
谷歌发布全新一代轻量AI模型Gemma 3n
![]() 前沿资讯
1751016847更新
前沿资讯
1751016847更新
![]() 0
0
今天,谷歌正式发布全新一代轻量级AI模型:Gemma 3n,该模型延续了“移动优先”架构理念,在性能、效率和适配性上实现全面跃升,为开发者带来最领先的边缘AI应用能力。
谷歌表示,自首个Gemma模型发布以来,整个生态系统已累计下载量超过1.6亿次,并孕育出众多细分模型及开发创新。从企业级计算机视觉,到多语种模型研发,Gemma逐步构建出一个庞大而充满活力的“Gemma社区”。
本次发布的Gemma 3n,基于此前预览版的反馈与改进,完整释放了其面向开发者设计的能力,并全面兼容Hugging Face Transformers、llama.cpp、Google AI Edge、MLX、Ollama等主流平台工具,支持高效微调与部署,助力打造各类端侧应用。
Gemma 3n 的核心优势包括:
● 原生多模态支持:集成图像、音频、视频与文本处理能力;
● 设备端优化:提供 E2B(等效参数2B)与 E4B(等效参数4B)两个版本,最低仅需2GB内存即可运行;
● 创新架构 MatFormer:采用“套娃式”Transformer结构,支持模型动态缩放与自定义混合;
● Per-Layer Embeddings(PLE)技术:显著减小显存占用,在不影响质量的前提下提升部署效率;
● KV Cache 共享机制:实现长输入场景下的推理加速,响应速度提升达2倍;
● 多语种与数学编程能力增强:支持140种语言,E4B版本LMArena得分突破1300,成为首个突破此分数的10B参数以下模型。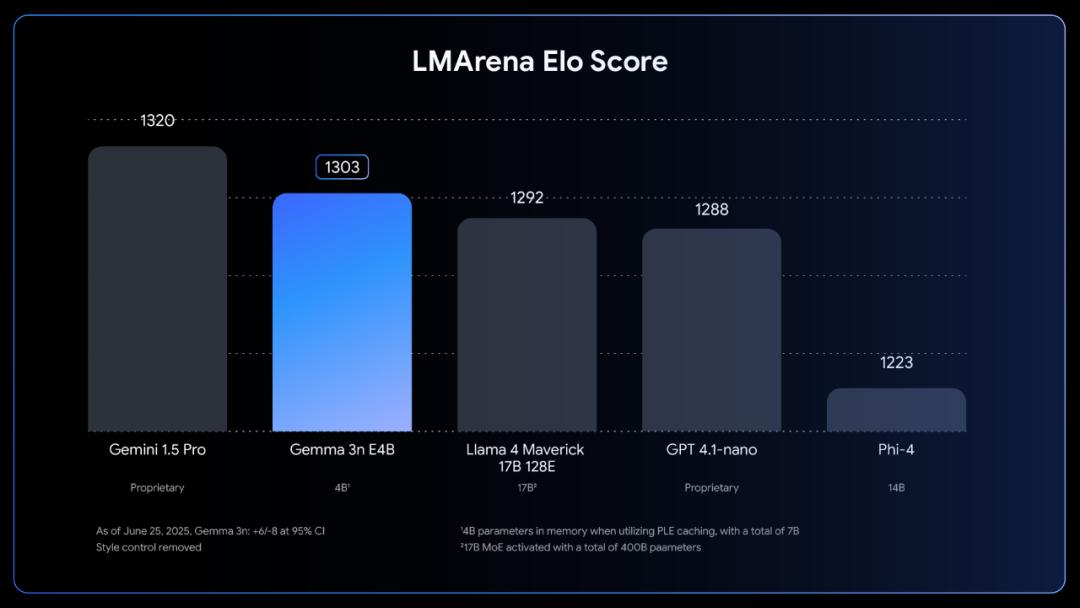
Gemma 3n搭载先进的音频编码器,支持离线语音识别与跨语种翻译。在英西、英法、英意等方向表现尤为突出,为本地语音应用开发打开了新天地。
同时,其全新视觉模块MobileNet-V5-300M也同步亮相,具备:多分辨率支持(256x256至768x768);每秒高达60帧的处理能力;基于深度金字塔结构与多尺度融合的新型VLM适配器;与前代相比,在推理速度、参数规模和内存占用方面均大幅优化。
相较于此前Gemma 3中的视觉基线SoViT,MobileNet-V5在Edge TPU量化场景下实现13倍加速,同时减少46%参数量,整体精度表现显著提升。
此外,谷歌还同步启动Gemma 3n Impact Challenge挑战赛,号召全球开发者基于Gemma 3n的离线、多模态、设备端能力,构建真正改变世界的产品与解决方案。大赛欢迎提交具备“真实场景影响力”的视频故事与演示作品,总奖金高达15万美元。
随着社区力量不断壮大,谷歌表示将继续推动AI能力走向普惠与可部署,助力每一位开发者将想法变为现实。
参考资料:https://developers.googleblog.com/en/introducing-gemma-3n-developer-guide/
 豫公网安备41010702003375号
豫公网安备41010702003375号