
阿里Qwen团队发布开源图像生成模型Qwen-Image:主打中英文文本渲染
![]() 工具推荐
1754389432更新
工具推荐
1754389432更新
![]() 2
2
8月5日消息,阿里旗下Qwen团队今日宣布,图像生成模型Qwen-Image正式上线,并面向全球开发者开放源代码与完整权重。该模型以“精准中英文文本渲染”为核心卖点,直接对标Midjourney、DALL·E 3等封闭源竞品,并在多项基准测试中实现超越。

长期以来,图像生成模型在“把字写对、排好”这件事上表现欠佳。Qwen-Image通过自研课程式训练策略,可一次性生成含多行段落、中英混排、字体风格统一的视觉内容。官方演示显示,该模型在以下场景已可直接落地:
品牌营销:双语海报、Logo与广告语同屏呈现;
办公设计:支持PPT素材生成;
教育出版:图解教材、考试插图,文字零错漏;
电商零售:产品标签、店铺招牌与场景文案同步渲染;
创意内容:诗画融合、动漫分镜,文本与画面风格联动。

与Midjourney等需付费订阅的封闭模型不同,Qwen-Image采用Apache 2.0协议,支持免费商用、修改及再发布。开发者可在Hugging Face、ModelScope、GitHub同步获取模型权重、推理脚本与微调示例。用户也可通过Qwen Chat官网直接体验“图像生成”模式。需要提醒的是,Qwen团队未披露训练数据来源,企业在商业化部署时需谨慎评估潜在的法律风险。
据技术白皮书,Qwen-Image训练集由55%自然图片、27%设计内容、13%人物活动及5%内部合成文字构成,总计数十亿图文对。模型采用“三模块”架构:负责理解上下文并引导生成的Qwen2.5-VL多模态语言模型;处理高分辨率细节的VAE编码解码器;以及引入MSRoPE空间位置编码,提升字符对齐精度的MMDiT扩散骨架。该架构支持256p–1328p多档分辨率输出,支持图像编辑(TI2I)、任务提示定制,并可无缝接入Megatron-LM分布式训练框架。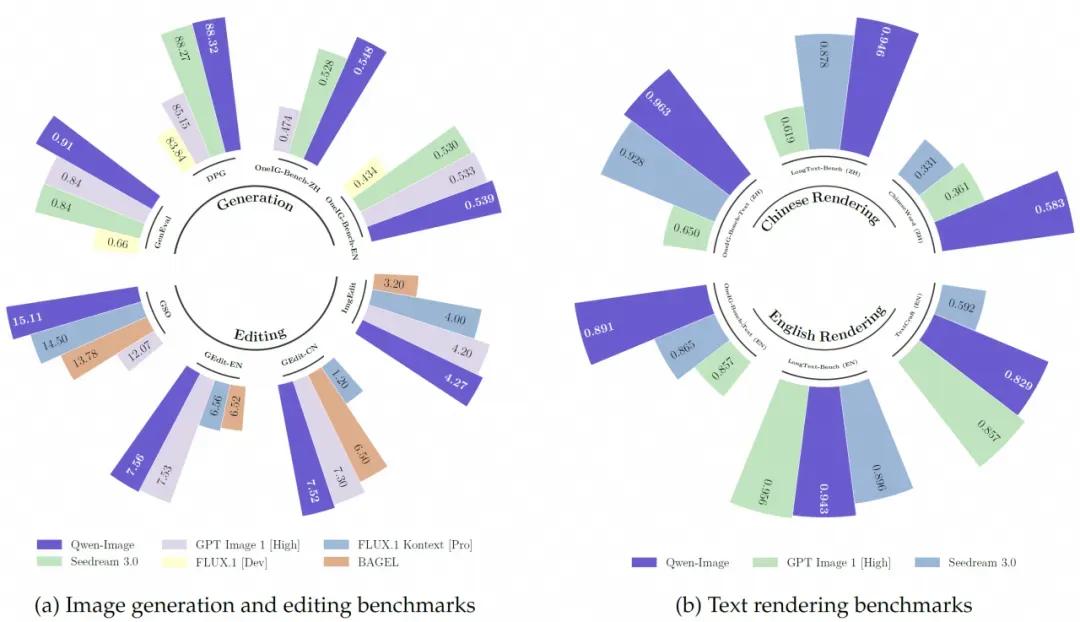
在GenEval、DPG、OneIG-Bench等五大国际基准测试中,Qwen-Image在指令一致性、布局精准度、长文本渲染等指标均位列前三。其中,中文文本清晰度与结构准确性显著优于GPT Image 1、Seedream 3.0、FLUX.1 Kontext等闭源模型。AI Arena平台最新数据显示,Qwen-Image在1万余次人工盲评中综合排名第三,开源阵营第一。
Qwen团队表示,模型已针对营销、教育、电商、数据合成四大场景预置提示词模板,企业用户最快可在数小时内完成业务集成。下一步,团队将联合社区持续优化多语言支持与图像编辑能力,并计划推出LoRA微调工具包。
“我们希望Qwen-Image成为降低视觉内容创作门槛、推动AI与设计融合创新的起点。”Qwen团队负责人称。
即日起,开发者可访问以下链接获取资源:
模型权重与代码:https://github.com/QwenLM/Qwen-Image
在线体验:https://chat.qwenlm.ai
 豫公网安备41010702003375号
豫公网安备41010702003375号