
腾讯开源HunyuanImage-3.0:国内首个超大规模图像生成开源项目发
![]() 前沿资讯
1759052610更新
前沿资讯
1759052610更新
![]() 0
0
导读:腾讯正式发布了新一代开源图像生成项目 HunyuanImage-3.0,并同步公开了技术报告、推理代码和权重文件。这是目前开源社区中规模最大的图像生成项目之一,支持文本生成图像、图像到图像转换以及多轮交互。其亮点包括:统一架构设计、超大规模专家混合模型(MoE)以及更贴近人类理解的生成表现。
9月28日,腾讯发布了 HunyuanImage-3.0,并宣布该项目全面开源。用户不仅可以查看技术报告,还能直接下载推理代码和模型权重,用于本地运行和二次开发。
与常见的扩散式架构不同,HunyuanImage-3.0 采用了统一的自回归框架,把文字和图像的理解、生成纳入同一个体系。这样做的好处是,生成的图片能更准确地呼应文字描述,细节和语境的还原度也更高。
在参数规模上,这一版本也颇为亮眼。HunyuanImage-3.0 是目前最大规模的开源图像生成专家混合模型,共有 64 个专家网络,总参数量达到 800 亿,推理时每个 token 激活约 130 亿参数,显著提升了生成效果。
腾讯方面介绍,这一代在数据筛选和强化学习训练上做了大量工作,使得生成结果在语义准确性和视觉表现之间找到了最佳平衡。用户给出简短提示时,系统还能自动补充合理的细节,让画面更加完整。
除了文本生成图像,HunyuanImage-3.0 还支持图像到图像转换和多轮交互生成,适合更复杂的创作场景。官方在 GitHub 上提供了安装指南、本地运行教程,以及基于 Gradio 的交互式网页演示,方便开发者快速上手。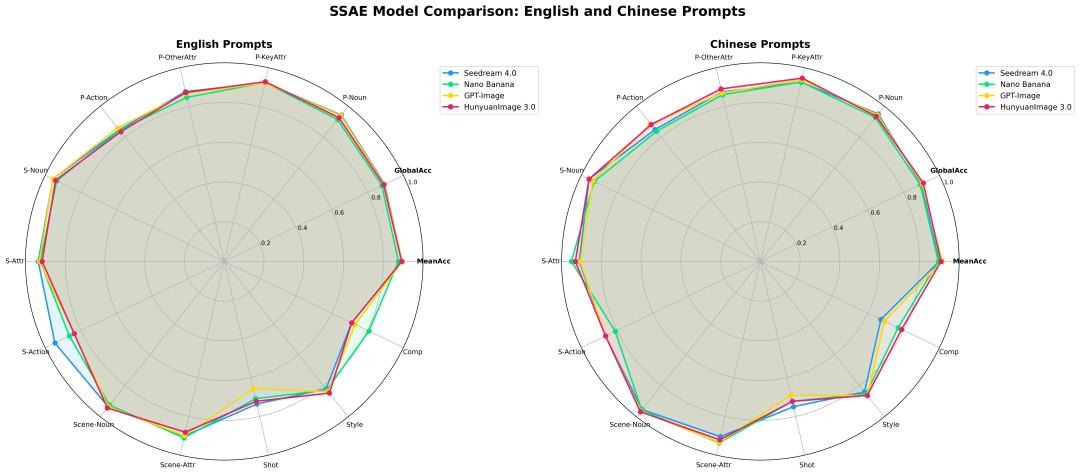
在评测环节,HunyuanImage-3.0 经过了自动化对齐测试和人工主观打分,结果显示它在细节丰富度和贴合提示的表现上,都已接近甚至超过部分闭源产品。
目前,相关资源已在 HuggingFace 和 GitHub 上同步开放。腾讯也欢迎社区开发者提交反馈和贡献,推动这一开源项目进一步完善。
参考资料:https://huggingface.co/tencent/HunyuanImage-3.0
 豫公网安备41010702003375号
豫公网安备41010702003375号