
DeepMind联合发布VaultGemma:性能“拉胯”但“隐私保护”能力极强
![]() 前沿资讯
1757927551更新
前沿资讯
1757927551更新
![]() 0
0
摘要:Google DeepMind联合发布VaultGemma,这是一款采用差分隐私训练的10亿参数开源模型。研究团队首次总结了“隐私训练规律”,揭示算力、数据与隐私之间的平衡关系,并将成果应用到VaultGemma的训练中。测试结果显示,该模型在保护隐私的同时,性能已接近非隐私模型五年前的GPT-2水平,为未来开发兼顾隐私与实用性的AI提供了重要参考。
随着人工智能逐渐融入日常生活,如何在保障隐私的前提下训练和使用智能系统,成为业内绕不开的话题。近日,Google DeepMind与合作团队正式推出了VaultGemma,一款在训练过程中全面引入“差分隐私”机制的大型开源模型。
差分隐私的核心思路,是在训练时加入精心设计的“噪声”,避免系统死记硬背个人数据。这种方法虽然能强化隐私保护,却常常带来训练不稳定、算力消耗高等难题。为了找到其中的平衡点,研究团队进行了大规模实验,总结出了新的“隐私训练规律”,并以此为指导打造出VaultGemma。
据介绍,VaultGemma拥有10亿参数规模,是目前公开发布的最大差分隐私训练成果。研究团队将其权重文件上传到了Hugging Face和Kaggle,方便研究者下载使用。
在实验过程中,研究人员发现:计算预算、隐私预算和数据预算之间存在强烈的协同效应。比如单独增加隐私预算,效果会逐渐递减,必须同时提升计算预算或数据预算才能发挥作用,差分隐私下更适合采用“小模型+大批量数据”的策略。换句话说,不一定要一味追求更大的规模,而是要在隐私预算和算力预算之间找到最佳组合。最终,VaultGemma的实际表现与理论预测高度吻合,这也验证了他们总结的规律。
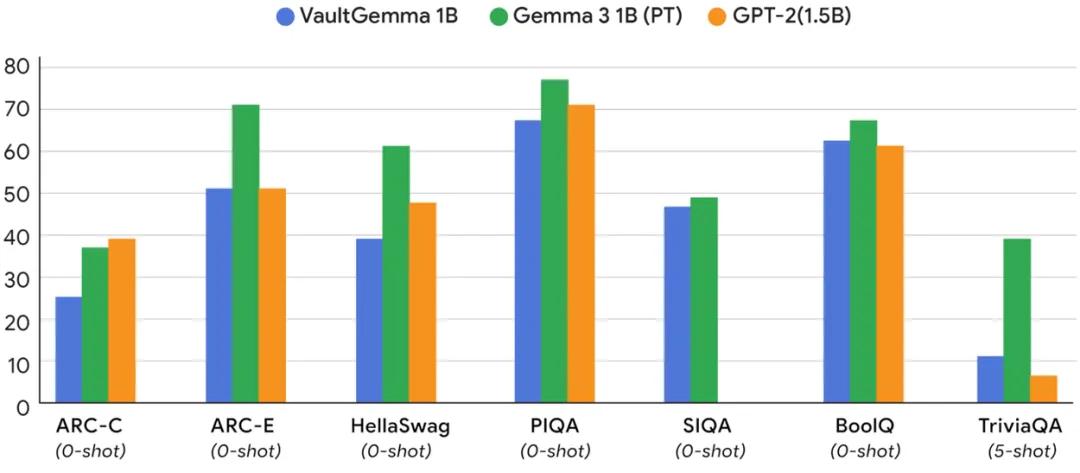
从性能对比来看,VaultGemma在一些标准测试中的成绩,接近非隐私训练模型在五年前的水平(GPT-2 1.5B)。虽然与最新的非隐私模型仍有差距,但已经展现出“隐私保护与实用性兼顾”的可行性。更重要的是,实验结果表明,该模型几乎不存在训练数据的记忆现象,真正实现了理论上的隐私保护。
研究团队强调,VaultGemma只是一个开始。未来随着训练方法的改进,差分隐私下的性能差距有望进一步缩小。他们希望这一成果能为业界提供可借鉴的路线图,推动隐私友好的智能系统走向更大规模的应用。
参考资料:https://research.google/blog/vaultgemma-the-worlds-most-capable-differentially-private-llm/
 豫公网安备41010702003375号
豫公网安备41010702003375号