
“创意写作”能力大比拼,17款模型,Kimi K2-0905拔得头筹
![]() 前沿资讯
1757667826更新
前沿资讯
1757667826更新
![]() 0
0
摘要:“LLM创意故事写作基准V3”公布了17款主流AI模型的创意写作能力排名,Kimi K2-0905以8.749的平均分登顶,GPT-5(medium reasoning)、通义千问3 Max Preview分列二三位,测评通过严格控制故事元素与长度、多AI评分及稳健性检验确保结果可信。
哪款AI最会写故事?最近,“LLM创意故事写作基准V3”(LLM Creative Story-Writing Benchmark V3)公布了答案,该评测专门考验AI能否按指定要求写出引人入胜的虚构故事。
该测评的标准很明确:只比写作质量和元素融合度。每个模型都需要把十个指定的元素自然地融入到故事当中,比如特定的角色、物品、场景、语气等等,而且故事长度被严格控制在600到800字,以避免有模型靠“凑字数”占便宜。
打分环节,会让7个独立的“评分模型”分别用18道题的评分表打分。这18道题主要分两类:8道题看故事本身的质量,比如角色塑造够不够立体、情节通不通顺、文字好不好,另外10道题专门检查那十个指定元素有没有被自然融入。最后会用一套加权计算方式得出每个故事的分数,再算出每个模型的平均分。
从最终排名来看,头部模型的竞争很激烈。排在第一的是Kimi K2-0905,平均分8.749,紧随其后的是GPT-5(medium reasoning),平均分8.723。第三名是通义千问3 Max 预览版,平均分8.711。前四名里还有一个Kimi K2,排第四,平均分8.693,能看出Kimi系列在创意写作上确实有优势。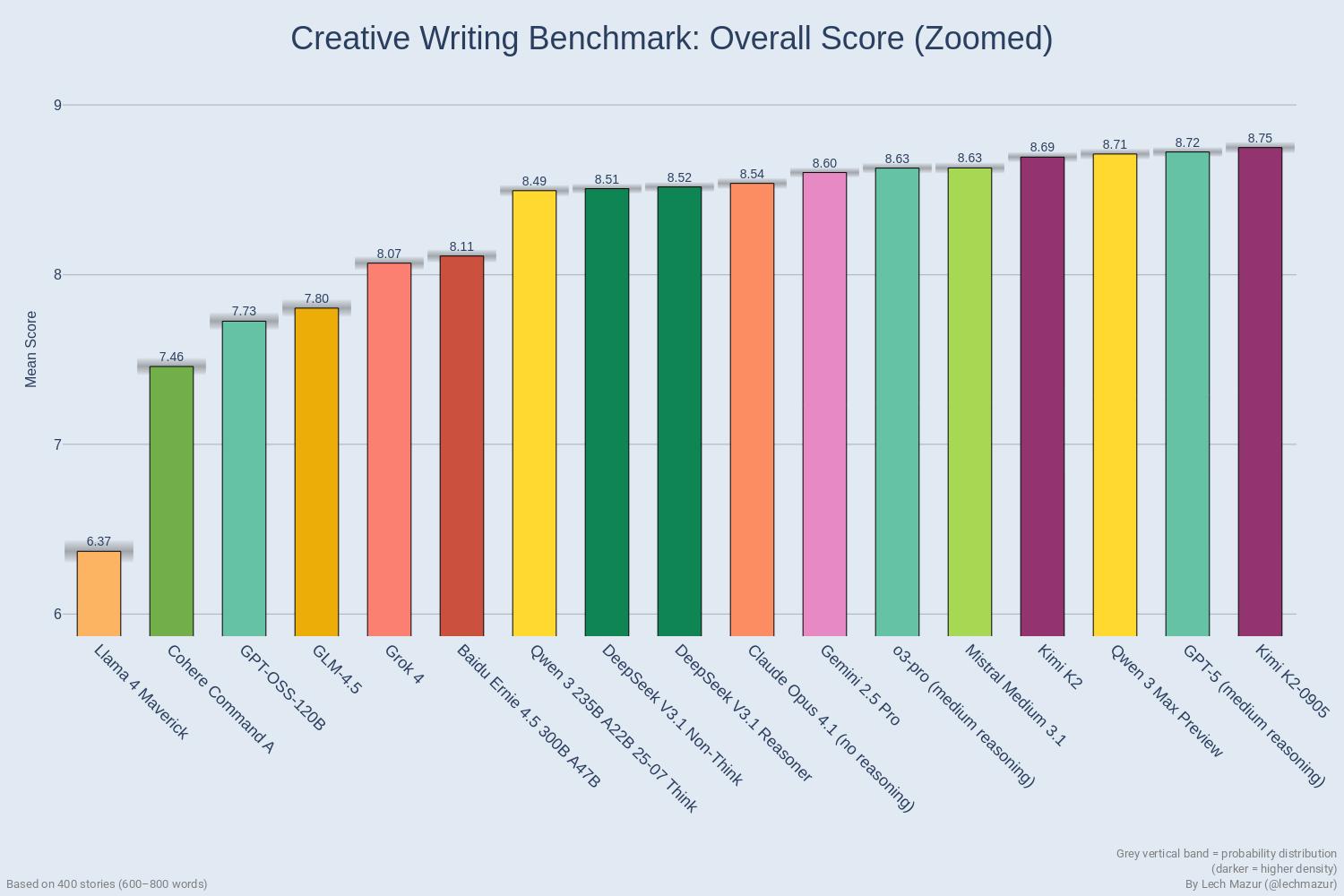
除了看平均分,测评还做了“归一化排名”,以消除不同评分标准的差异,结果显示,Kimi K2-0905还是第一,通义千问3 Max预览版升到了第二,GPT-5(medium reasoning)则落到第三。但不管怎么排,前七名的差距都不大,都在8.6分以上,属于第一梯队。
但,排名靠后的模型分数差距比较明显。比如排12名的百度文心一言4.5(Baidu Ernie 4.5 300B A47B)平均分8.110,而最后一名Llama 4 Maverick只有6.370,和头部模型差了一大截。
为了确保结果靠谱,测评还做了好几轮“稳健性检验”。比如把每个模型得分最低的10%故事去掉再算分,或者每次排除一个评分模型再重新排名,结果发现前几名的顺序基本没变化,说明这个排名还是可信的。而且,测评还检查了评分模型之间的“意见一致性”,发现它们对故事质量和元素融合的判断大多能对齐,不会出现“甲说极好、乙说极差”的情况。
当然,测评也说了自己的局限,比如目前只看单个故事的质量,没考虑AI写作风格的多样性,而且评分还是靠AI完成,不是人类评委。但不管怎么说,这份排名还是给大家提供了一个参考:如果想让AI帮忙写点有创意的小故事,优先试试头部的那几款模型,大概率不会让人失望。
参考资料:https://github.com/lechmazur/writing/;https://x.com/LechMazur/status/1965729450940588459
 豫公网安备41010702003375号
豫公网安备41010702003375号