
OpenAI研究了人类和AI合作时的 “知识转移” 问题,强调:AI只会做题不行,还得提升“教别人” 的能力
![]() 前沿资讯
1749543726更新
前沿资讯
1749543726更新
![]() 0
0
当AI变得越来越聪明,它是否也能更好地将知识传授给人类?成为合格的“老师”?为回答这一问题,OpenAI与普林斯顿大学、斯坦福大学的研究人员联合提出了一个名为“KITE”(知识整合和转移评估)的评估框架,并设计了一项大规模人类实验,首次系统性地量化了人机协作中的知识转移能力。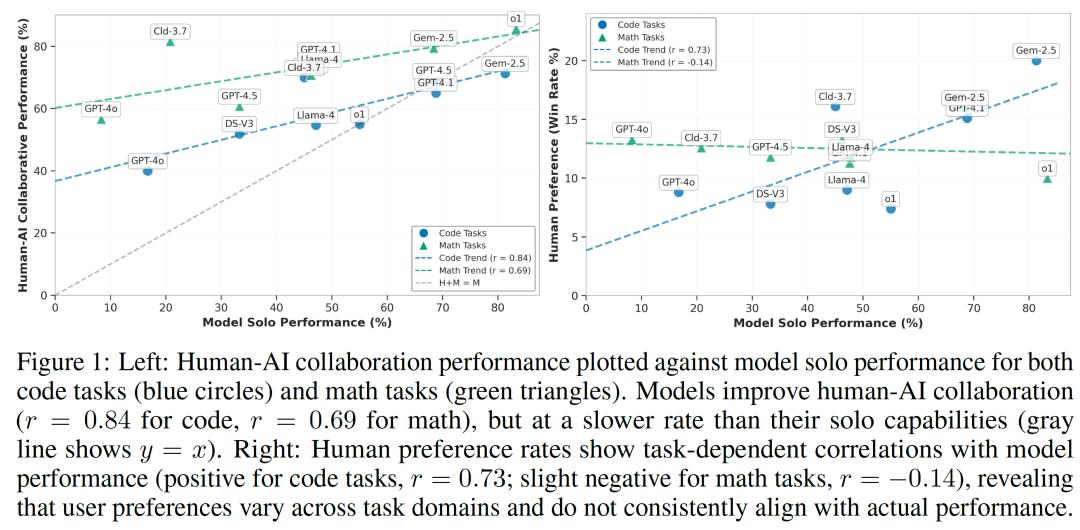
研究采用了“协作构思 + 独立完成”的双阶段设计。118名参与者分别在编程与数学任务上与AI模型展开交流。在第一阶段,参与者与模型开放式对话,共同探讨解题思路与策略。模型被禁止生成代码、计算结果或明确答案,从而确保人类只能通过理解其解释来获得帮助。在第二阶段,参与者需完全独立完成同一道题,不得访问AI提示或历史聊天记录。
研究涵盖了8个主流语言模型,包括GPT-4.1、GPT-4o、GPT-4.5-preview、Claude-3.7-Sonnet、Gemini-2.5-Pro、DeepSeek-V3、LLaMA-4-Maverick与o1。所有模型在零样本(zero-shot)设定下进行测试,即不做额外指令优化,以更真实地模拟日常用户与AI的互动方式。每个模型与参与者随机配对,并基于任务难度与人类技能等级动态匹配题目,从而确保任务在略高于用户能力水平的“学习区”内。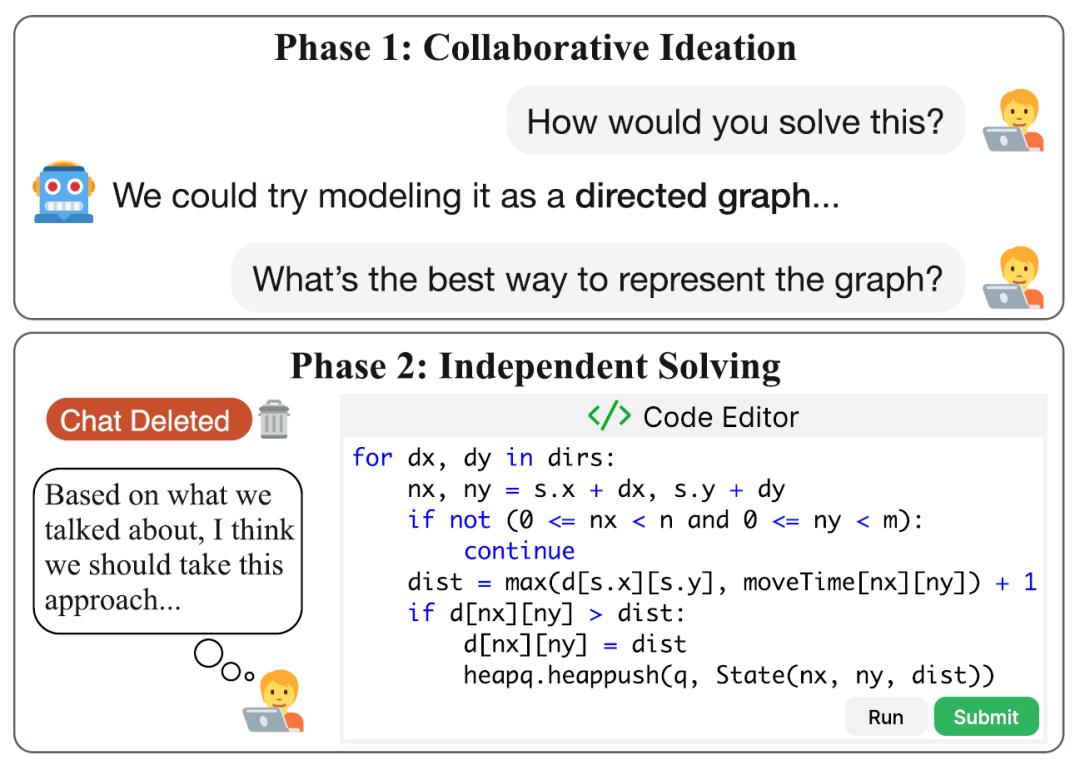
实验结果显示:模型的独立推理能力与人类学习成效之间的关系并不线性。虽然总体趋势是模型越强,人机合作效果越好,但也有多个例外。例如,Gemini-2.5-Pro在代码任务中独立表现最好,准确率达81.3%,但在人机合作中却出现-10%的性能差值。Claude-3.7-Sonnet和GPT-4o虽然独立表现中等,却显著提升了用户的成功率,尤其在数学任务中表现突出,说明这些模型更擅长将复杂推理以人类可理解的方式进行“投射”。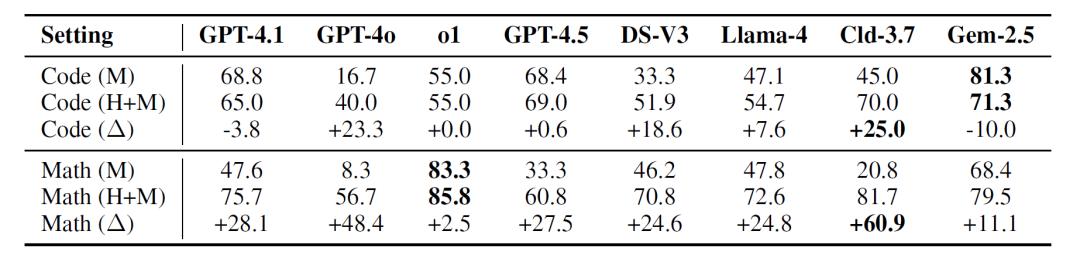
研究者进一步分析了参与者对模型的主观偏好,发现这些偏好并不总是与实际帮助强度一致。在数学任务中,用户更看重模型解释的通俗性与互动性,一些表现优异的模型因表达过于形式主义、难以被用户理解而遭到冷落。相比之下,能够使用类比、分步引导或通俗语言的模型更易被接受。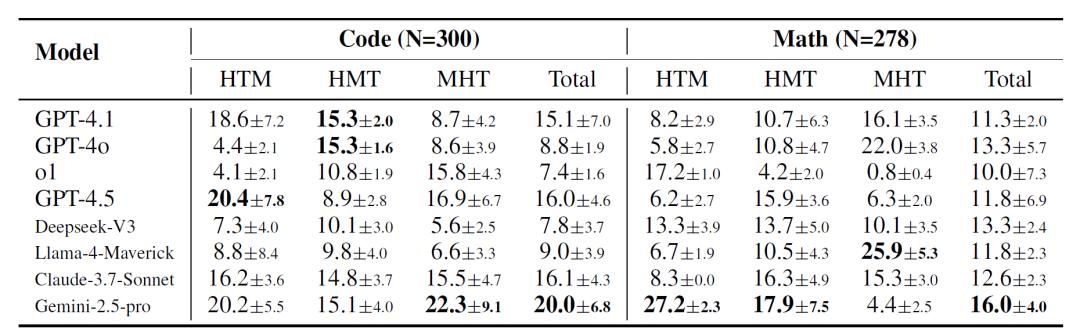
此外,参与者技能水平对合作质量的影响也显现出分层结构。在HTM(模型技能 > 人类技能 > 任务难度)设置下,像Gemini-2.5-Pro这类主动提出确认性问题、引导式互动的模型往往更受欢迎。而在MHT(人类技能 > 模型技能 > 任务难度)结构中,用户反而更偏好模型简洁直接、快速跟进建议,避免啰嗦冗余。这一现象说明了“适配型沟通”在知识传递中的重要性,不同的用户需要不同的引导策略。
最后,研究人员强调,AI只会做题不行,还得专门训练 “教别人” 的能力,尤其是随着AI越来越聪明,如何让人类跟上它的思路变得更重要。
参考资料:https://arxiv.org/abs/2506.05579
 豫公网安备41010702003375号
豫公网安备41010702003375号