
加速物理AI发展,Meta 发布全新“世界模型”V-JEPA 2
![]() 前沿资讯
1749726073更新
前沿资讯
1749726073更新
![]() 0
0
如何让人工智能像人一样,通过观察视频来理解世界、预测未来并实现机器人行为控制,而不依赖于大量人工标注或任务特定的训练?Meta研究人员指出,人类之所以能适应陌生环境、完成新任务,根本原因在于我们大脑中构建了一个“内隐模型”,该模型通过感官输入,学习出了一套预测与理解机制。为此,他们推出了最新、最强自监督视频模型:V-JEPA 2,该模型的目标就是想要构建一个类似的“世界模型”,让机器也能从大规模视频数据中学习这种能力。
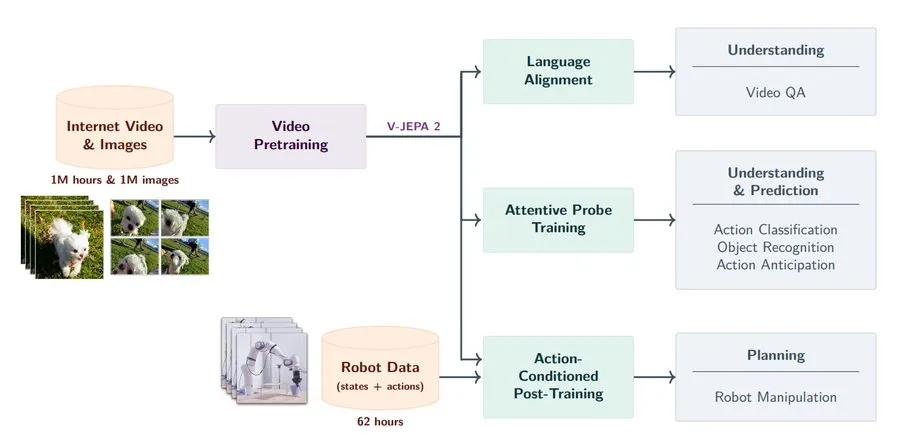
V-JEPA 2的训练采用两阶段策略。第一阶段是自监督预训练,它利用超过100万小时的互联网视频和大量图像数据,通过从缺失信息的片段中推测出完整画面的任务训练模型。这种方式不需要手工标注,仅靠视频自身的时间结构即可驱动模型学习。研究团队将模型规模扩展至10亿参数,并引入了高分辨率、长时序的视频预训练策略,使得模型能够更好地理解动态场景和物体变化。结果显示,V-JEPA 2在多个动作识别和视频理解任务中表现出色,尤其是在动态理解类任务上,如Something-Something v2上达到了77.3%的Top-1准确率,刷新了现有记录。
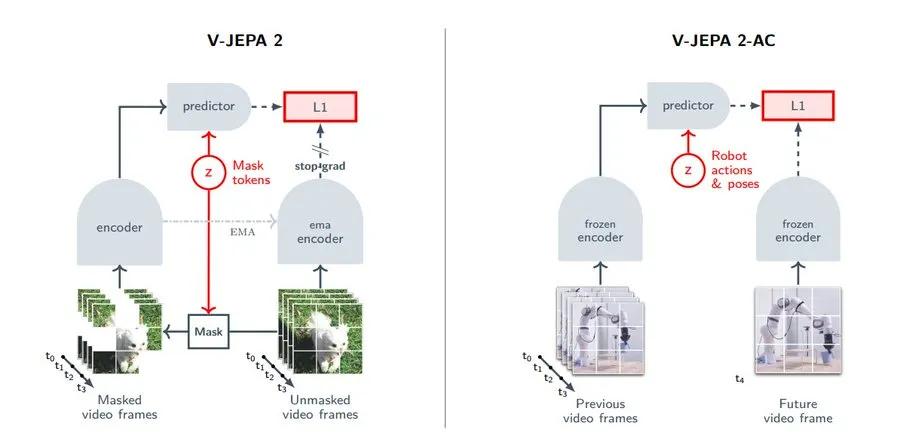
第二阶段则是在固定预训练模型的基础上,进行轻量的后训练,用于机器人控制。研究人员使用了仅62小时的未标注机器人操作视频,并构建了一个称为V-JEPA 2-AC的“动作条件预测器”,它可以根据当前状态和目标图像规划出一系列动作,实现如“抓取”、“移动”、“放置”等物理操作。这些操作在两个实验室的Franka机器人手臂上零样本部署,无需收集环境内的数据,也不依赖任何任务特定的训练或奖励信号。模型能够“看图行动”,在未见过的场景中执行复杂操作,这标志着通用视觉-动作系统迈出重要一步。
一个亮点是,V-JEPA 2的表现不仅限于视频理解,还能通过与大语言模型的对齐,扩展到多模态任务。在视频问答任务中,V-JEPA 2+LLM的组合在多个基准测试中达到SOTA成绩,如PerceptionTest(84.0)和TempCompass(76.9),表明它能处理包含物理、因果与时间推理的复杂问题。更关键的是,这种对齐并不依赖语言标签训练,这颠覆了以往“视觉语言必须联合训练”的传统看法。
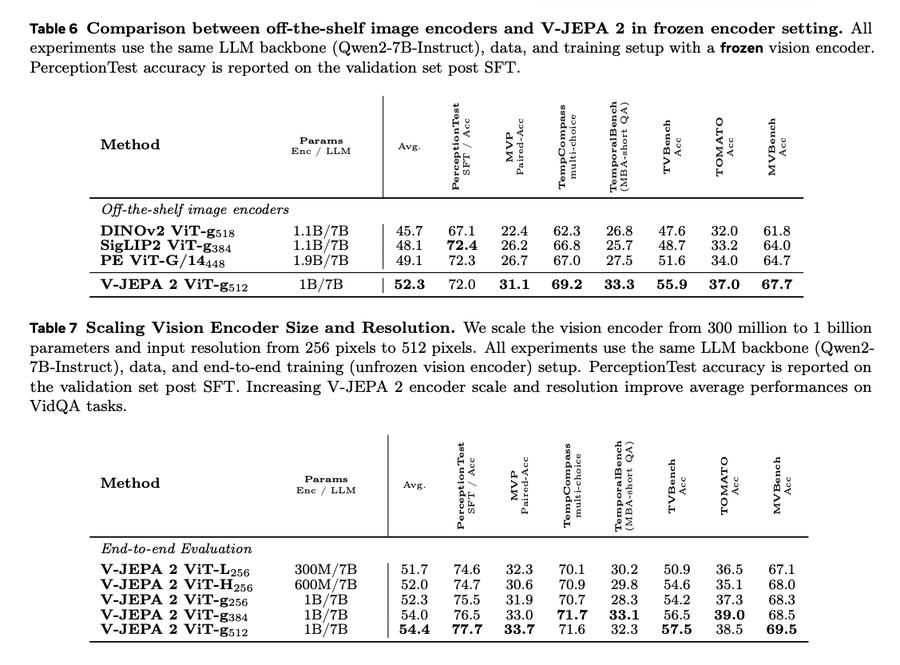
在评估中,V-JEPA 2不仅在动作分类,如Diving-48、Jester等中大幅领先,还在ImageNet、Kinetics400等外观识别任务中保持竞争力。尤其是在人类动作预测,如Epic-Kitchens-100中,其Recall@5达到39.7,比以往最优提升了44%,展现了其对时间和动因的敏感捕捉能力。
最后,在机器人实验中,V-JEPA 2-AC与当前主流的视觉语言行为克隆模型Octo和视频生成控制模型Cosmos进行了对比。实验表明,虽然V-JEPA 2-AC使用的训练数据更少、训练方式更轻量,但其在“抓取”、“搬运”、“精准放置”等任务上成功率更高,而且计算效率显著提升:每步动作规划时间仅需16秒,而Cosmos需4分钟。
整体来看,V-JEPA 2展示了自监督学习在视频理解、因果预测与物理操作三者之间的深度耦合潜力,打破了“要么理解、要么控制”的二元对立,将视觉感知与机器人行为有效联结,为打造更通用、低成本、可泛化的人工智能系统提供了新范式。这不仅是视觉模型的升级,更是世界模型在人工智能领域的实质性进展。
参考资料:https://arxiv.org/abs/2506.09985
 豫公网安备41010702003375号
豫公网安备41010702003375号