
Google DeepMind推出Crome框架,提升奖励系统鲁棒性
![]() 前沿资讯
1750927930更新
前沿资讯
1750927930更新
![]() 0
0
Google DeepMind正式发布全新Crome框架(Causal Robust Reward Modeling),该框架开创性地引入因果建模视角,并通过自动化的数据增强方法,强化模型对因果性质量因素的识别与响应,为提升大语言模型训练过程中的安全性和鲁棒性迈出关键一步。
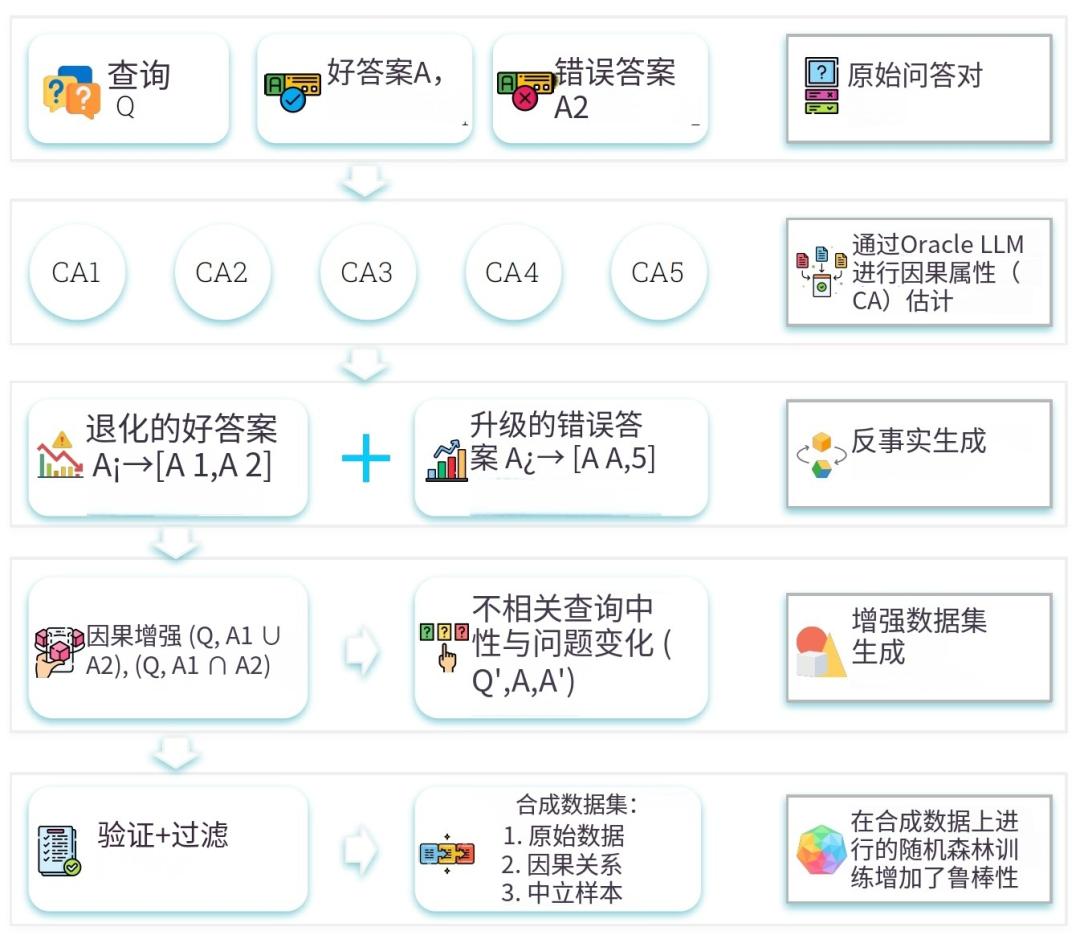
现有模型普遍存在着鲁棒性不足的隐患,容易被训练数据中的表面特征误导。比如,一些模型错误地将回答长度、格式规范等视为高质量答案,而忽略事实性、逻辑性等真实反映用户偏好的因果属性。这种现象不仅削弱了模型对真实偏好的辨识能力,还可能导致最终输出出现策略偏移甚至安全风险。为应对上述挑战,Crome框架应运而生。
Crome框架构建了明确的因果模型,并据此设计了两类针对性的数据增强策略:
因果增强:通过生成在特定因果属性上存在差异的回答对,引导奖励模型聚焦这些因果性维度。研究人员在事实性这一维度上制造回答质量的“升级”与“降级”,让模型学会准确感知事实性对整体质量的影响。
中性增强:通过无关任务生成标签为“平局”的回答对,确保模型在因果属性保持不变时,对格式、语气等虚假表征的变化保持不敏感。该策略不依赖人工标注虚假特征,而是通过“因果干预”实现自动控制。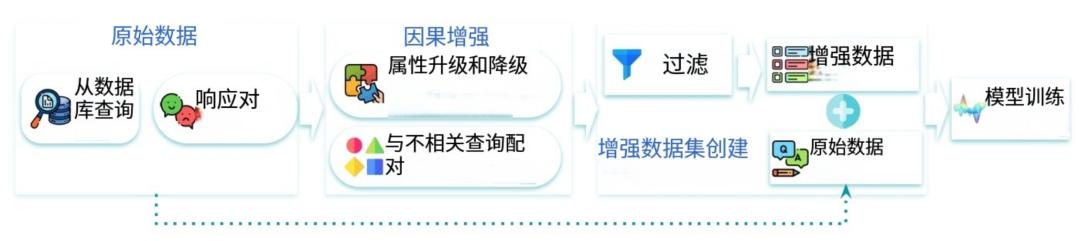
Crome的增强数据由模型自动生成,研究团队先通过“oracle LLM”识别出因果规则,再进行有针对性的问答干预,从而构建出无需人工参与的增强样本生产流程,极大提升了系统的可扩展性与适应性。
Crome框架在多个基准测试中展现出超越现有方法的性能。在RewardBench基准上,相比当前最强对比模型,Crome平均准确率提升5.4%,其中安全相关任务提升13.18%,推理类任务提升7.19%。在reWordBench鲁棒性测试中,Crome在23种输入扰动中有21项取得更优表现,对格式篡改、冗余插入等攻击具备更强抵抗力。在Best-of-N推理场景下,随着候选答案数量增加,Crome在多个任务中均保持排名稳定提升,表明其对“长尾型虚假特征”具有天然鲁棒性。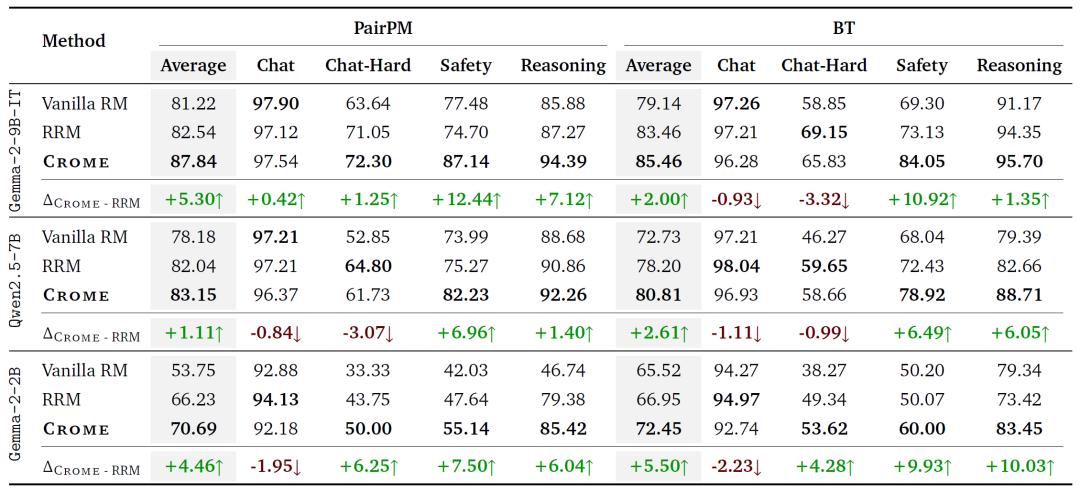
此外,研究团队还从理论层面分析了Crome的机制,指出该方法可引导模型学习“稀疏因果奖励系数”,其误差规模仅受因果维度数量影响,而对高维虚假特征表现出高度不敏感性。
Google DeepMind 表示,Crome框架突破了基于统计相关的传统建模思路,开启了因果驱动的奖励模型设计新路径。该成果可广泛应用于安全对话系统、智能助手、自动推理等LLM落地场景,有效缓解模型被诱导输出有害信息的风险。下一步,研究团队计划将Crome的因果数据增强理念延伸至基础模型的训练阶段,从源头提升模型对“什么是真正重要的回答特征”的理解能力。
参考资料:https://arxiv.org/abs/2506.16507
 豫公网安备41010702003375号
豫公网安备41010702003375号