
三星电子等联合提出“文本感知图像修复”技术TAIR,显著提升了文字区域的还原效果
![]() 前沿资讯
1749899098更新
前沿资讯
1749899098更新
![]() 0
0
现有的扩散模型(Diffusion Models)在图像修复领域表现出色,能够有效修复模糊、压缩失真、噪声干扰等问题。然而,当图像中包含文字时,这些模型常常会生成“看起来像字”的图案,却与原文字内容无关,这种现象被称为“文本图像幻觉”。但即便只是一两个字的误判,也可能导致严重的信息偏差。因此,提升图文识别的修复质量,成为图像修复向更高层次发展的关键突破口。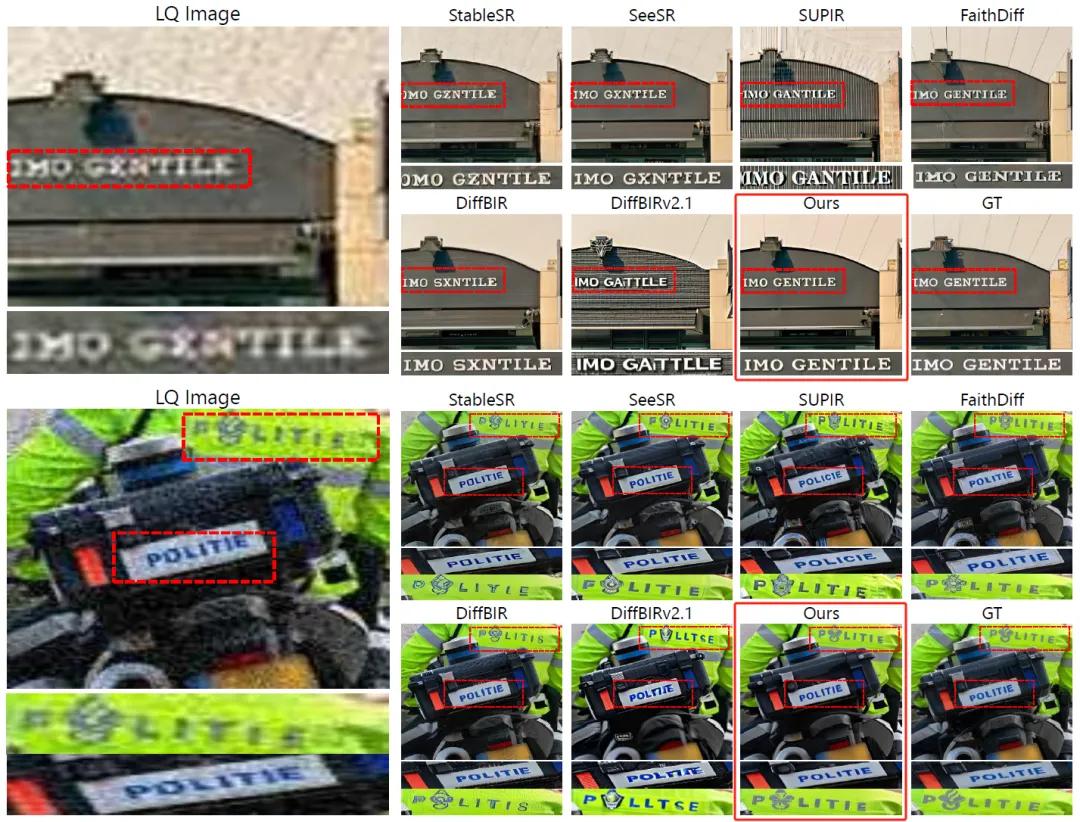
来自韩科院、韩国高丽大学、延世大学以及三星电子的联合研究团队提出了“文本感知图像修复”(Text-Aware Image Restoration,简称TAIR)技术,并构建了一整套创新方案,显著提升了图像文字区域的还原效果,尤其适用于街景、广告牌、文件扫描等文字密集场景。
TAIR明确要求,模型必须同时提升图像的整体质量与文字的可读性。也就是说,只把图修得“漂亮”还不够,还要“读得准”。为了支撑这一任务,研究团队推出了SA-Text数据集以及TeReDiff模型。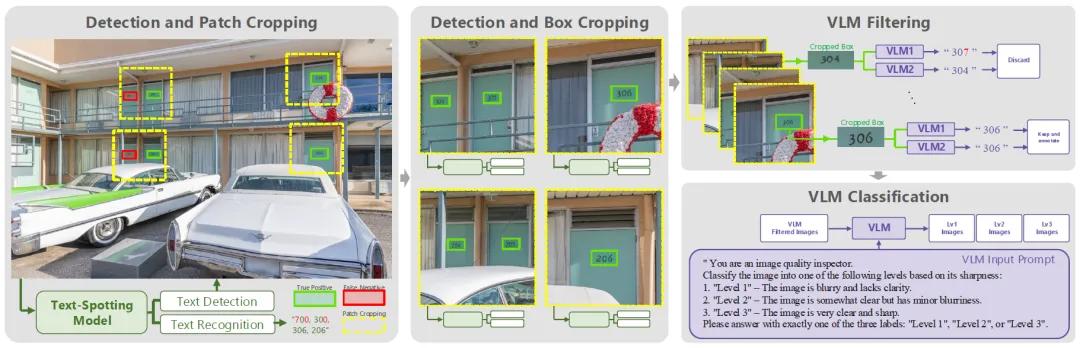
SA-Text数据集是一个专为TAIR设计的大规模高质量图文数据集,涵盖10万张图片,包含各种字体、排版、角度与背景的复杂场景。
传统图像数据集往往在文字区域处理上存在两大短板:分辨率低、注释不完整。为了解决这一问题,研究团队创新性地设计了一整套数据筛选与验证流程。首先,团队从大规模公开图像库SA-1B中筛选含有文本的图片,并通过文本检测模型进行区域划分。随后使用两套强大的“视觉语言模型”对检测出的文本进行交叉验证,确保识别内容一致后才会保留这部分数据。最后,对图像清晰度进行多级分类,去除模糊区域,保证数据质量。整个流程高度自动化、可扩展。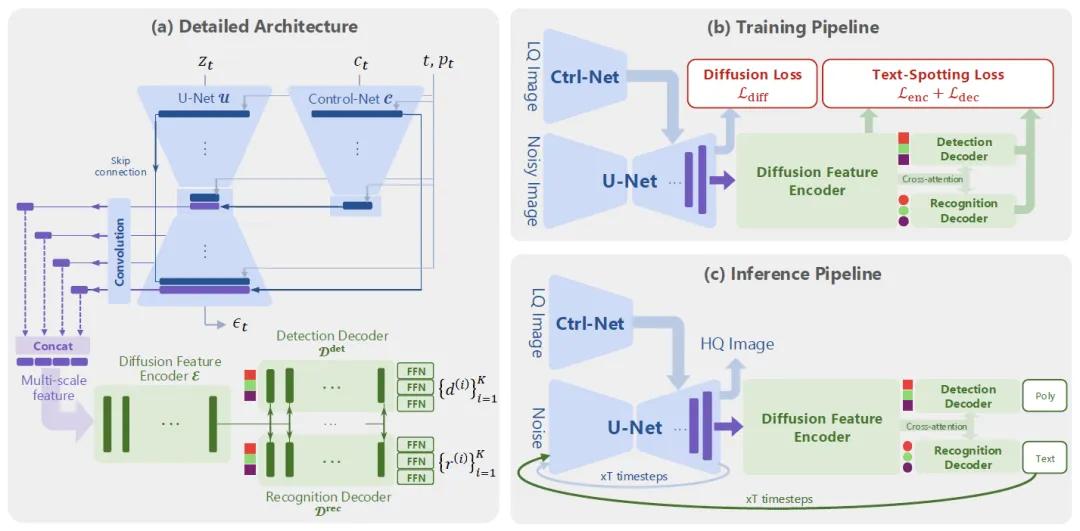
TeReDiff模型是一种基于多任务扩散框架的创新架构,将图像修复与文字识别两个子任务紧密耦合,在训练阶段实现信息共享,在推理阶段实现提示驱动(prompt-guided)修复。
传统方法中,这两个步骤通常是分开执行,无法形成闭环优化。而TeReDiff中,文字识别模块能够利用扩散模型中提取到的特征参与训练,并在推理阶段提供“文字提示”,帮助扩散模型更准确地还原图中文字。具体流程如下:
1、首先对低质量图像进行轻度预处理,降低噪声;
2、然后送入扩散模型进行逐步去噪修复;
3、在每一步去噪中,文字识别模块实时识别图中文字;
4、识别出的内容会作为下一步修复的“提示”,引导模型聚焦在重要文字区域。
实验结果显示,无论是在合成退化图像还是真实场景图片中,TeReDiff都在文字识别准确率、图像清晰度等多个指标上全面领先现有主流方法。尤其在图像退化严重的场景下,该模型仍能保持较高的文字还原能力。
研究团队还进行了一项用户调查实验,让人类参与者在多个图像样本中,分别对比TeReDiff与现有方法的修复效果。结果显示,高达98.5%的用户认为TeReDiff恢复的文字更清晰,89%认为整体画面质量更高。这也从人类视觉角度进一步验证了模型的实际效果。
参考资料:https://arxiv.org/abs/2506.09993
 豫公网安备41010702003375号
豫公网安备41010702003375号