
新研究拆解大模型长任务执行能力:单步微小进步可撬动长期指数级提升
![]() 前沿资讯
1757845173更新
前沿资讯
1757845173更新
![]() 2
2
摘要:来自剑桥大学和斯图加特大学的研究团队,针对“大模型是否值得继续扩展”等争议问题,给出了新的实验结果。他们发现:模型单步准确率的微小提升,会带来任务长度处理能力的超指数级增长,证明规模扩展仍有价值。
一直以来,“大模型持续升级会面临收益递减”的声音不绝于耳,毕竟从短期任务测试结果看,模型规模扩大后,单步准确率的提升似乎越来越慢。
来自剑桥大学、斯图加特大学等机构的研究团队,针对“小模型是否是智能体未来”“大模型算力投入是否因收益递减而不值”“自回归模型是否注定淘汰、‘思考’只是错觉”等热议问题给出了新答案。他们发现:模型能处理的任务长度,会随着单步准确率的提升呈超指数级增长。
为精准探究核心问题,研究团队把“规划”和“执行”进行了拆分。以往,大模型处理长任务失败,经常被归咎于“不会规划”,但这次实验中,研究人员直接给模型提供了明确的任务计划和所需信息,只让它负责“按计划执行”。
实验结果出人意料:以参数规模较大的Qwen3-32B和Gemma3-27B为例,在准确率不低于50%的前提下,它们能正确完成的回合数,远多于40亿参数的小模型。这说明,对大模型而言,哪怕规划和知识都已齐备,单纯的“执行”本身也并非易事,更不能把执行失败等同于“不会推理”。
研究还发现了一个反直觉的“自我条件反射效应”:很多人可能遇到过“模型处理任务越久,表现越差”的情况,过去常认为是“长上下文能力不足”,但实验证明并非如此。当模型看到自己之前犯过的错误记录,后续犯错的概率会显著增加。更特别的是,模型规模越大,这个问题反而越明显,成为罕见的“反向缩放”案例。
不过,“思考型模型”却能破解这个困局。这类模型即便看到了之前的错误记录,也不会受其影响,因为它们在推理时不参考之前回合的历史轨迹,且更关注任务成功而非延续上下文格式。
研究明确,“思考”并非错觉,而是执行能力的核心。比如DeepSeek-V3、Kimi K2这类模型,如果不开启链式推理(CoT),连5步隐藏执行都难以完成,但开启推理后,能完成的步骤直接翻了10倍。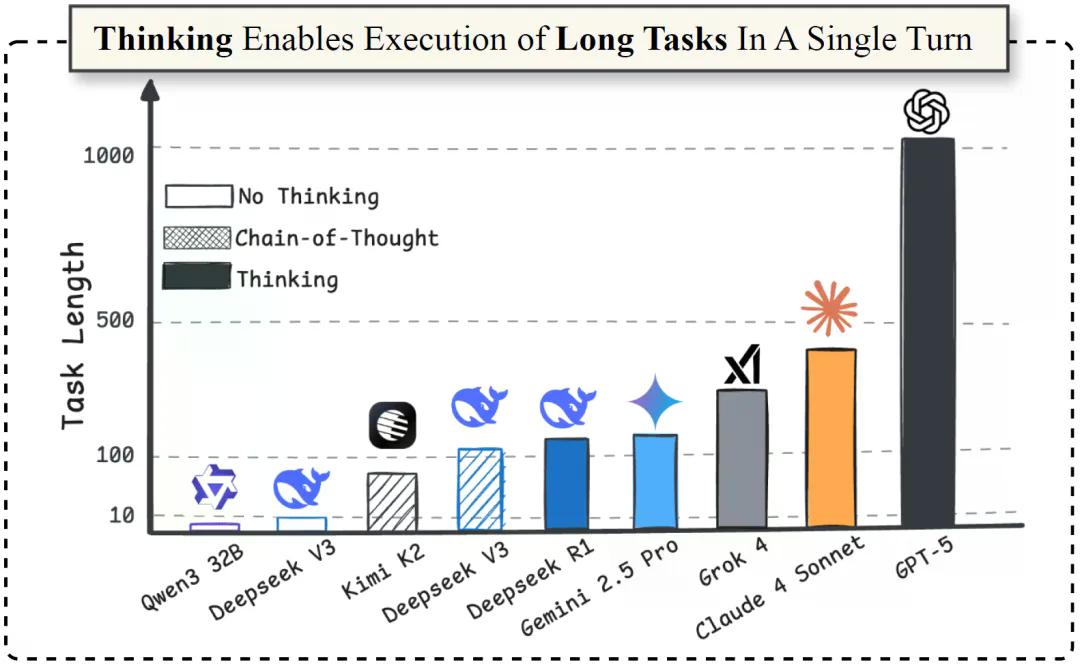
在顶尖模型的测试中,各模型表现差距明显:GPT-5的“思考版”表现远超所有同类,一次能完成1000多步的任务,研究团队也好奇:“这会不会是GPT-5代号为‘Horizon(地平线)’的原因?”排名第二的Claude-4-Sonnet能完成432步,Grok-4以384步紧随其后,而Gemini 2.5 Pro和DeepSeek R1则相对落后,仅能完成120步。
值得关注的是,目前,开源模型如Qwen3、Gemma3系列在长任务执行能力上,仍落后于GPT-5、Claude-4-Sonnet等闭源模型,还有很长的路要走。不过研究团队已公开了所有实验代码和数据集,希望能凝聚更多力量,共同推进开源模型的长任务能力升级。
这项研究也为业界提供了新的评估视角:不能只看短任务表现来判断大模型价值,从长任务执行能力来看,持续的规模投入和算力优化,依然能带来显著回报。
参考资料:https://arxiv.org/abs/2509.09677
 豫公网安备41010702003375号
豫公网安备41010702003375号