
Liquid AI今日开源LFM2-VL系列视觉-语言基础模型
![]() 前沿资讯
1755082366更新
前沿资讯
1755082366更新
![]() 0
0
8月13日消息,专注端侧人工智能的Liquid AI公司宣布推出其首个视觉-语言基础模型家族——LFM2-VL,并在全球最大开源社区Hugging Face同步上线全部权重与示例代码。新系列主打“低延迟、省资源”,可在手机、笔记本电脑、单GPU服务器乃至智能手表等设备上实现接近云端大模型的多模态理解与生成能力。
LFM2-VL提供两个版本:
• LFM2-VL-450M:极端资源受限场景而生,仅需450M参数即可运行;
• LFM2-VL-1.6B:在保持轻量的同时带来更强表现,总参数量16亿。
官方测试显示,在典型GPU环境下,两者推理速度均达到同量级主流模型的2倍,而准确率与参数量更大的对手持平甚至超越。
与多数模型强制拉伸或压缩图片不同,LFM2-VL支持原生分辨率输入,最大512×512像素无需缩放,更大图片则被自动切分为512×512不重叠块,避免失真并保留细节。LFM2-VL-1.6B还额外引入一张低分辨率“缩略图”作为全局上下文,提升场景整体理解能力。
开发者可在推理阶段实时调整输入token数量与图像分块数目,无需重新训练即可在精度与延迟间做平衡。以1024×1024输入、生成100字描述为例,LFM2-VL在RTX 4090上耗时仅120ms,比现有最快竞品缩短一半,显存占用也降低30%以上。
架构三件套:语言塔、视觉塔、跨模态连接器
• 语言塔:继承自LFM2-1.2B/350M;
• 视觉塔:采用SigLIP2 NaFlex编码器,提供86M(Base)与400M(Shape-optimized)两种规格;
• 连接器:2层MLP+ Pixel Unshuffle技术,将图像token数压缩4倍,显著提升吞吐。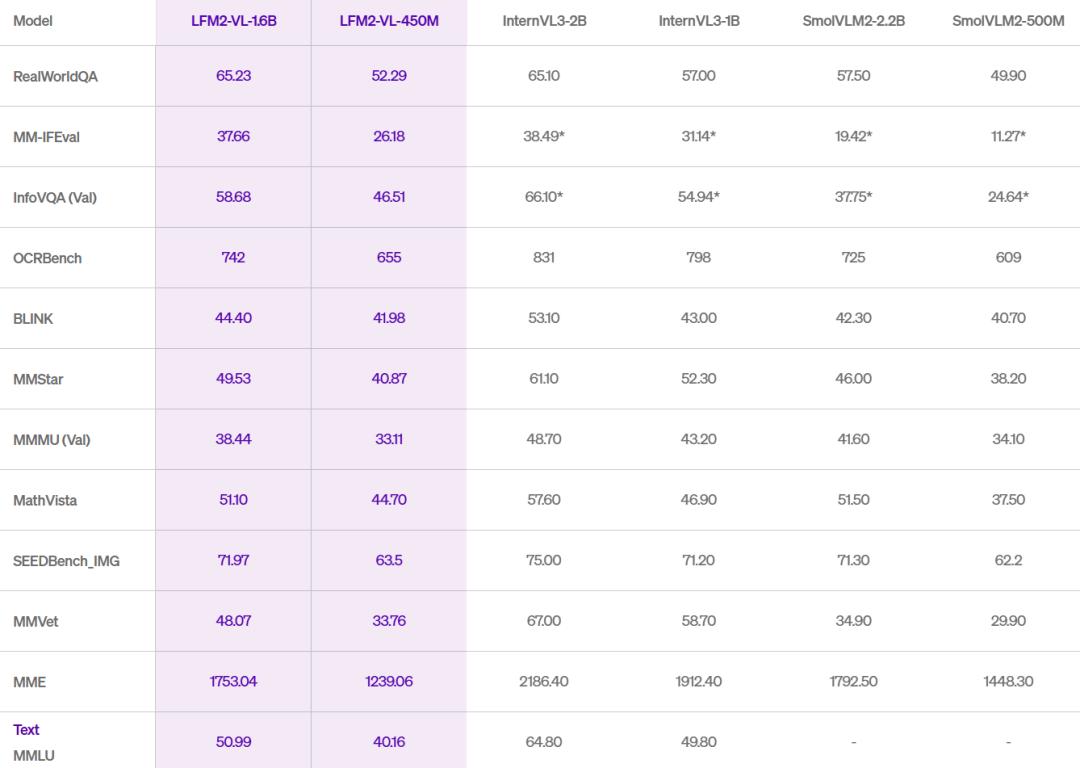
基准成绩亮眼:
• MMBench(多模态综合):LFM2-VL-1.6B取得79.4分,超越同量级SmolVLM2-2.2B;
• InfoVQA(图表问答):LFM2-VL-1.6B得分42.1,逼近7B规模大模型;
• MM-IFEval(指令跟随):LFM2-VL-450M在端侧模型中排名第一。
开发者可即刻通过Hugging Face下载模型权重与微调示例Colab,兼容transformers与TRL。官方正与社区合作,后续将支持更多推理框架(如llama.cpp、Ollama等)。LFM2-VL采用基于Apache 2.0的开放许可证,年收入低于1000万美元的企业亦可免费商用,超出该门槛仅需联系Liquid AI获取商业授权。
参考资料:https://www.liquid.ai/blog/lfm2-vl-efficient-vision-language-models
 豫公网安备41010702003375号
豫公网安备41010702003375号