
Runway新一代视觉语言模型A2D-VL问世:速度与质量兼顾的平行生成方案
![]() 前沿资讯
1758961756更新
前沿资讯
1758961756更新
![]() 0
0
导读:视觉语言模型(VLM)正变得越来越重要,从图像描述到视觉问答,它们已经深度影响着AI应用。然而,传统自回归模型生成速度慢,扩展受限。Runway最新推出了一个Autoregressive-to-Diffusion(A2D)视觉语言模型,通过将自回归模型改造为平行扩散解码,带来了更快的推理速度和可控的质量-速度平衡。
视觉语言模型(VLM)通过理解图像和视频,并生成相应的文字内容,支撑着从图像描述到复杂视觉问答的多种应用。过去,自回归VLM通常逐步生成文本,这限制了推理速度和并行化能力。近年来,扩散解码器成为一种新兴方案,可以同时生成多个token,实现更高效的推理。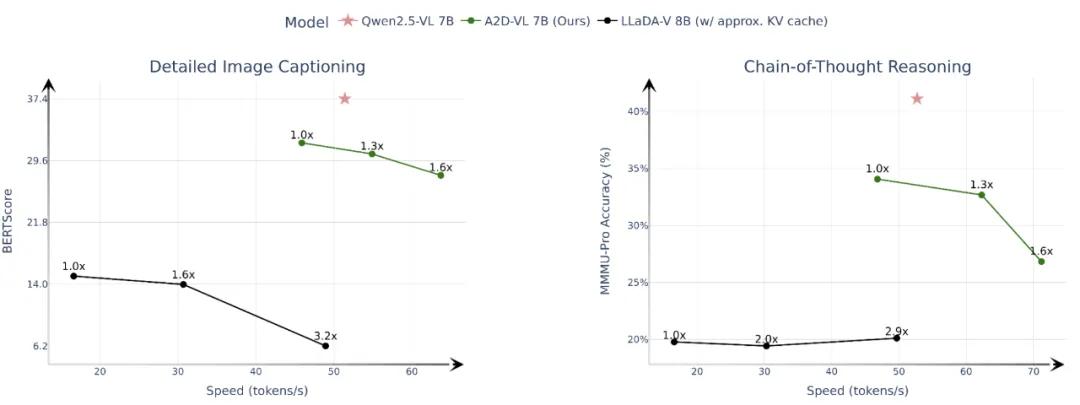
然而,现有扩散VLM在实际应用中面临几个难题:
- 训练成本高:传统扩散VLM需要数千万视觉问答数据进行训练,计算消耗巨大。
- 架构落后:缺乏对现代视觉特性支持,如原生分辨率、多模态位置编码等。
- 长文本质量下降:对长序列的生成能力有限,容易出现质量衰减。
- 缓存支持不足:缺少高效的KV缓存机制,导致推理效率低下。
为解决这些问题,Runway研究团队提出了A2D-VL 7B(Autoregressive-to-Diffusion)模型。其核心创新在于:
- 利用现有自回归模型:在不从零训练的情况下,将Qwen2.5-VL(Qwen2.5-VL)自回归模型改造成扩散解码,实现平行生成。
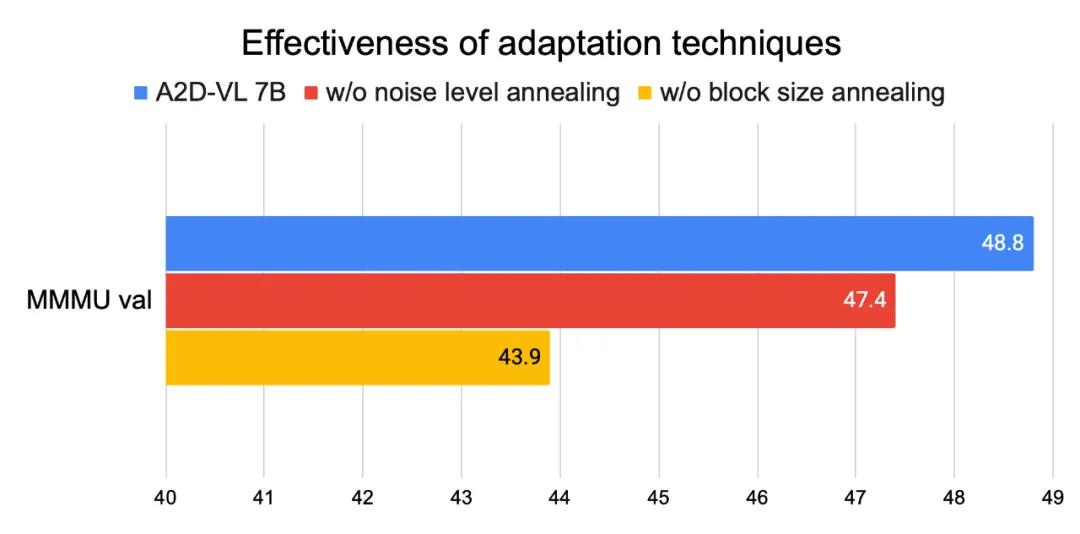
- 渐进式微调策略:通过“块大小退火”和“噪声水平退火”,模型逐步从序列生成过渡到并行生成,同时保持原模型能力。
- 块式扩散解码:每次生成8个token,兼顾生成质量和长序列扩展性。
- 支持精确KV缓存:通过块因果注意力机制,缓存先前生成块,提高推理效率。
在性能测试中,A2D-VL表现亮眼:
- 图像描述:生成的详细描述(≤512 tokens)与GPT-4o、GPT-4V等参考结果一致性更高。
- 链式推理:在长序列推理任务中,准确率优于LLaDA-V等既有扩散VLM。
- 视觉问答:在5个主流视觉问答基准中,A2D-VL在3项取得领先成绩,同时性能几乎不低于Qwen2.5基模型。
- 速度-质量平衡:通过调节生成步数,实现并行化加速,同时保持可控的输出质量。
与传统扩散VLM相比,A2D-VL在训练成本上显著降低:仅需约40万对视觉问答样本,而不是几千万,同时,采用现代化架构组件,提升了长文本生成和多模态处理能力。
A2D-VL的出现,标志着自回归模型向扩散解码的高效转换成为可能,为视觉语言理解任务提供了新的速度与性能平衡方案。
参考资料:https://runwayml.com/research/autoregressive-to-diffusion-vlms
 豫公网安备41010702003375号
豫公网安备41010702003375号