
谷歌推出Gemma 3n预览版,专为移动设备打造,“人人可及的智能终端”正加速到来
![]() 前沿资讯
1748247892更新
前沿资讯
1748247892更新
![]() 1
1
近日,谷歌宣布推出一款专为移动设备打造的的新一代开源AI模型:Gemma 3n预览版。Gemma 3n延续了前作Gemma 3和Gemma 3 QAT在云端与桌面端的高性能优势,首次将尖端AI能力延伸至手机、平板、笔记本等终端设备。
为实现“移动优先”的技术愿景,谷歌与高通、联发科、三星LSI等移动硬件领域领导者深度合作,共同开发了全新的AI架构。该架构针对设备端计算特性进行了全方位优化,支持极速的多模态数据处理。据悉,该架构还将使用到下一代Gemini Nano模型的升级,相关能力预计于今年晚些时候融入谷歌应用生态及设备端系统,并逐步适配Android、Chrome等主流平台。
Gemma 3n模型原始参数达50亿和80亿,但其利用了一项DeepMind研发的“逐层嵌入(PLE)”技术,动态内存占用仅为2GB和3GB,相当于20亿和40亿参数模型的内存开销,首次让大型模型在移动设备上的流畅运行成为可能。该模型还通过MatFormer训练技术,原生包含一个嵌套的最先进的20亿活跃内存占用子模型,支持动态调整性能与质量平衡。谷歌还在Gemma 3n中进一步引入了“混合匹配”功能,新增的“混合匹配”功能可从40亿参数主模型中按需生成定制化子模型,满足不同场景下的延迟与精度需求。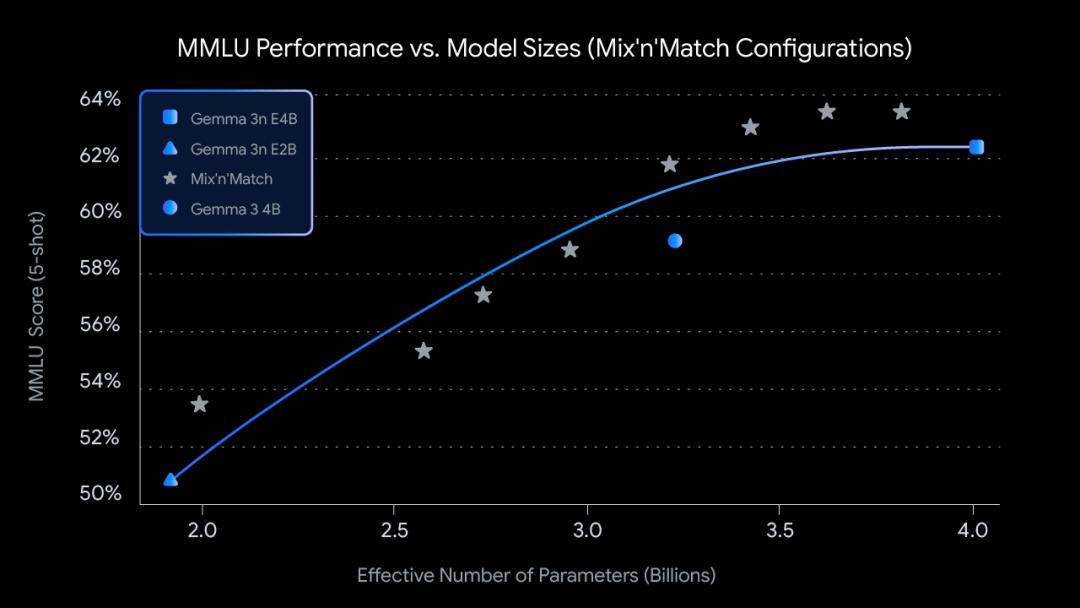
除文本、图像处理外,Gemma 3n首次深度整合音频能力,支持高质量自动语音识别(ASR)、语音翻译及跨模态交互,视频理解能力也较前代提升显著。Gemma 3n还对多语言功能进行了强化,日语、德语、韩语等语言场景中表现突出,在多语言基准测试WMT24++中,ChrF得分达50.1%,体现了优良的多元支持。
Gemma 3n的本地化运行特性为开发者开辟了三大创新方向:一是构建实时互动体验,依托本地化运行的低延迟优势,开发者可打造能理解并响应实时视觉与听觉信号的应用。二是实现多模态输入的深度理解与生成,利用模型支持音频、图像、视频、文本等多模态交错输入的能力,在设备端私密处理数据,构建能结合多模态输入实现更深入理解和上下文文本生成的应用。三是开发先进的音频中心型应用,借助模型的音频处理能力和本地化运行特点,开发实时语音转录、翻译及丰富语音驱动交互的应用,即便在无网络环境下也能可靠运行。
谷歌强调,Gemma 3n的推出不仅是谷歌在设备端AI领域的里程碑,更预示着“人人可及的智能终端”时代加速到来。
参考资料:https://developers.googleblog.com/en/introducing-gemma-3n/
 豫公网安备41010702003375号
豫公网安备41010702003375号