
微软发布新一代微型语言模型Mu,端侧运行,赋能Windows AI助手
![]() 前沿资讯
1750752413更新
前沿资讯
1750752413更新
![]() 0
0
微软正式发布其最新本地微型语言模型Mu,该模型已部署于Copilot+设备的Windows设置应用中,助力实现自然语言与系统功能之间的高效映射。据微软Windows应用科学副总裁Vivek Pradeep(维韦克·普拉迪普)介绍,Mu是一款专为边缘设备与神经处理单元(NPU)设计的微型语言模型,具备高效性能和低延迟响应能力。
Mu模型完全在设备端运行,依托NPU实现超过每秒100个token的推理速度,满足系统设置场景对响应速度的严苛要求。在结构上,Mu采用330M参数规模的Transformer编码器-解码器架构,该架构优于传统的仅使用解码器的模型设计,极大减少了计算与内存开销,尤其在Qualcomm Hexagon NPU等移动AI加速器上的表现尤为突出,首token延迟降低47%,整体解码速度提升近5倍。
Mu初期借鉴了微软Phi模型的训练技术路线,以数千亿高质量教育语料进行预训练,学习语言结构与语义知识。随后通过模型蒸馏技术继承Phi模型的知识,再结合任务特定的数据,通过LoRA(低秩适配)方式进行精调。
为充分发挥NPU的并行处理与向量化能力,Mu的模型结构在多个方面进行了硬件感知优化。模型采用了双层归一化(Dual LayerNorm)、旋转位置编码(RoPE)与分组查询注意力机制(GQA),进一步压缩模型体积同时保持准确性。此外,Mu还共享输入与输出词嵌入权重,有效降低参数数量并提高一致性。在SQUAD、CodeXGlue及Windows设置助手等任务中,Mu虽然小巧,但表现接近甚至优于更大模型。在CodeXGlue编程任务上,Mu微调后的得分达到0.934,略高于同类Phi模型。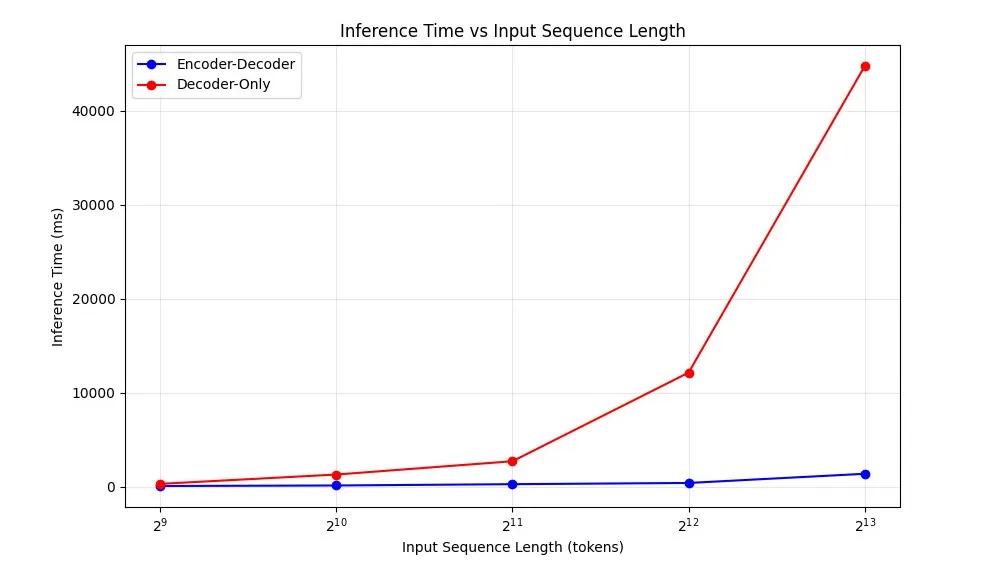
为了让Mu高效运行于Copilot+ PC上,微软对模型进行了量化优化,采用后训练量化(PTQ)将浮点权重转换为整数格式(以int8和int16为主),既提升推理速度又大幅降低内存使用。此外,微软还与AMD、Intel与Qualcomm紧密合作,对量化算子进行平台定制,确保各类芯片上Mu都能发挥最佳性能。在Surface Laptop 7上,Mu可实现超过200 tokens/s的输出速度。
Mu模型目前已应用于Windows设置中的AI助手,以简化系统功能的查找与修改流程。用户可通过自然语言输入如“开启夜间模式”或“调整屏幕亮度”,AI助手即能精准匹配至对应设置项。为了提升对简短模糊输入的理解能力,微软还设计了复合式查询处理机制。对于简单词组,仍保留传统关键词匹配方式。而完整语义表达的多词查询,则通过Mu助手返回高精度可操作建议。
在开发过程中,微软团队对Mu进行了任务定向的深度调优。通过扩展至360万条训练样本、覆盖上百种系统设置,并引入多样化语言表达、自动标注、提示词优化等方法,显著提升了模型精度与鲁棒性。最终,优化后的Mu模型将响应时间控制在500毫秒以内,满足了设置助手对流畅性与准确率的双重需求。
目前,Mu模型驱动的设置助手已在Windows Insider Dev渠道上线,微软鼓励用户积极试用并提供反馈,以助其持续优化模型表现与用户体验。
参考资料:https://blogs.windows.com/windowsexperience/2025/06/23/introducing-mu-language-model-and-how-it-enabled-the-agent-in-windows-settings/
 豫公网安备41010702003375号
豫公网安备41010702003375号