量级后处理步骤,额外计算量仅占全注意力的1.5%。该技术的创新性在于,ΔAttention利用注意力输出的局部相似性,通过稀疏全注意力计算推断全局分布校正,可在保持98.5%稀疏性的同时有效恢复准确性。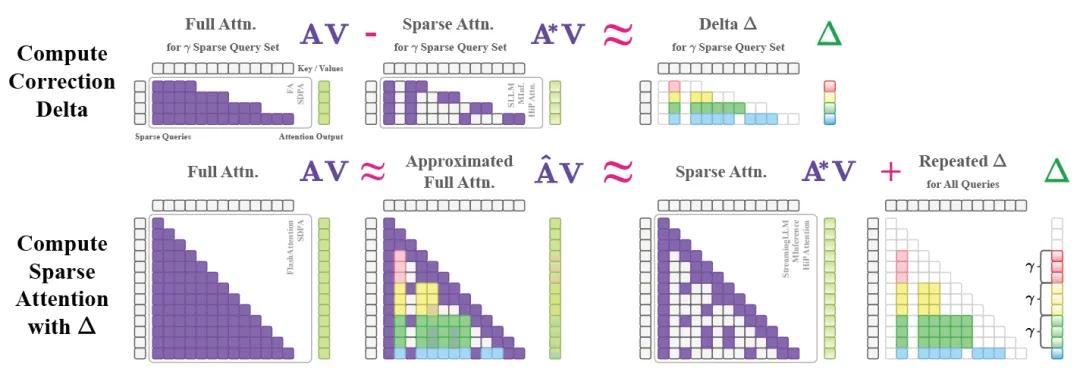
在多个基准测试中,ΔAttention展现了显著的性能提升:
RULER基准测试:在13.1万token的长序列任务中,基于滑动窗口的稀疏注意力模型(Streaming LLM)准确率从27.45%提升至64.40%,恢复了88%的全注意力性能。对于更复杂、需精确检索UUID值的MultiKey-3子集,准确率从0%提升至44%。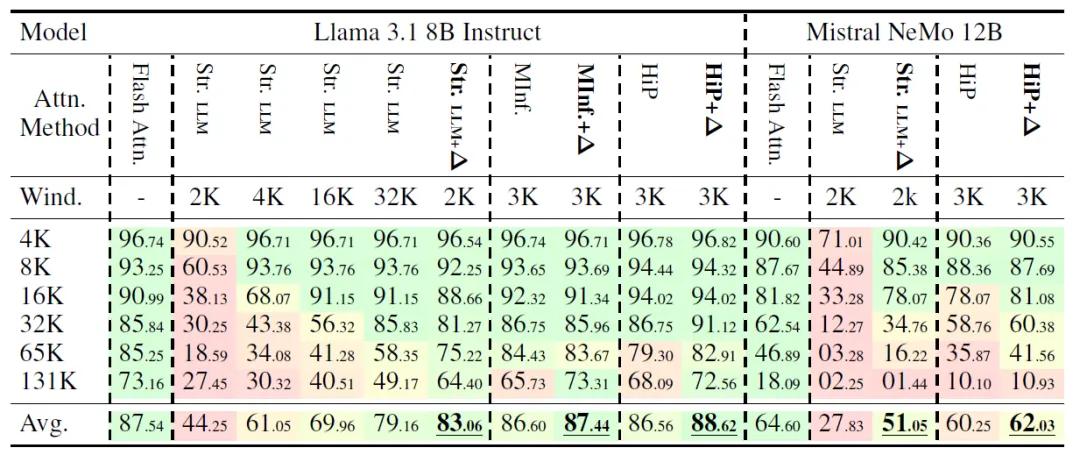
困惑度(PPL)测试:在PG19长文本问答任务中,ΔAttention将稀疏注意力的LongPPL从7.02降至5.96,接近全注意力水平(5.11),表明其在长上下文理解中能更好保留信息。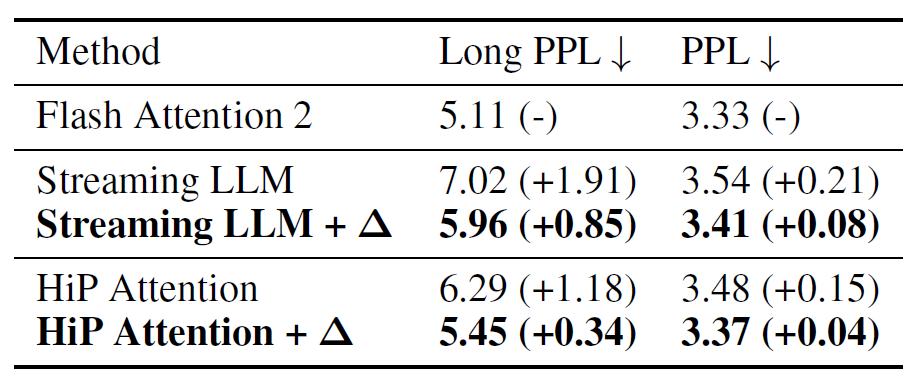
延迟优化:处理100万token时,ΔAttention结合滑动窗口的模型速度比Flash Attention 2快32倍,且额外延迟可忽略(仅增加1.5%计算量)。
此外,ΔAttention兼容性优良,可与多种稀疏注意力方法结合,如HiP、MInference,在Llama、Mistral等主流模型中均实现了平均36%的准确率提升。
该研究首次揭示了稀疏注意力分布偏移对长序列推理的影响,并提供了简单高效的解决方案。ΔAttention无需重新训练模型,可直接集成到现有推理管道中,为实际应用中的文档分析、代码生成、实时对话等长上下文场景提供了更经济高效的选择。
参考资料:https://arxiv.org/abs/2505.11254v1
 豫公网安备41010702003375号
豫公网安备41010702003375号