
阿里最新旗舰模型Qwen3-max正式版实测:国内No.1,但比“预览版”稍弱
![]() 工具推荐
1758785806更新
工具推荐
1758785806更新
![]() 10
10
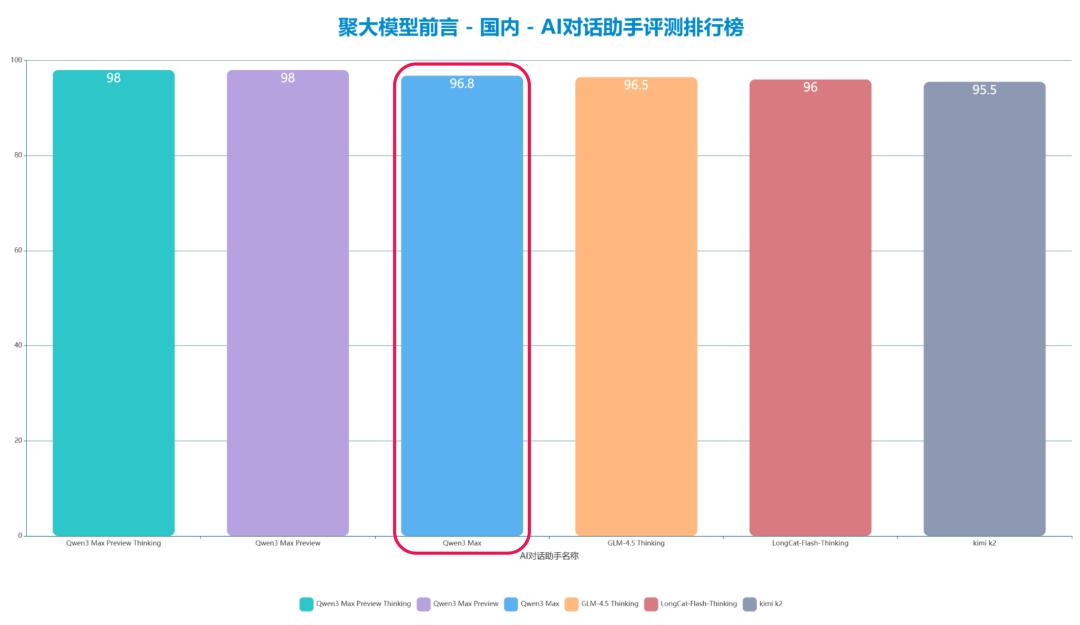
导读:阿里通义千问实验室昨天发布的最新旗舰大模型 Qwen3-Max,在「聚大模型前言」的统一测试中,排名依旧是国内第一,但分数相比预览版略有下滑。与第二名智谱 GLM-4.5-Thinking 相比,领先优势进一步缩小。
Qwen3-max,取代了此前的Qwen3-max-Preview版,被称为目前阿里规模最大、能力最强的旗舰模型。今天一早,小编使用聚大模型前言的统一AI对话助手测试框架,对该模型进行了一遍实测,结果显示:仍是国内No.1,但分数比预览版低了一些。
据悉,相比之前的版本,Qwen3-Max 在稳定性和效率上都有显著提升。借助 MoE 架构和优化过的并行策略,整个训练过程异常顺利,没有出现常见的“回退”或数据分布调整问题。同时,通过新策略,大幅减少了超大规模集群中的硬件故障损耗。
在外部评测中,Qwen3-Max-Instruct 已经跻身 LMArena 文本能力榜单的全球前三。专注于复杂推理的 Qwen3-Max-Thinking,结合了代码解释器和并行推理计算,在 AIME 25 和 HMMT 两大高难度测试中获得了满分,但目前还在训练中、没有上线。
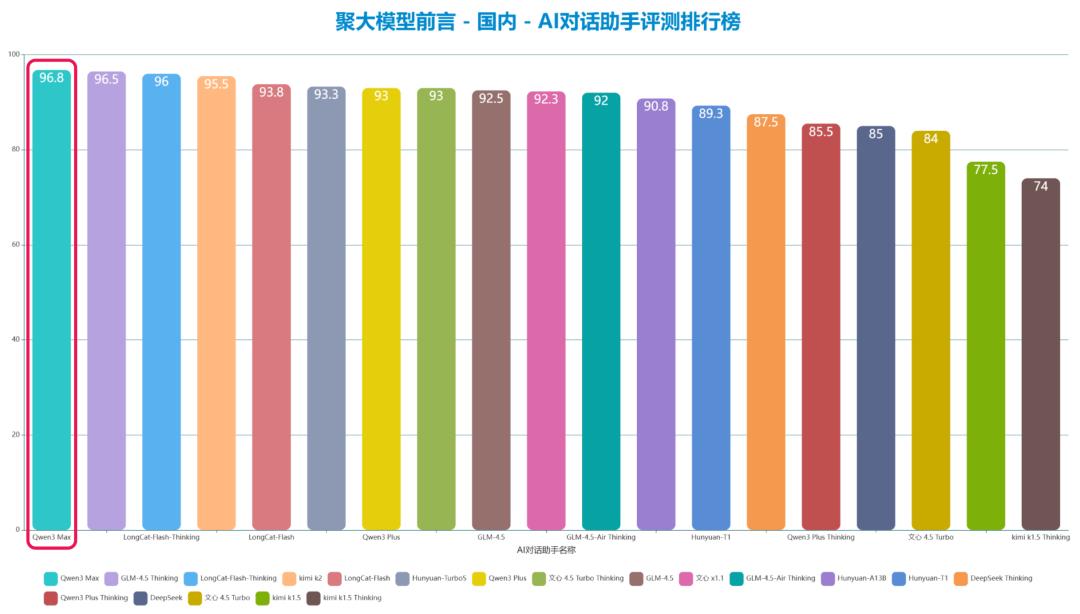
经过本轮实测,Qwen3-max 取得了 96.8 的分数,替换掉同为 98 分的 Qwen3-max -Preview-Thinking 以及 Qwen3-max-Preview 之后,在国内AI对话助手排行榜中,仍旧是第一的位置。不过,本次实测成绩与第二名的成绩差距有所收窄,第二名来自智谱AI的GLM-4.5-Thiking模型,得分96.5,差距仅有0.3分。
详细的得分差距项方面(对比 Qwen3-max-Preview 模型),首先,在对话理解力维度上,正式版直接拿下10分满分,不仅拆解得更细,还能兼顾不同可能性,并通过例子进一步验证,逻辑闭环做得很到位。
预览版得分9分。例如,在“朋友的哥哥的爸爸的儿子”这一亲属关系题中,预览版分析路径完整,但最终结论略偏,倾向于“朋友本人”,其实严格逻辑上答案应包含“朋友或朋友的哥哥”,因此被扣掉1分。时间逻辑题则处理得清晰,推理过程顺畅。
知识广度和时效性维度方面,预览版拿下10分。它能直接引用 2025 年最新的行业成果,如 Llama 3.5、DeepSeek-V3、Mistral NeMO,还附上发布时间、开源协议和应用场景,甚至对 Black Forest Labs 的最新产品(FLUX.1 Video、FLUX.1 3D)和研究方向有深入介绍。信息准确且极具时效性。
正式版稍逊,得9分,同样引用了 2025 年的开源模型(腾讯混元3D 1.0、Qwen3-Omni、智谱 GLM-Z1-Rumination),并在 Black Forest Labs 部分准确提及 FLUX.1 Kontext 和 FLUX.1 Krea,但部分引用带有预测色,因而被扣分。
在创意生成力维度上,预览版与正式版差异仅有0.5分,都表现出了相当高的水准。预览版(10分)设计的“无屏手机”系统涵盖全息投影、眼动追踪、环境交互等元素,既有前沿感又保持合理性。“虫洞集市”的文案既科幻又幽默,既用到爱因斯坦的相对论,又引用马云的经典语录,娱乐感拉满。
正式版(9.5分)延续了这种风格,提出的“全息神经交互”系统更为细致,连超声波触觉、空间音频都考虑到;在“相对论电商”创意文案中,则巧妙地把质能方程和消费体验结合起来,还带上了对钱包的调侃,读来既轻松又有想象力。
在工具使用和扩展性维度方面,预览版表现惊艳(10分)。它模拟 ImageGen.create() 的参数调用,写出了 prompt、steps、guidance_scale、style_preset 等详细字段,堪比开发文档。正式版也很扎实(9分),参数完整度稍逊一筹,但解释清晰,安全性考量也在后续有所补充。
整体来看,Qwen3-Max 依旧是国内最强模型,从预览版到正式版,它在逻辑推理上更严谨,在创意生成和工具使用上依旧保持高水平,但在知识广度和时效性上略有退步,领先优势正在缩小。
参考资料:https://x.com/GoogleAIStudio/status/1970545734736023564;https://ai.google.dev/gemini-api/docs/live?hl=zh-cn
 豫公网安备41010702003375号
豫公网安备41010702003375号