
阿里达摩院开源三大具身智能核心成果,推动机器人全流程适配
![]() 前沿资讯
1754900223更新
前沿资讯
1754900223更新
![]() 1
1
8月11日消息,在2025世界机器人大会上,阿里巴巴达摩院正式宣布开源三款具身智能核心组件:视觉-语言-动作(VLA)大模型RynnVLA-001-7B、世界理解模型RynnEC,以及全球首个面向具身智能场景的机器人上下文协议RynnRCP。这是继上月开源WorldVLA后,达摩院连续第二次向社区开放核心算法与协议,旨在解决行业长期存在的“数据-模型-机器人”碎片化适配难题,推动具身智能开发进入“即插即用”时代。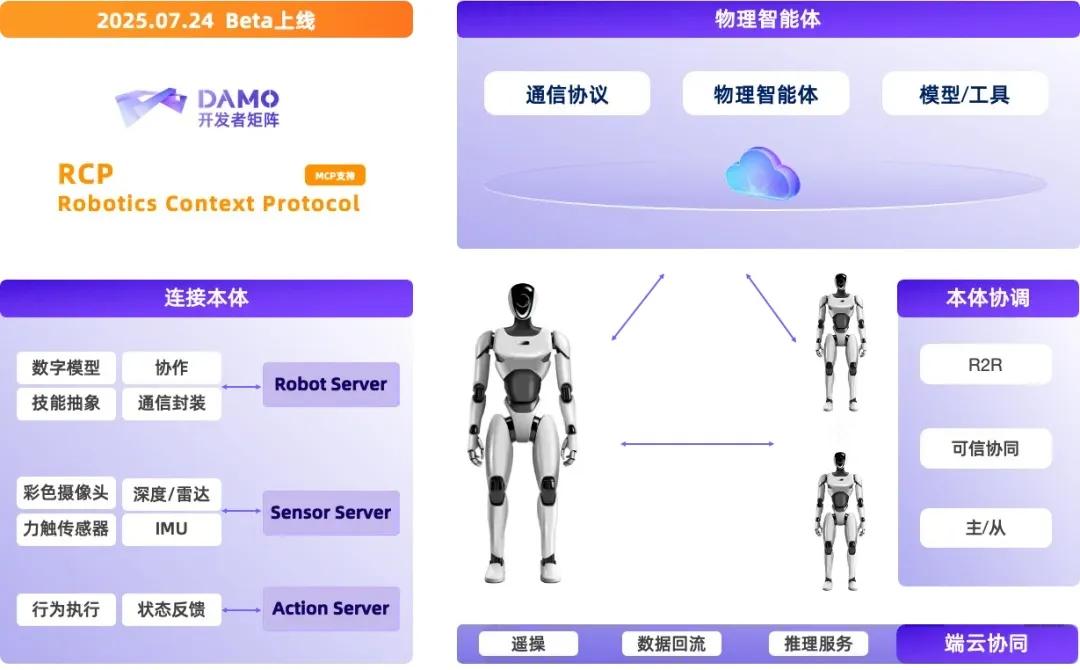
痛点:开发流程割裂、迁移成本高昂。虽然具身智能赛道近年呈爆发式增长,但机器人本体、传感器、算法模型往往来自不同厂商,接口与数据格式各异,导致开发者需要为每一款硬件重复“造轮子”。
方案:RCP协议打通全链路。为此,达摩院首次将大模型领域已验证的MCP(Model Context Protocol)理念引入机器人场景,推出并开源RynnRCP(Robotics Context Protocol)。该协议通过标准化数据流与控制流接口,实现从传感器采集、云端(或本地)推理到本体执行的完整闭环。目前,RynnRCP已原生支持Pi0、GR00T N1.5等热门模型,以及SO-100、SO-101等多款机械臂,后续将面向更多生态伙伴开放适配接口。
RynnRCP由两大核心模块构成:
- RCP框架:负责机器人本体、传感器与模型服务的标准化对接,兼容多种传输层和模型服务。
- RobotMotion:作为“大脑”与“小脑”之间的桥梁,把大模型输出的低频离散指令实时转换为高频连续控制信号,确保动作平滑且符合物理约束。RobotMotion还内置一体化仿真-真机工具链,支持任务规控、轨迹可视化、数据采集与回放,显著降低策略迁移门槛。
让机械臂“像人一样”学习。此次开源的RynnVLA-001-7B,是达摩院自主研发的视觉-语言-动作大模型。该模型基于大规模第一人称视角视频与人手轨迹进行预训练,可隐式迁移人类操作技能至机械臂,实现连贯、平滑且类人化的抓取与操控。在内部测试中,RynnVLA-001-7B在复杂桌面场景中表现出更高的抓取成功率和更平滑的动作。
同期开源的RynnEC,则是一款面向“世界理解”的多模态大模型。它无需任何3D先验,仅凭视频序列即可在11个维度(位置、功能、数量、材质等)解析场景物体,并实时完成目标检测、分割与空间定位。实验数据显示,RynnEC在复杂室内环境中可精准定位和分割目标物体,为后续任务规划提供了高精度语义支撑。
“开源不是终点,而是生态的起点。”达摩院表示,未来,将联合高校、厂商及社区开展合作活动,完善RynnRCP的设备与模型生态。
业内分析认为,随着核心协议与基座模型的全面开放,具身智能或将复制当年移动互联网“应用井喷”的路径,迎来新一轮产业爆发。
开源链接:
● 机器人上下文协议RynnRCP:
https://github.com/alibaba-damo-academy/RynnRCP
● 视觉-语言-动作模型 RynnVLA-001:
https://github.com/alibaba-damo-academy/RynnVLA-001
● 世界理解模型 RynnEC:
https://github.com/alibaba-damo-academy/RynnEC
参考资料:达摩院开源具身智能“三大件” 机器人上下文协议首次开源
 豫公网安备41010702003375号
豫公网安备41010702003375号