
强化学习技术再升级!加州大学伯克利分校提出INTUITOR框架,距离自主进化的AI系统又近了一步
![]() 前沿资讯
1748423358更新
前沿资讯
1748423358更新
![]() 0
0
如何进一步提升大语言模型的复杂推理能力一直是一个研究难点。传统方法如基于人类反馈的强化学习(RLHF)依赖大量人工标注,成本高昂且易引入偏见,另一种基于可验证奖励的强化学习(RLVR)虽避免了人工标注,但高度依赖特定领域的验证器和标准答案,难以泛化到普适场景。
在此背景下,加州大学伯克利分校联合耶鲁大学的研究团队提出了一种全新的强化学习范式:内部反馈强化学习(RLIF),并开发了基于该范式的方法INTUITOR。其核心目标是让大模型仅通过自身生成的内在信号进行学习,彻底摆脱对外部奖励和标注数据的依赖,为构建自主进化的AI系统开辟了新路径。
INTUITOR的创新之处在于将模型自身的自信度作为唯一的奖励信号,这一指标被称为“自我确定性”(self-certainty),其计算基于模型输出分布与均匀分布的KL散度均值。简单来说,模型对正确答案的输出分布会更集中,从而具有更高的自我确定性值,而对不确定的问题,输出分布更分散,自我确定性值较低。
具体实现中,INTUITOR以群组相对策略优化(GRPO)算法为基础,将传统GRPO中的外部奖励替换为自我确定性分数。训练流程如下:
第一阶段:对于每个输入查询,模型生成多个候选输出;
第二阶段:计算每个候选的自我确定性分数,并通过标准化处理得到优势估计值;
第三阶段:使用策略梯度算法更新模型参数,鼓励生成高自信度的输出。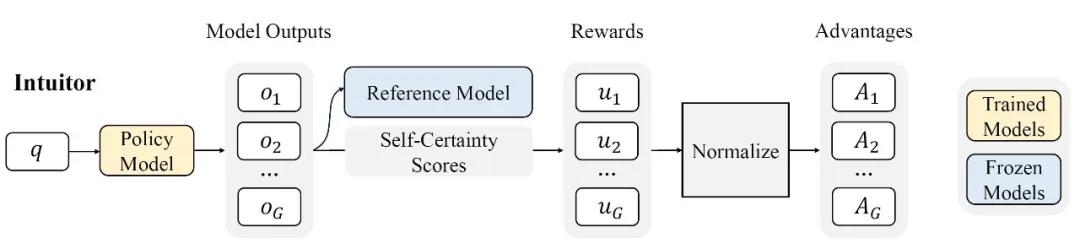
这种机制使得INTUITOR无需任何人工标注或领域特定验证器,仅通过模型自身的内部信号即可完成端到端的自主学习。研究表明,自我确定性相比传统的熵或困惑度指标更能可靠反映输出质量,且不易受生成长度的影响,为模型提供了稳定的优化方向。
研究团队在多个基准测试中对INTUITOR进行了全面评估,结果显示,其在数学推理、代码生成和指令遵循等任务中表现卓越,甚至在跨领域泛化能力上超越了传统的RLVR方法。
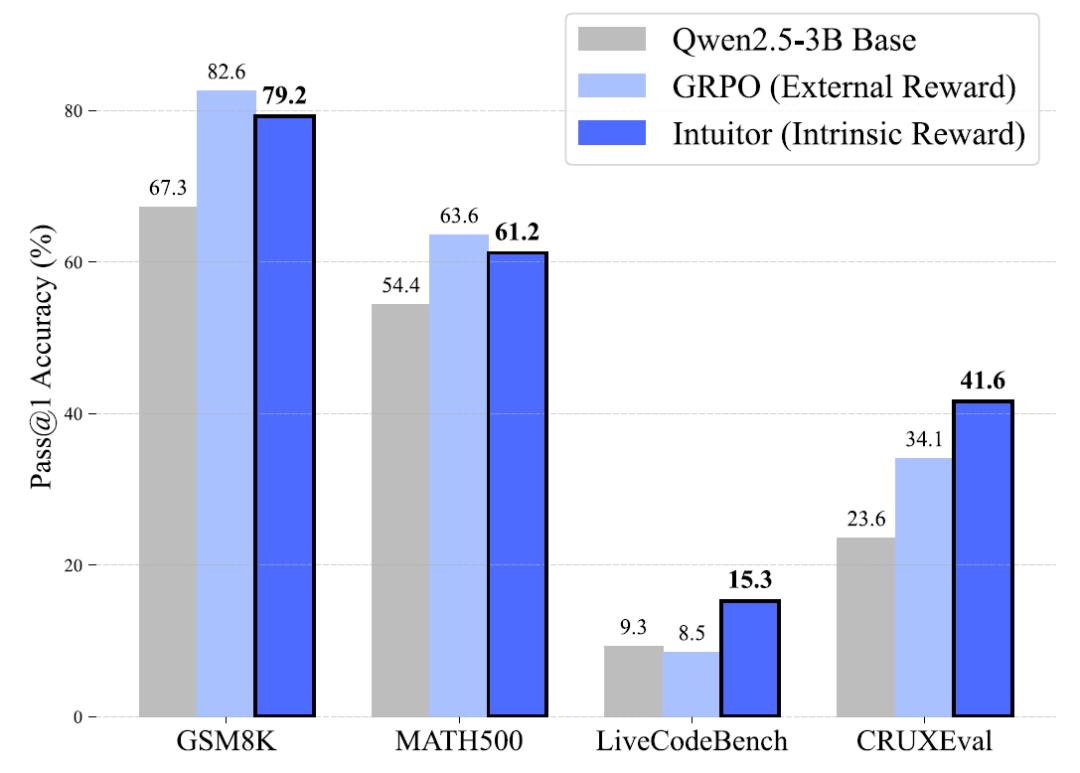
数学推理:无需标准答案的精准求解
在包含7500道数学题的MATH数据集上,INTUITOR与使用标准答案的GRPO性能相当。GSM8K基准测试中,INTUITOR在Qwen2.5-3B模型上的准确率达79.2%,接近GRPO的82.0%。MATH500基准测试中,INTUITOR准确率为61.2%,与GRPO的63.6%差距极小。而且,INTUITOR在训练过程中完全不使用黄金答案,仅通过自我确定性信号优化,证明了内在信号足以驱动复杂推理能力的提升。
跨领域泛化:从数学到代码的无缝迁移
当在MATH数据集上训练后,INTUITOR在LiveCodeBench(LCB)和CRUXEval-O等代码基准测试中的表现远超GRPO。在LiveCodeBench基准测试中,INTUITOR实现了15.3%的准确率,较GRPO的8.6%提升近80%。在CRUXEval-O基准测试中,INTUITOR准确率达41.6%,显著高于GRPO的29.9%。进一步分析发现,INTUITOR训练的模型在生成代码前会自发产生自然语言推理过程,如问题分解、算法规划,这种结构化思维使其能够更好地泛化到未训练过的任务类型。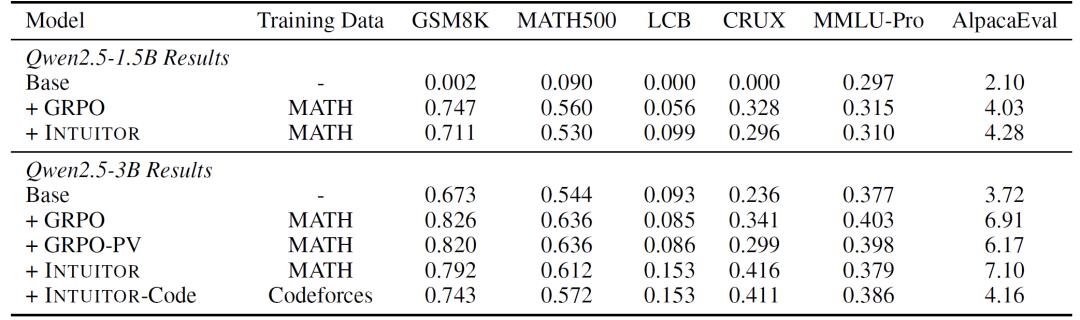
INTUITOR的成功源于对大模型内在能力的深度挖掘,主要体现在以下三个方面:
1.在线自我确定性:防止奖励博弈的动态机制
传统离线奖励模型易被模型添加无关内容提升奖励分数,而INTUITOR采用在线自我确定性评估,奖励信号随模型参数同步更新,实验表明,离线评估在训练后期出现明显的响应长度激增但准确率暴跌,而在线评估始终保持稳定,确保模型优化方向与真实能力提升一致。
2.连续型奖励信号:驱动结构化推理的涌现
与RLVR的二元奖励(正确/错误)不同,自我确定性是连续型信号,能够反映模型在生成过程中的每一步自信度变化。这种特性鼓励模型发展出更细致的推理链条。研究发现,INTUITOR训练的模型在早期训练阶段(第10步)即在GSM8K基准上超越GRPO,显示出更强的初始学习效率。
3.轻量级框架:兼容多种模型与任务
INTUITOR无需复杂的基础设施,仅需输入提示即可运行,且易于集成到现有强化学习框架中。实验显示,其在Qwen2.5系列(1.5B/3B/7B/14B)及Llama-3.2-3B等模型上均有效,甚至在参数规模较小的模型上也能激活推理能力。
INTUITOR的提出标志着大模型训练从“依赖外部监督”向“自主内在进化”的重要转变。其核心价值不仅在于摆脱数据标注的成本限制,更在于为模型在人类难以直接评估的复杂领域中的应用奠定了基础。
参考资料:https://arxiv.org/abs/2505.19590
 豫公网安备41010702003375号
豫公网安备41010702003375号