
上海AI实验室研究发现:随着模型推理能力的提升,其遵循用户指令的能力会下降
![]() 前沿资讯
1748253067更新
前沿资讯
1748253067更新
![]() 0
0
传统评估语言模型指令遵循能力的基准,大多面向通用场景,不太适合数学推理这类专业领域。为此,中国人民大学和上海AI实验室的研究团队联合开发了首个专门用于评估大推理模型在数学领域指令遵循能力的基准MathIF。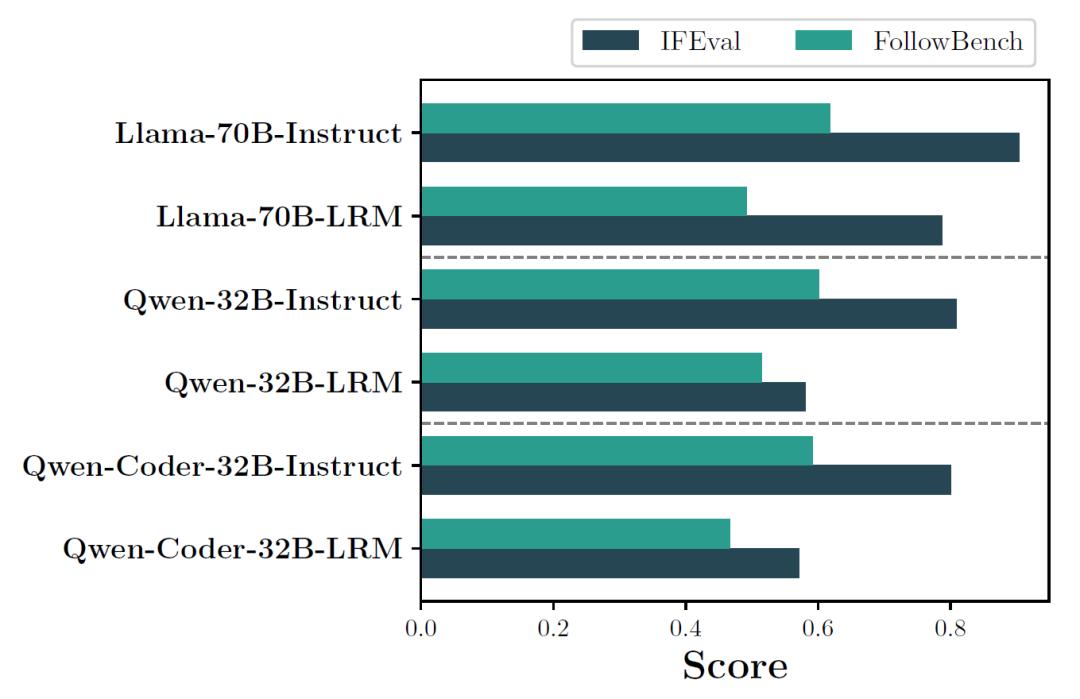
MathIF包含4类共15种可通过Python验证的约束条件,包括对回答长度的限制、必须包含特定关键词、指定格式要求等。这些约束还能组合成更复杂的双重约束(30种)和三重约束(15种),并应用于从小学到国际竞赛等不同难度的数学题,最终形成了420个高质量的评估样本。
研究团队用MathIF测试了23个主流推理模型,发现了一些普遍现象:
指令遵循表现普遍不佳:即使是表现最好的Qwen3-14B模型,在严格遵循指令方面的准确率也只有50.71%,刚过一半。很多模型,包括一些大规模模型,在执行用户指定的约束条件时,甚至连最低期望都达不到。
任务难度影响显著:模型在处理简单数学题(如GSM8K子集)时,指令遵循准确率较高,但面对高难度题目或复杂约束时,准确率明显下降,所有模型在AIME子集的平均硬准确率低于25%。
推理训练“副作用”:常见的推理导向训练策略,如监督微调(SFT)和强化学习(RL),虽然能提升模型的推理能力,但会损害其指令遵循能力,尤其是基于长思维链(CoT)蒸馏训练的模型,指令遵循能力退化更明显,部分模型的硬准确率从17%左右降至个位数,数学解题正确率也大幅下降。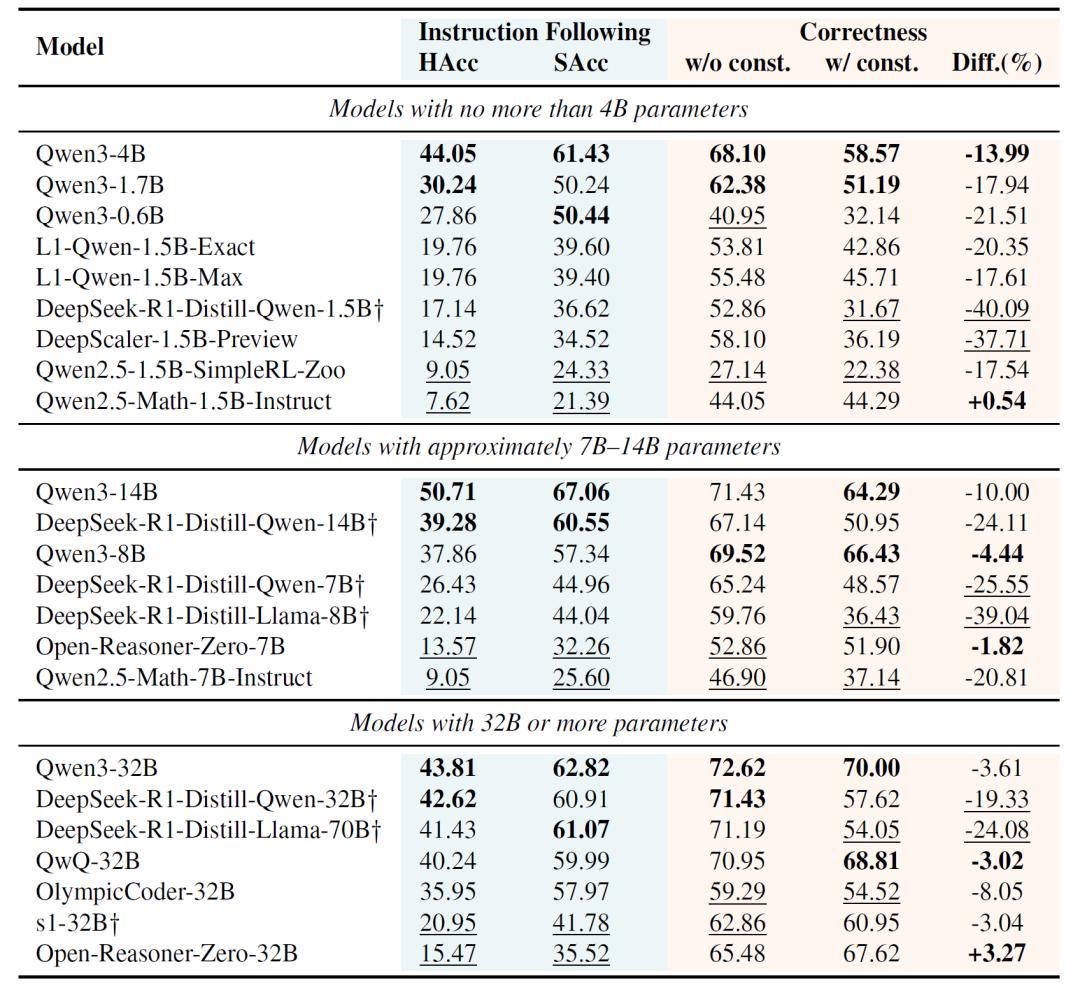
研究发现,思维链(CoT)的长度是影响模型指令遵循能力的重要因素。当模型生成的推理步骤较长时,用户指令与最终答案之间的“距离”变远,模型容易忽略或偏离指令。实验显示,随着CoT长度增加,所有测试模型的指令遵循准确率均呈下降趋势,最长推理链组的准确率比最短组低约20%。
不过,一些设计细节可能缓解这一问题。例如,使用特殊标记的(如“<|FunctionCallBegin|>”和“<|FunctionCallEnd|>”)显式分离推理过程和答案的Qwen3系列模型,在指令遵循方面表现更好,表明结构化输出有助于模型更好地关注指令。
这项研究揭示了当前大模型训练中的一个根本矛盾:提升推理能力往往需要以牺牲指令遵循能力为代价。当模型被强制遵循指令时,其数学解题正确率平均会下降10%-20%,而专注于提升推理能力的模型,在复杂约束下的指令遵循准确率又难以令人满意。
研究团队认为,这一发现提醒研究者需要重新思考模型训练范式,不能只关注推理能力,还需在训练目标中加入对指令的“感知”机制,让模型在智能提升的同时,保持对用户意图的可控性。
参考资料:https://arxiv.org/abs/2505.14810
 豫公网安备41010702003375号
豫公网安备41010702003375号