
SuperCLUE发布首期深度研究测评:OpenAI、Google领跑,Kimi、豆包表现亮眼
![]() 前沿资讯
1751280703更新
前沿资讯
1751280703更新
![]() 0
0
今日,SuperCLUE团队正式发布了首期“DeepResearch(深度研究)”测评结果。该测评面向全球范围内的九款大语言模型深度研究产品进行能力评估,旨在全面衡量当前AI在自动化研究方面的真实水平。结果显示,OpenAI和Google的产品稳居榜单前列,国内厂商中,月之暗面的“Kimi Researcher”和字节跳动的“豆包”表现出色,在研究分析等任务中展现出强劲实力。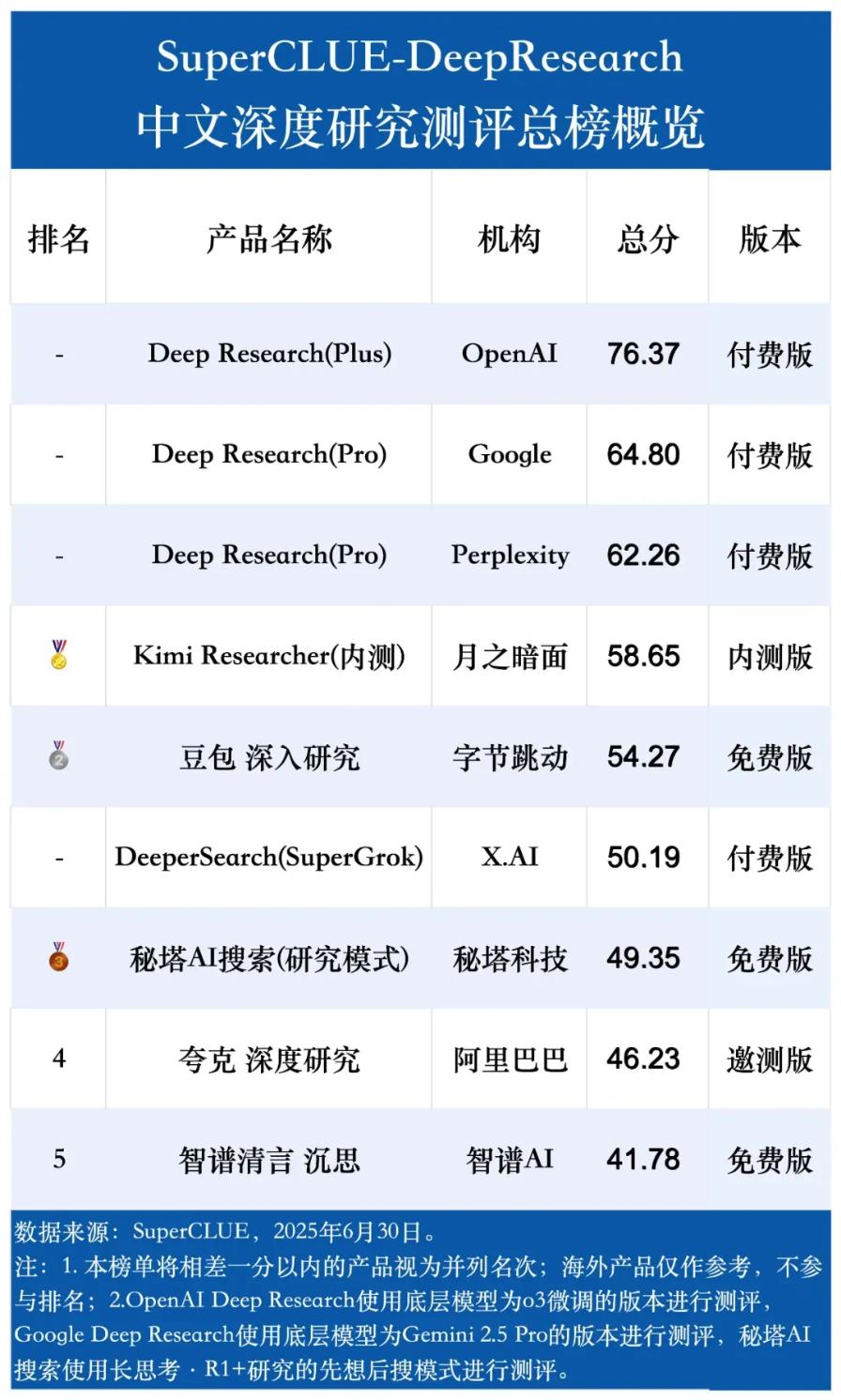
“DeepResearch”指的是由大语言模型驱动的一类自动化研究能力,它超越了传统的搜索问答,能够独立分析并生成基于复杂主题的报告,具备引用支持、信息整合与逻辑推理能力,标志着AI从“信息获取”向“知识生产”迈出的关键一步。
在SuperCLUE-DeepResearch测评体系中,OpenAI以76.37分摘得总榜冠军,Google紧随其后。Kimi Researcher以58.65分位列国内第一,在研究分析类任务中表现尤为突出。总体而言,国外产品平均得分为63.41分,明显高于国内产品的平均得分50.06分,显示出在算法精度、信息检索能力等方面的差距仍较明显。
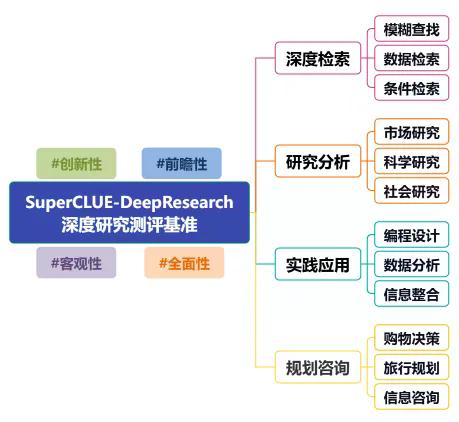
SuperCLUE-DeepResearch测评共涵盖四大核心任务:
深度检索能力:考察AI从复杂信息中提取精准答案的能力;
研究分析能力:评估AI撰写市场、科学与社会研究报告的综合水平;
实践应用能力:涵盖编程、数据分析与多源信息整合能力;
规划咨询能力:包括旅行规划、购物推荐等日常应用场景下的智能决策支持。
在评估过程中,测评团队采用细粒度维度指标,并结合超级模型自动化评分技术,最大程度保障评分客观性和一致性。
测评显示,AI在研究分析任务中的平均得分高达84.54分,体现出其在内容撰写、逻辑组织方面的成熟能力。而在深度检索任务中,平均得分仅为26.26分,暴露出当前AI在知识密集型、强逻辑推理场景中的瓶颈。
本次参评的五款国产产品在深度检索与实践应用任务中普遍表现不佳。分析指出,信息源的数量与质量不足、逻辑推理能力欠缺、产品功能侧重不均等问题,成为制约国产深度研究产品综合能力的重要因素。比如,Kimi Researcher虽在研究分析任务中成绩亮眼,但不支持代码生成,导致其在综合能力评分中受到影响。豆包虽有AI编程板块,但在深度信息整合任务中仍存在遗漏与表达混乱等问题。
SuperCLUE团队表示,随着AI模型能力的不断演进,DeepResearch将成为未来知识工作的重要支撑工具。此次测评为行业提供了详实的基准数据,也为各厂商改进方向提供了清晰参考。
 豫公网安备41010702003375号
豫公网安备41010702003375号