
新型训练框架Thinker:让语言模型学会了 “快慢结合”,显著减少了“过度反思”
![]() 前沿资讯
1749024235更新
前沿资讯
1749024235更新
![]() 0
0
语言模型在数学、编程等问答任务中展现出了一定的推理能力,通过强化学习(RL)优化后性能更有提升。然而,现有模型在长上下文推理时存在明显缺陷。像DeepSeek R1等模型,在推理时频繁出现过度回溯和反复验证的情况,这不仅导致推理响应拖沓,还极大地消耗了计算资源。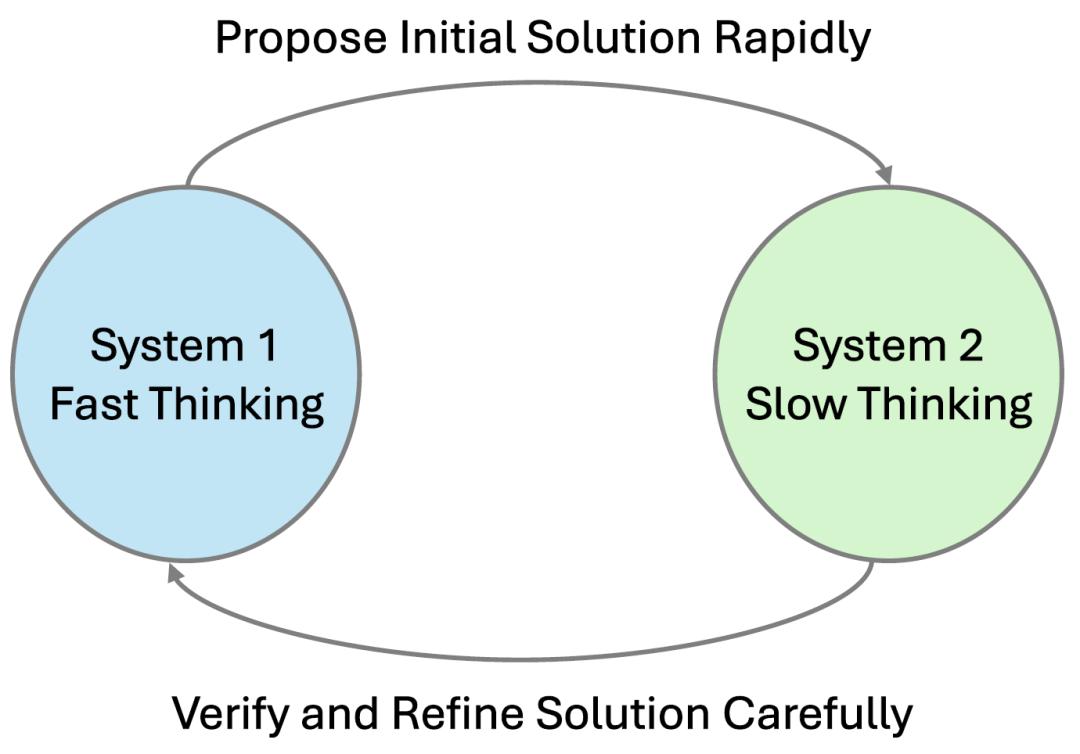
从本质上讲,传统的强化学习方法,如近端策略优化(PPO)和广义优势估计近端策略优化(GRPO),在面对大语言模型推理时,难以实现精准的时序奖励分配。这就使得模型在推理过程中,缺乏一种能够快速识别有效搜索路径的“直觉”能力,同时也无法自信且准确地评估自身推理路径的正确性。在复杂问题的推理上,模型常常陷入无效的思考循环,无法高效地得出准确答案,严重限制了大语言模型在实际复杂场景中的应用。
针对此问题,来自DualityRL的Stephen Chung和Wenyu Du与上海AI实验室的Jie Fu共同提出了一种称为Thinker的新型训练框架,可以让语言模型学会“快慢结合”的高效推理。Thinker任务的设计灵感来源于心理学中的“双过程理论”。该理论指出,人类的思维存在两种模式:系统1是快速、自动且基于直觉的决策模式,系统2则是慢速、逻辑且需要深度分析的推理模式。这两种模式相互协作,共同帮助人类处理各种复杂的认知任务。该框架将问答分解为四个阶段,以训练模型的不同能力。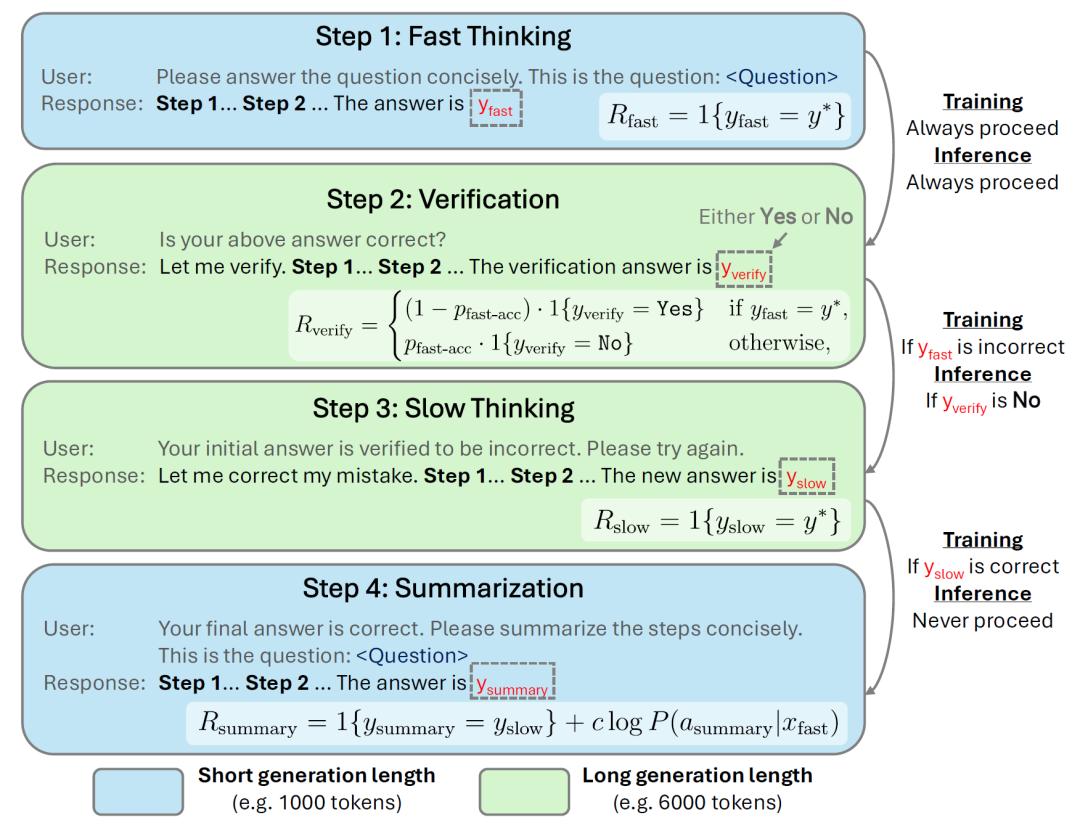
快速思考(Fast Thinking):在这一阶段,模型被设定了严格的token预算限制,需要在有限的资源下,快速生成一个初始答案。此阶段旨在强化模型的“直觉”能力,迫使模型在短时间内筛选出最有可能的解题路径,奖励机制也相对简洁,仅依据初始答案的正确性给予二进制奖励。这种设计促使模型不断优化自身的快速搜索能力,在大量的训练中逐渐培养出对问题的敏锐直觉。
验证(Verification):当模型完成快速思考并生成初始答案后,进入验证阶段。此时,模型被给予相对充足的token预算,其任务是评估之前生成的初始答案是否正确,输出结果为“是”或“否”。这一阶段专注于训练模型的评估能力,如果初始答案通过验证,整个推理流程将终止,从而节省了不必要的计算成本。若未通过验证,则引导模型进入下一阶段。在奖励设置上,为了避免模型盲目输出单一结果,研究团队精心平衡了正负样本的权重,确保模型能够认真对待验证任务,提升评估的准确性。
慢速思考(Slow Thinking):若验证阶段判定初始答案错误,模型便进入慢速思考阶段。同样拥有长token预算,模型需要重新对问题进行深入推理,生成新的答案。这一阶段模拟了人类思维中系统2的深度分析过程,模型有足够的资源和时间去反思之前的错误,尝试不同的推理思路,通过反复的思考和修正,提升解决复杂问题的能力。奖励机制也很明确,只有当新生成的答案正确时,模型才会获得奖励,这种强激励促使模型从失败中学习,不断优化慢速思考的推理策略。
总结(Summarization):总结阶段要求模型将慢速思考阶段的详细推理过程提炼为简洁明了的步骤,同时再次限制token预算。其目的在于强化模型的知识整合能力,将成功的推理模式转化为可复用的直觉经验。奖励机制结合了答案的一致性和生成概率两个因素。一方面,总结的内容需要与慢速思考阶段的推理保持一致,确保提炼的准确性。另一方面,考虑生成概率是为了避免模型为了追求简洁而输出无意义的简短回答,促使模型在简洁性和准确性之间找到平衡。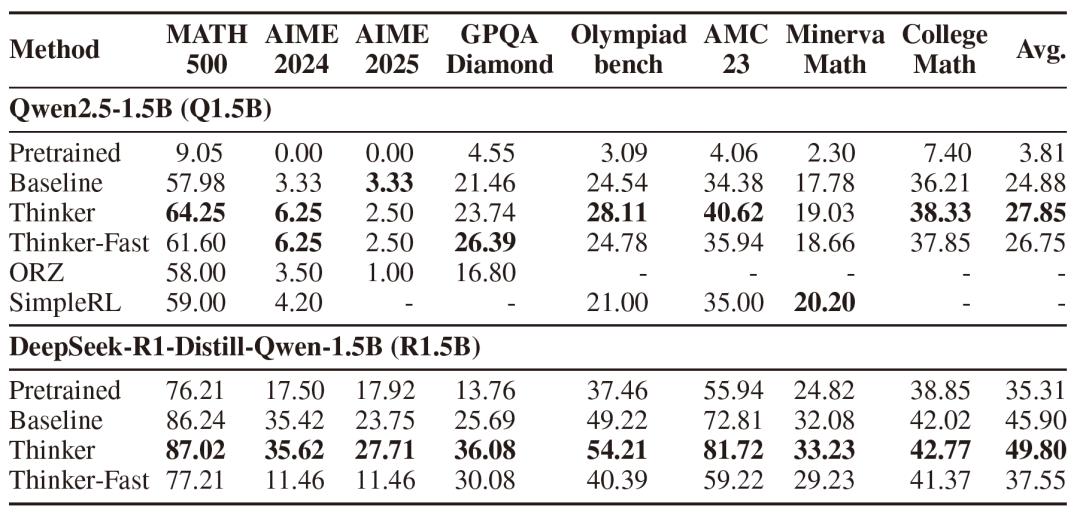
研究团队在Qwen2.5-1.5B和DeepSeek-R1-Distill-Qwen-1.5B这两款模型上进行了全面的实验。实验结果显示,经过Thinker任务训练的模型,在准确性方面有了显著提升。对于Qwen2.5-1.5B模型,其平均准确率从基线的24.9%提升至27.9%。DeepSeek-R1-Distill-Qwen-1.5B模型的准确率也从45.9%提升到了49.8%。
除了准确性,Thinker框架在优化模型推理效率方面也成效显著。通过对模型推理过程的深入分析发现,经过Thinker任务训练的模型在验证和慢速思考阶段,“过度反思”的行为明显减少,推理过程变得更加直接、高效。益于Thinker任务各阶段明确的目标和奖励机制,引导模型学会更加果断地选择推理路径,避免了在无效的思考上浪费过多时间。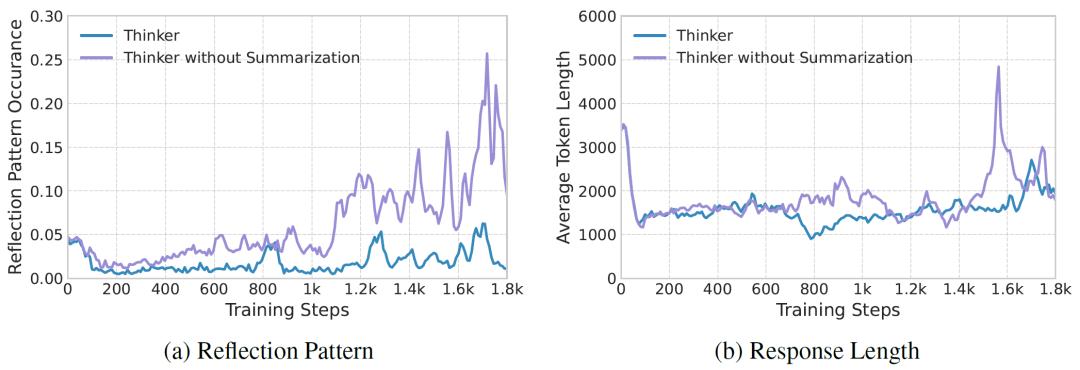
在总结阶段,模型通过提炼精简步骤,将复杂的推理过程转化为简洁的经验,进一步促进了模型“直觉-推理”正向循环的形成。当模型再次遇到类似问题时,能够凭借总结阶段形成的直觉经验,更快地找到有效的推理方向,从而大大提高了整体的推理效率。
Thinker框架将环境设计与强化学习结合,通过结构化的多阶段任务引导模型自主优化推理策略,相较于传统QA任务仅依赖最终答案反馈,该框架为模型提供了更细致的学习信号,推动直觉与逻辑推理的协同进化。
参考资料:https://arxiv.org/abs/2505.21097
 豫公网安备41010702003375号
豫公网安备41010702003375号