
Liquid Nanos发布:手机和笔记本也能跑前沿AI模型
![]() 前沿资讯
1758969338更新
前沿资讯
1758969338更新
![]() 0
0
导读: AI 不再只属于云端大模型。Liquid Nanos 系列正式发布,这是一批 3.5 亿到 26 亿参数的轻量级基础模型,可直接在手机、笔记本和嵌入式设备上运行。它们在特定任务上的表现可媲美体量大百倍的模型,同时无需依赖云端。重点:小模型、高性能、低延迟、隐私友好。
Liquid Nanos:小体量也能跑前沿 AI
近年来,AI 的发展越来越依赖超大模型和大型数据中心,但在现实应用中,我们面临成本、能耗、延迟和隐私的限制。将所有数据发送到云端,很多场景难以普及。
Liquid Nanos 颠覆了这一模式:将紧凑、高性能的智能直接部署到设备端,带来更快响应、更高隐私保护和可控成本。

这些模型属于 LFM2 系列低延迟任务专用液态基础模型(Liquid Foundation Models),占用内存仅 100MB–2GB,经过先进预训练和专门后训练,在智能代理的核心任务上表现出前沿级水平,包括:
- 精准数据提取和结构化输出生成
- 多语言理解
- 长上下文检索增强生成(RAG)
- 数学与推理
- 工具/函数调用
即便参数量只有数亿到约 10 亿,Nanos 在针对任务上的表现可接近甚至超过大型模型,同时完全在设备端运行。
首批实验性任务模型上线
目前首批发布的任务专用 Nanos 包括:
- LFM2-Extract(350M / 1.2B):从非结构化文本中提取数据,如将发票邮件转为 JSON 对象,多语言支持。
- LFM2-350M-ENJP-MT:350M 参数双向英日翻译模型,速度快、可离线运行。
- LFM2-1.2B-RAG:优化长上下文问答的检索增强生成模型。
- LFM2-1.2B-Tool:面向工具调用和代理操作的 1.2B 参数模型。
- LFM2-350M-Math:解决数学问题的推理模型。
- Luth-LFM2 系列:社区驱动的法语微调模型,可做本地聊天助手,同时保留英语能力。
这些模型可直接在 LEAP 平台(https://leap.liquid.ai/)(iOS、Android、笔记本)使用,也可在 Hugging Face 下载。
1. 数据提取(LFM2-Extract)
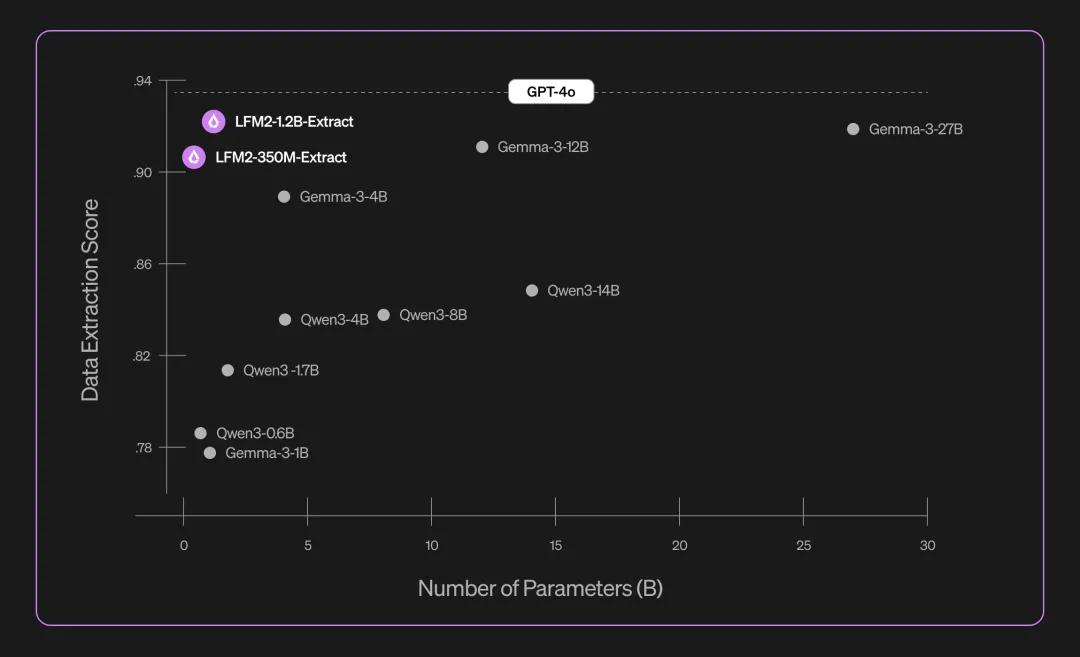
核心任务表现亮点
可将各种文档(文章、报告、转录文本)转为 JSON、XML 或 YAML 输出,支持多语言。典型应用:
- 邮件发票自动生成结构化数据
- 合规系统中规章文档转换
- 客服工单数据分析
- 知识图谱实体抽取
经过 5000 篇文档测试,LFM2-1.2B-Extract 在多语种复杂对象提取上的表现超过 22.5 倍体量的 Gemma 3 27B。
2. 英日翻译(LFM2-350M-ENJP-MT)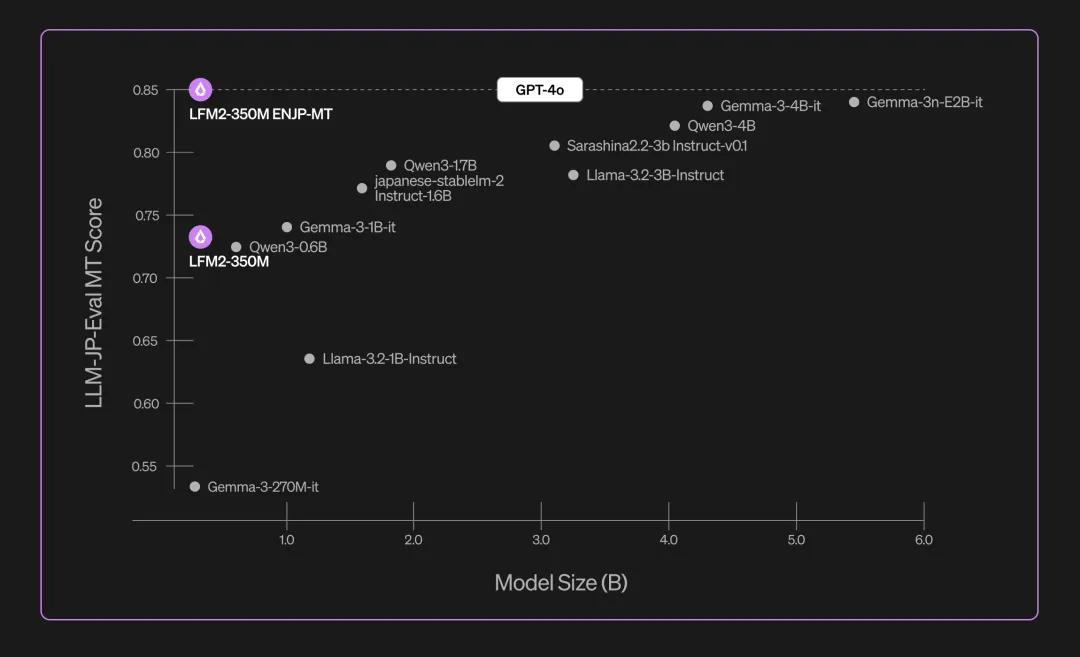
支持双向英日翻译,速度快、低延迟、可离线,适合手机、平板或笔记本使用。在 llm-jp-eval 公共基准上表现优于体量大十倍以上的一般模型。
3. 长上下文问答(LFM2-1.2B-RAG)
专注于基于文档的问答,可做产品文档查询、企业知识库助手或学术研究助理。支持多轮对话和多文档信息检索,在多语言场景下表现稳健。
4. 工具调用(LFM2-1.2B-Tool)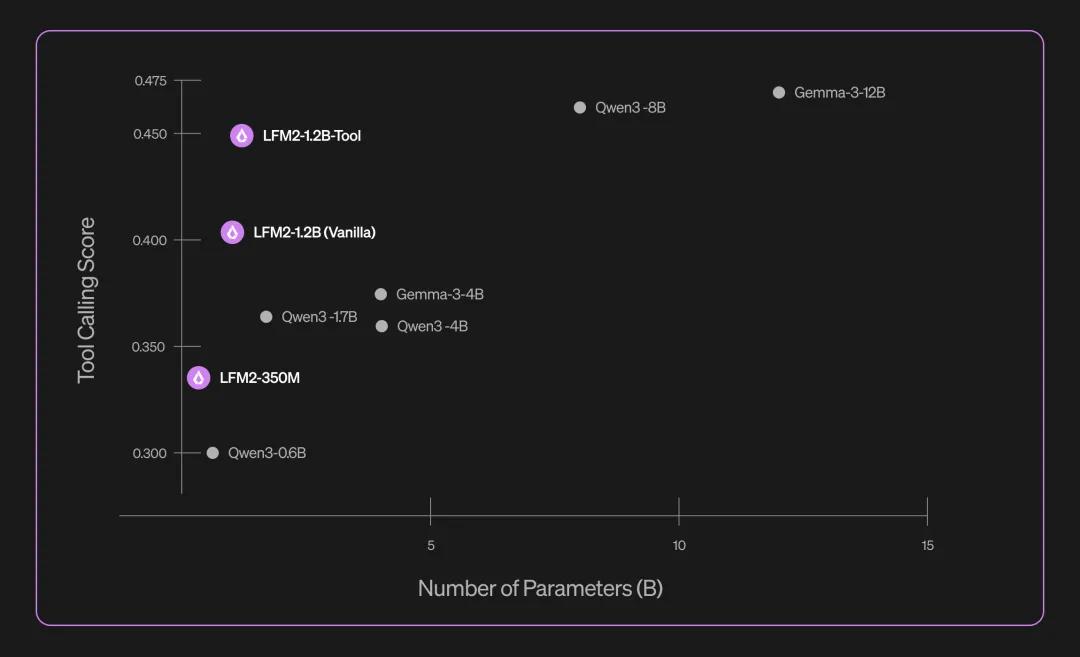
专为移动和边缘设备设计,支持 API 调用、数据库查询和系统集成,无需云端即可实现实时响应,保证低延迟体验。
5. 数学推理(LFM2-350M-Math)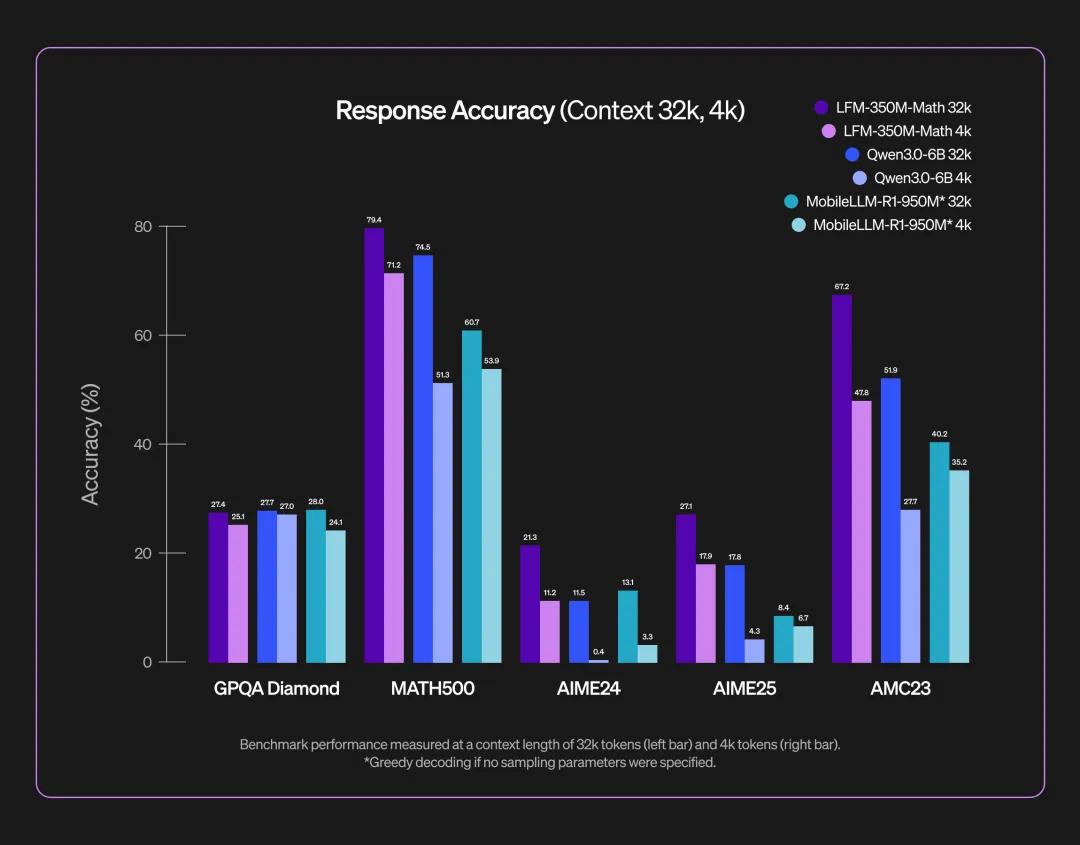
轻量推理模型,针对复杂数学问题提供多策略思考和自我验证,结合强化学习优化回答简洁性与准确性。
6. 法语微调(Luth-LFM2 系列)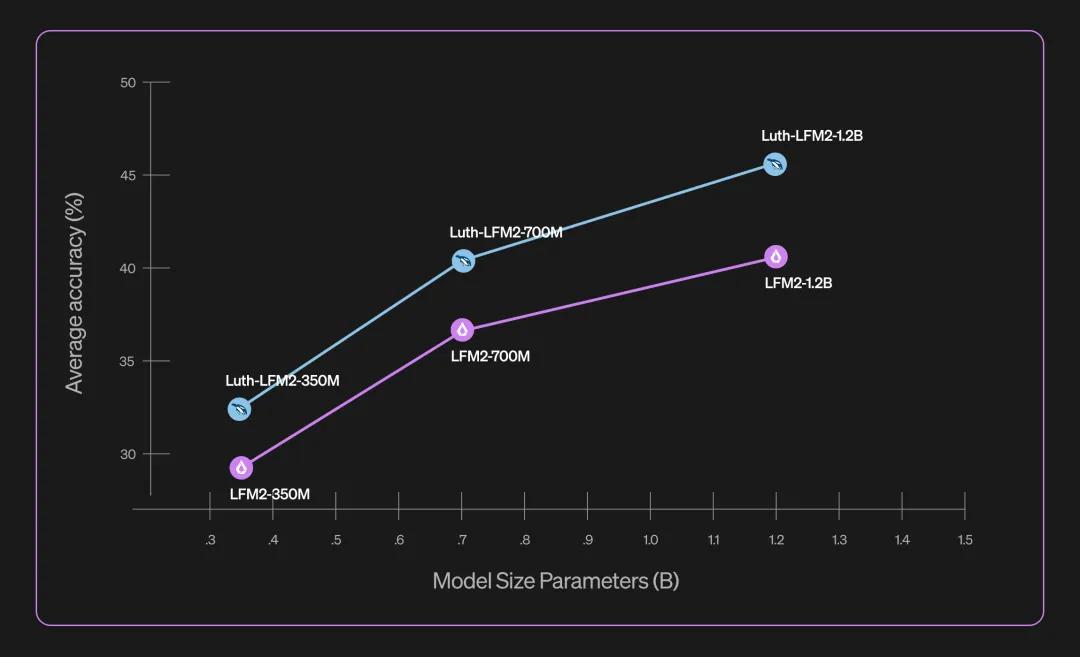
由社区开发,支持法语和英语双语,本地运行低延迟、可离线处理,提升专业考试和文档处理能力。可用性与部署
Liquid Nanos 开放许可,支持学术、开发者和中小企业使用。开发者可直接组合不同模型,构建完整代理系统,实现前沿性能和设备端低成本、低延迟运行。
参考资料:https://www.liquid.ai/blog/introducing-liquid-nanos-frontier-grade-performance-on-everyday-devices
 豫公网安备41010702003375号
豫公网安备41010702003375号