
阶跃星辰正式开源3210亿参数多模态大模型Step3,解码成本直降,开发者即日起可调用
![]() 前沿资讯
1754045041更新
前沿资讯
1754045041更新
![]() 0
0
国内人工智能企业阶跃星辰(StepFun)宣布,面向全球开发者开放其最新一代多模态推理模型Step3。该模型基于3210亿总参数的稀疏MoE(Mixture-of-Experts)架构,每次推理仅激活380亿参数,通过算法-系统协同设计在视觉-语言任务上实现旗舰级性能,同时将解码成本压缩至行业领先水平。
一、核心亮点
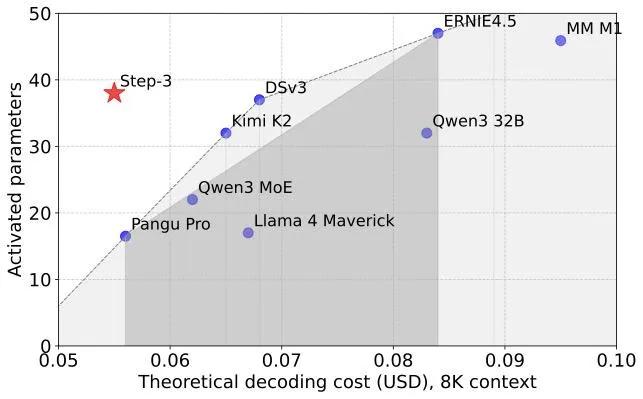
• 极致效率:在4096 token上下文、50 ms/tok的严苛延迟约束下,单卡吞吐达4039 tokens/s,较同规模DeepSeek-V3提升约70%,且仅使用1/3 GPU。
• 超长视野:单卡48GB显存即可支持800 K token长序列推理(int8量化)。
• 视觉-语言同训:4万亿图文混合token,OCR、表格、GUI、视频理解等多任务全覆盖,中英双语各半。
• 幻觉抑制:通过大规模偏好强化学习,显著降低视觉问答中的幻觉输出。
• 开源组件:通信库StepMesh(基于GPUDirect RDMA)已在GitHub开放,支持多对多异构芯片直连。
二、技术突破
Multi-Matrix Factorization Attention(MFA):将注意力计算分解为多矩阵低秩投影,KV-Cache占用仅为传统方案的22%,显著降低长上下文显存压力。
Attention-FFN Disaggregation(AFD):把Attention与FFN解耦到独立GPU实例,通过多级流水线并行与StepMesh零拷贝通信,实现高吞吐、低延迟的分布式推理。
数据炼金术:训练前清洗1000亿份原始文档,利用10余种专用NLP模型进行毒性、缺陷、领域细分等50+维度打分,配合MinHash去重与领域再平衡,最终沉淀20T高质量文本+4T图文对。
两阶段对齐:
• 监督微调:涵盖数学推理、竞赛编程、STEM问答及通用对话,单条样本需通过毒性、事实性、重复度等七道质量关卡。
• 强化学习:可验证任务采用自动评分奖励,开放任务引入人类偏好模型;价值网络稳定策略更新,显著增强智能体工具调用能力。
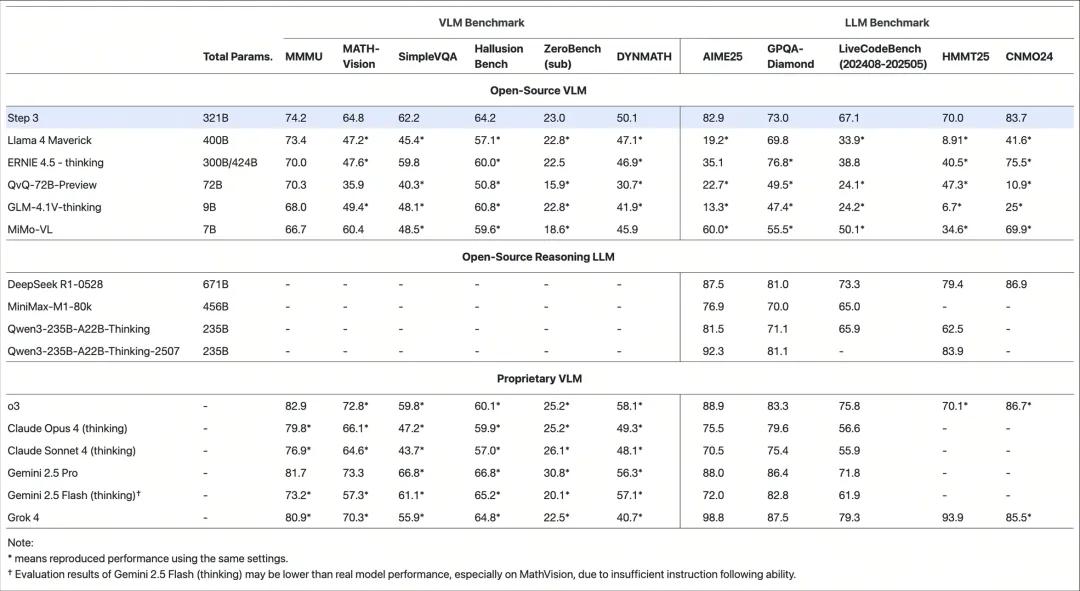
性能实测方面,在8×H100服务器、FP8精度、4K上下文条件下,Step3达到4000 Token/GPU/s,优于DeepSeek-V3官方公布的2324 Token/GPU/s。针对32K以上长文,Step3的延迟优势随长度递增而进一步扩大。
即日起,Step3 API与模型权重将在StepFun官网及主流云市场同步上线,提供免费试用额度。StepMesh通信库采用Apache-2.0协议开源,支持GPU、ASIC、FPGA等异构芯片。
参考资料:https://stepfun.ai/research/en/step3
 豫公网安备41010702003375号
豫公网安备41010702003375号