
Google Ads提出迭代式高保真数据精选方案,训练数据骤减万倍,模型对齐精度反升65%
![]() 前沿资讯
1754892793更新
前沿资讯
1754892793更新
![]() 1
1
Google Ads宣布,其研究团队开发出一种全新的主动学习数据筛选流程,可将训练数据量压缩至原来的万分之一,同时,语言模型与人类专家的对齐度提升最高达65%。
广告内容安全审核历来依赖海量人工标注。以识别“诱导点击”广告为例,传统做法需要约10万条标注样本,成本高昂且难以应对政策快速迭代。Google Ads工程经理Markus Krause(马库斯·克劳斯)与研究科学家Nancy Chang(南希·张)领衔的团队提出“迭代式高保真数据精选”方案。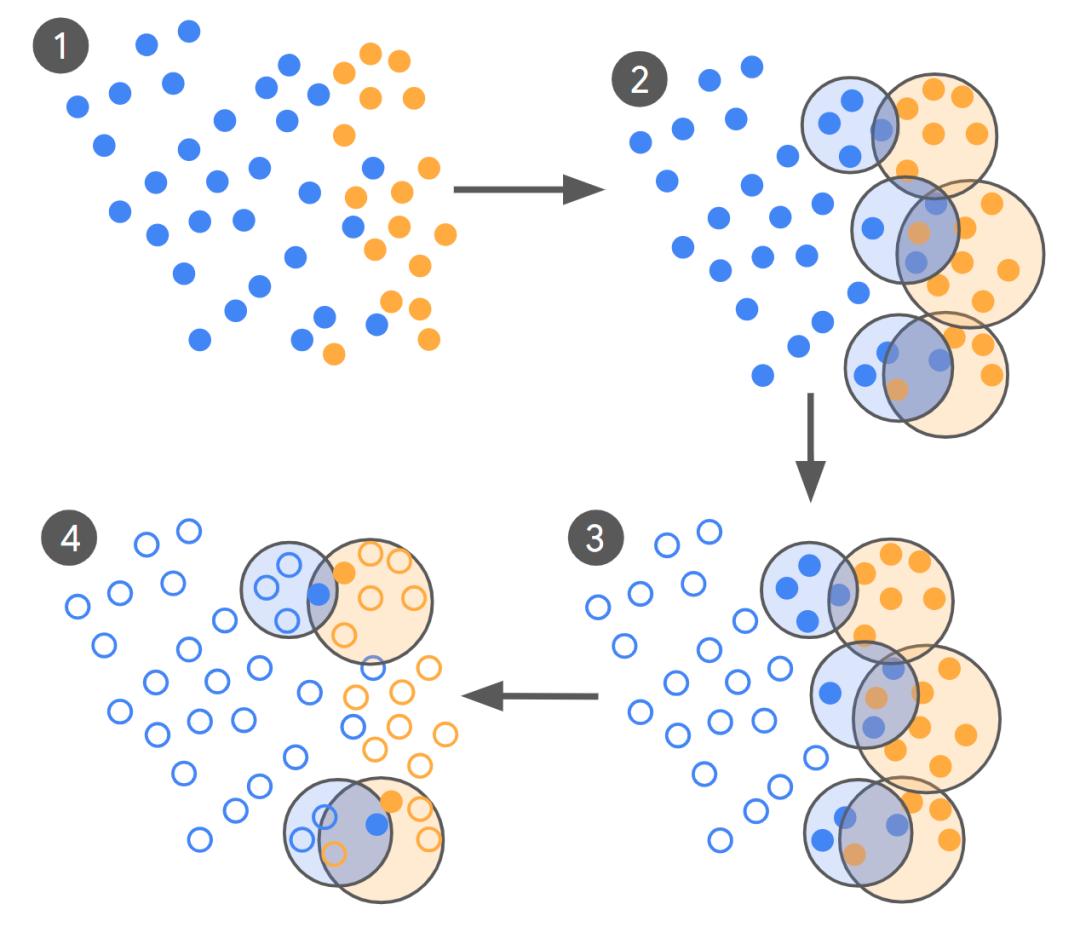
该方案的核心思路是:
1. 零样本启动:先用未精调的LLM(LLM-0)对数百亿条广告进行初步分类,生成首批标签。
2. 重叠聚类:对“可疑”与“正常”两类分别聚类,找出模型最“犹豫”的边界区域。
3. 专家重标:让资深审核员仅对这些“最混淆”的成对样本做二次判定。
4. 循环精调:用专家标签微调模型,再返回步骤1,直至模型与人类内部一致性(Cohen’s Kappa)持平或提升停滞。
实验表明,只需250–450条由双人专家交叉验证的高质量样本,即可让32.5亿参数的Gemini Nano-2模型在两项复杂度不同的任务上,对齐度从0.36提升至0.56(低复杂度)和0.23提升至0.38(高复杂度),分别提升55%与65%。
由于广告安全领域存在大量灰色地带,传统精确率/召回率指标难以适用。团队改用Cohen’s Kappa衡量模型输出与人类专家的一致性:值越接近1,代表对齐越佳。实验显示,人类专家内部Kappa可达0.81(低复杂度任务)与0.78(高复杂度任务),成为模型性能“天花板”。当专家标注质量(Kappa≥0.8)得到保证时,精调模型即可在数据量锐减的前提下,显著优于10万条众包标注训练出的基线模型。
目前,该方法已在Google Ads大规模模型上验证,数据规模缩减最高达四个数量级,且未出现质量下滑。研究团队指出,这一流程特别适合应对政策频繁更新、新型违规内容突发的场景,可极大降低模型重训成本。
参考资料:https://research.google/blog/achieving-10000x-training-data-reduction-with-high-fidelity-labels/?s=09
 豫公网安备41010702003375号
豫公网安备41010702003375号