
看齐DeepSeek,国内MiniMax开源发布旗舰推理模型MiniMax-M1,原生支持1M上下文长度
![]() 前沿资讯
1750155884更新
前沿资讯
1750155884更新
![]() 0
0
国内AI公司MiniMax(上海稀宇科技)开源发布最新旗舰模型:MiniMax-M1。该模型是目前全球首个开源的、采用混合专家架构与闪电注意力的大规模推理模型,具备极高的效率与推理能力。相比主流开源模型,MiniMax-M1在多个关键指标上实现突破,尤其在处理长文本、软件工程任务及工具使用方面展现出强劲实力。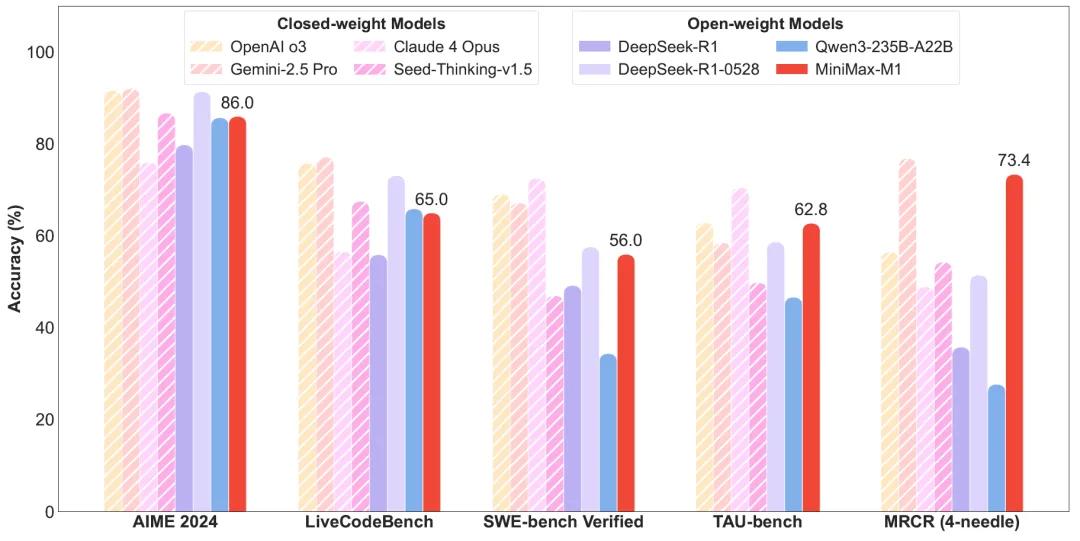
MiniMax-M1基于前代模型MiniMax-Text-01构建,总参数规模达4560亿,其中每个token激活的参数为45.9亿。模型采用了混合专家架构(Mixture-of-Experts,MoE)与闪电注意力的混合注意力设计,在架构上,每7层闪电注意力模块后接一层传统Softmax注意力块,兼顾效率与表达能力。该设计使模型能够高效处理超长输入,原生支持高达100万tokens的上下文长度,是当前DeepSeek-R1模型的8倍。
在推理效率方面,MiniMax-M1在生成长度为10万tokens时,其计算消耗仅为DeepSeek-R1的25%。这使得MiniMax-M1特别适用于复杂任务,如编程、逻辑推理和需要跨大量上下文信息的实际应用场景。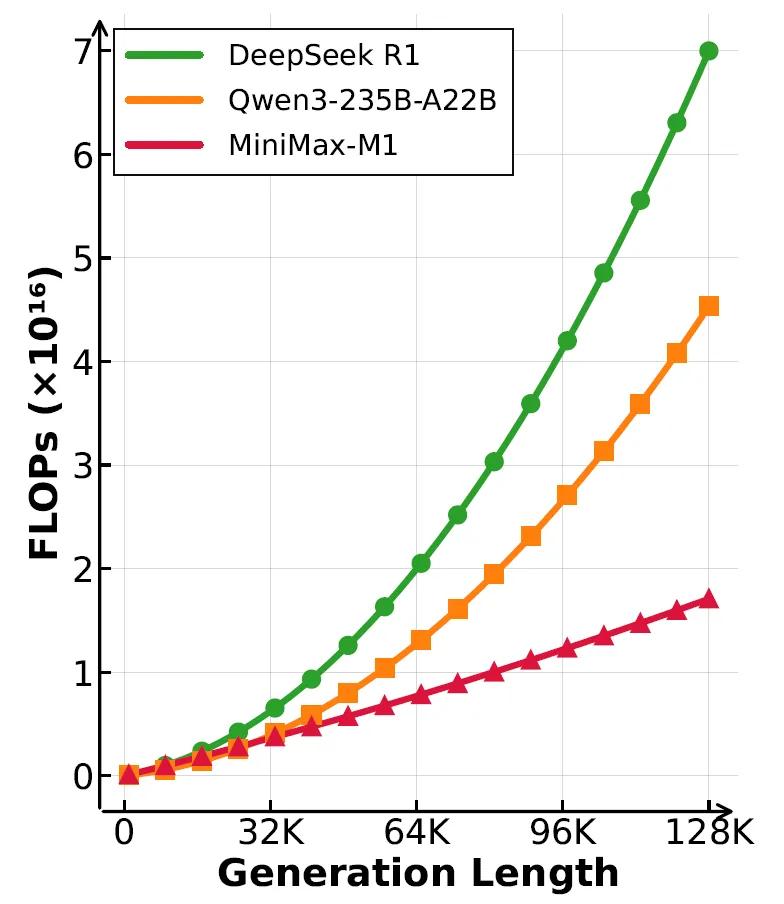
训练过程中,为实现上述能力,MiniMax-M1采用了分阶段策略。第一阶段是在MiniMax-Text-01基础上,使用7.5万亿token的高质量语料进行持续预训练,重点包含数学、编程、STEM、逻辑推理等内容,占比达70%。
随后模型进入监督微调阶段,引入高质量的反思式思维链Chain-of-Thought示例,强化模型的多步推理能力,为后续强化学习(RL)奠定基础。在核心的RL阶段,MiniMax-M1采用了新提出的CISPO算法(Clipped IS-weight Policy Optimization),相比现有的DAPO和GRPO等方法,CISPO保留了所有token的梯度贡献,并通过剪裁重要性采样权重来稳定训练。实验证明,CISPO在训练速度上实现了对DAPO的2倍加速,并在RL任务中取得了更优性能。
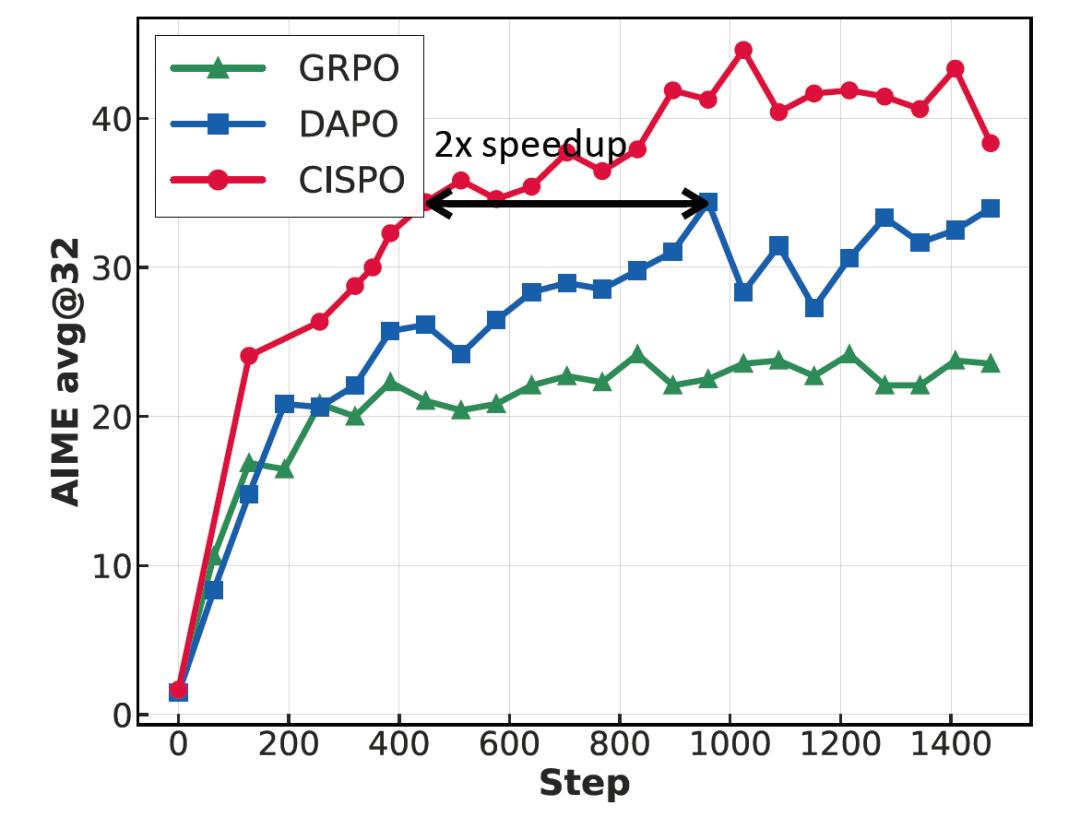
整个RL训练在512张H800 GPU上完成,总时长仅为三周,GPU租用成本约为53.47万美元。在工程优化方面,MiniMax团队解决了混合架构下训练与推理精度不一致的问题,通过将输出头精度提升至FP32,成功稳定训练过程。此外,模型还对早期生成中出现的高概率重复token设置了提前终止机制,以避免训练异常。
在RL训练输出长度方面,MiniMax-M1先以40K tokens为限,训练出MiniMax-M1-40k。随后逐步扩展生成长度至80K,训练出增强版MiniMax-M1-80k。在扩展过程中,团队采用分阶段窗口扩展方法,通过观察输出长度分布和困惑度收敛情况,确保训练稳定性。针对长输出序列可能出现的模式坍缩问题,团队引入了重复检测提前截断、样本级损失与token级归一化联合优化、以及梯度裁剪等策略进行稳定控制。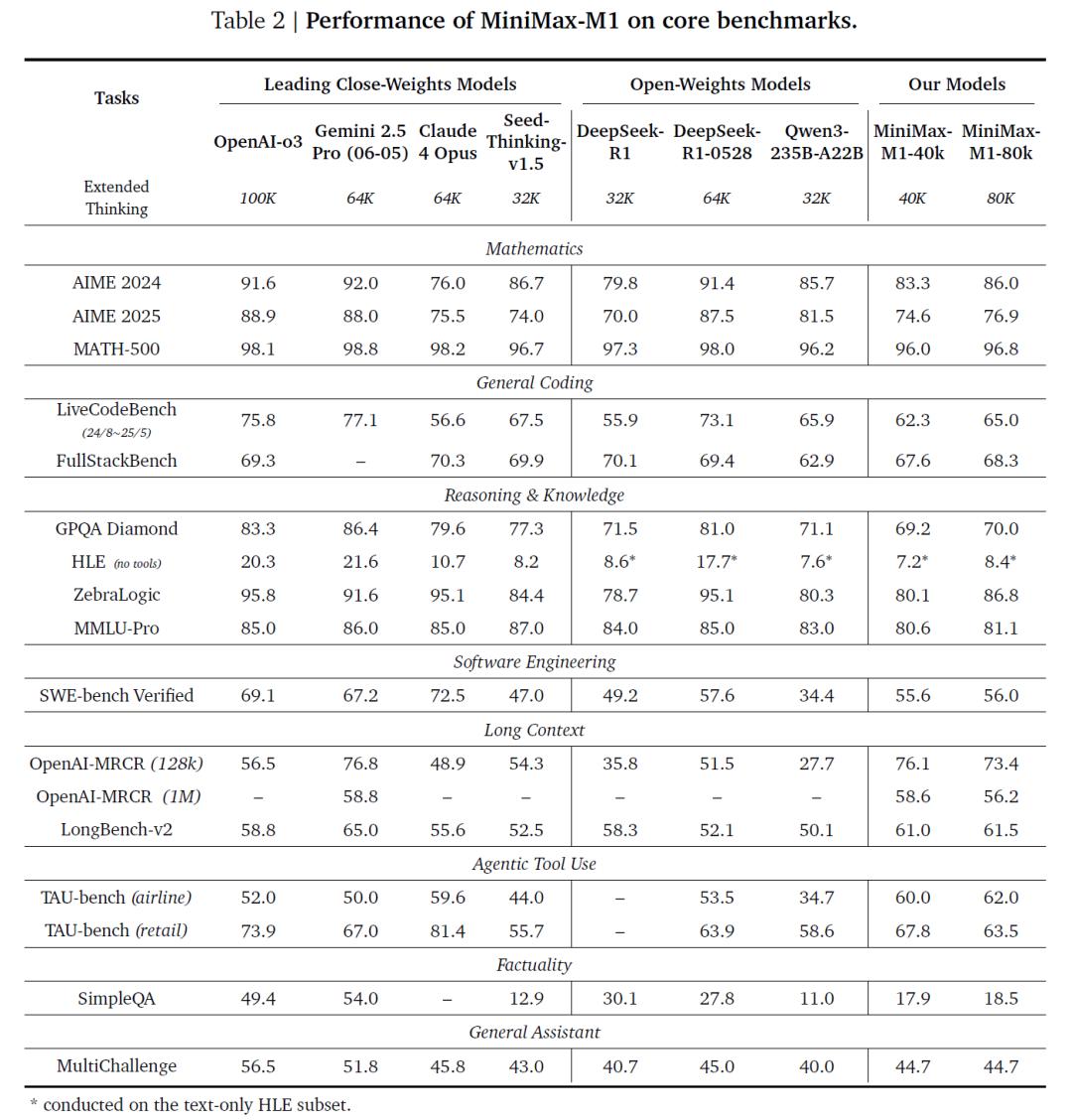
在权威评测中,MiniMax-M1-80k展现出卓越性能。它在AIME 2024的数学推理测试中达到86.0%的准确率,优于大部分开源模型;在LiveCodeBench和FullStackBench编程评测中,也接近甚至超过Qwen3-235B。在SWE-bench Verified软件工程任务上,MiniMax-M1取得56.0%的正确率,显著优于多数开源模型,仅次于DeepSeek-R1-0528。
在处理长上下文任务方面,MiniMax-M1得益于1M的原生上下文窗口,显著超过OpenAI o3、Claude 4 Opus等闭源模型,表现出强劲的语义保持与推理整合能力。此外,在工具使用场景(如TAU-bench)中,MiniMax-M1也优于Gemini-2.5 Pro,展示出优秀的智能体交互潜力。
目前,MiniMax-M1的两种版本(40k与80k)均已在GitHub公开发布,并支持vLLM与Transformers框架部署。用户可以通过文档快速集成模型,同时还可访问MiniMax提供的商业API服务。该团队表示,MiniMax-M1未来将在自动化工作流、科研助理、智能体交互等领域中发挥重要作用。
参考资料:https://huggingface.co/collections/MiniMaxAI/minimax-m1-68502ad9634ec0eeac8cf094
 豫公网安备41010702003375号
豫公网安备41010702003375号