
昆仑万维发布SkyReels-A3模型:声画合一,让数字人“开口说话”
![]() 前沿资讯
1754991702更新
前沿资讯
1754991702更新
![]() 1
1
8月11日消息,昆仑万维SkyWork AI技术发布周正式启动。据介绍,8月11日至15日,连续五天,每天都会发布一款覆盖多模态AI核心场景的新模型。11日当天,昆仑万维正式发布全新一代音频驱动人像视频生成模型SkyReels-A3。该模型融合DiT(Diffusion Transformer)视频扩散模型、插帧延展技术、基于强化学习的动作优化算法及可控运镜模块,可实现任意时长的全模态音频驱动数字人创作,让静态人物因声音而“活”起来。
作为一款面向大众与专业创作者的Audio-driven Avatar技术,SkyReels-A3支持三大核心应用场景:
1. 照片开口说话/唱歌:上传任意人像照片并配上语音,即可生成自然口型和表情的视频。
2. 定制情境表演:结合图片、语音与文本提示(Text Prompt),驱动数字人进行指定情绪、姿态与场景表演。
3. 视频改台词:替换原视频的音频,人物口型、表情及肢体动作将与新语音同步,而画面衔接自然流畅。
SkyReels-A3在唇形同步与动作自然度上进一步提升,支持分钟级单镜头视频和无限时长多镜头生成,且在广告、直播带货等高互动场景中实现特定动作优化,让数字交互更逼真。
为了突破传统数字人单一、呆板的固定镜头,SkyReels-A3内置基于ControlNet架构的专业运镜模块,支持八种常见镜头运动(静态、推拉镜、摇镜、抬升、下降、手持)及0–100%强度调节。通过帧级运镜控制与场景深度信息提取,创作者能够生成如电影或音乐MV般的高艺术感视频。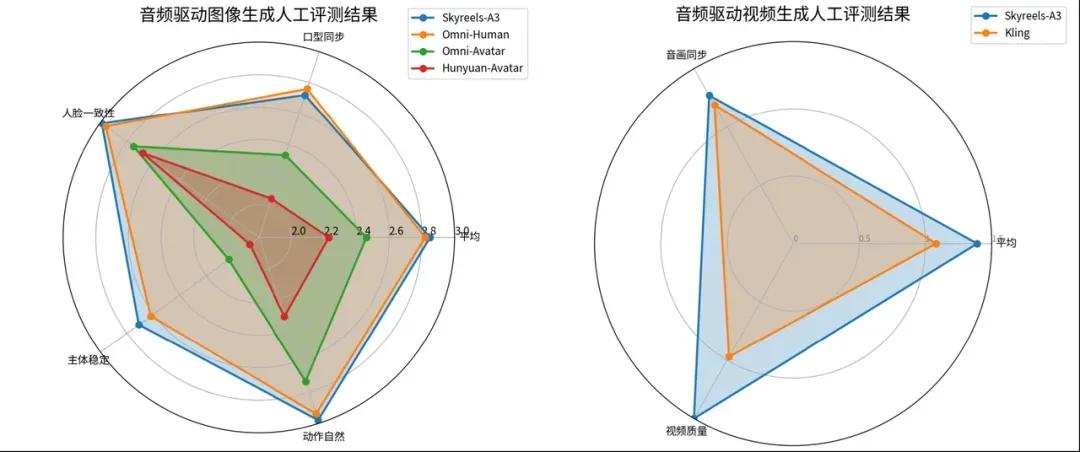
SkyReels-A3基于DiT视频扩散架构与3D变分自编码器(3D-VAE),实现视频在空间与时间维度的高效压缩与生成,大幅降低计算成本的同时保留细节。
对比开源模型OmniAvatar和闭源模型OmniHuman,SkyReels-A3在唇形同步(sync-c、sync-d)、动作稳定性及视频质量方面均取得领先。在推理速度上,SkyReels-A3通过引入Step蒸馏技术,将生成步数从40步降至4步,生成效率提升近十倍。
昆仑万维表示,从胶片到数码、从二维到三维,每一次影像技术的飞跃都在改变内容生产方式。SkyReels-A3的目标,是让“声音即影像”成为人人可触的创意工具,而无需摄影棚与高端设备,一段声音、一张照片,就能生成高保真、长时长、可控创意的视频内容。
访问体验:
* SkyReels-A3项目主页:https://skyworkai.github.io/skyreels-a3.github.io/
* SkyReels官网(登录后选择Talking Avatar工具):https://www.skyreels.ai/home
* 开源模型地址:https://huggingface.co/Skywork
参考资料:Day1/5:SkyReels-A3——形随声动,让数字人“说话”的魔法
 豫公网安备41010702003375号
豫公网安备41010702003375号