
GPT-5算力之谜:为什么比GPT-4.5更省,但依然更强?
![]() 前沿资讯
1759053598更新
前沿资讯
1759053598更新
![]() 0
0
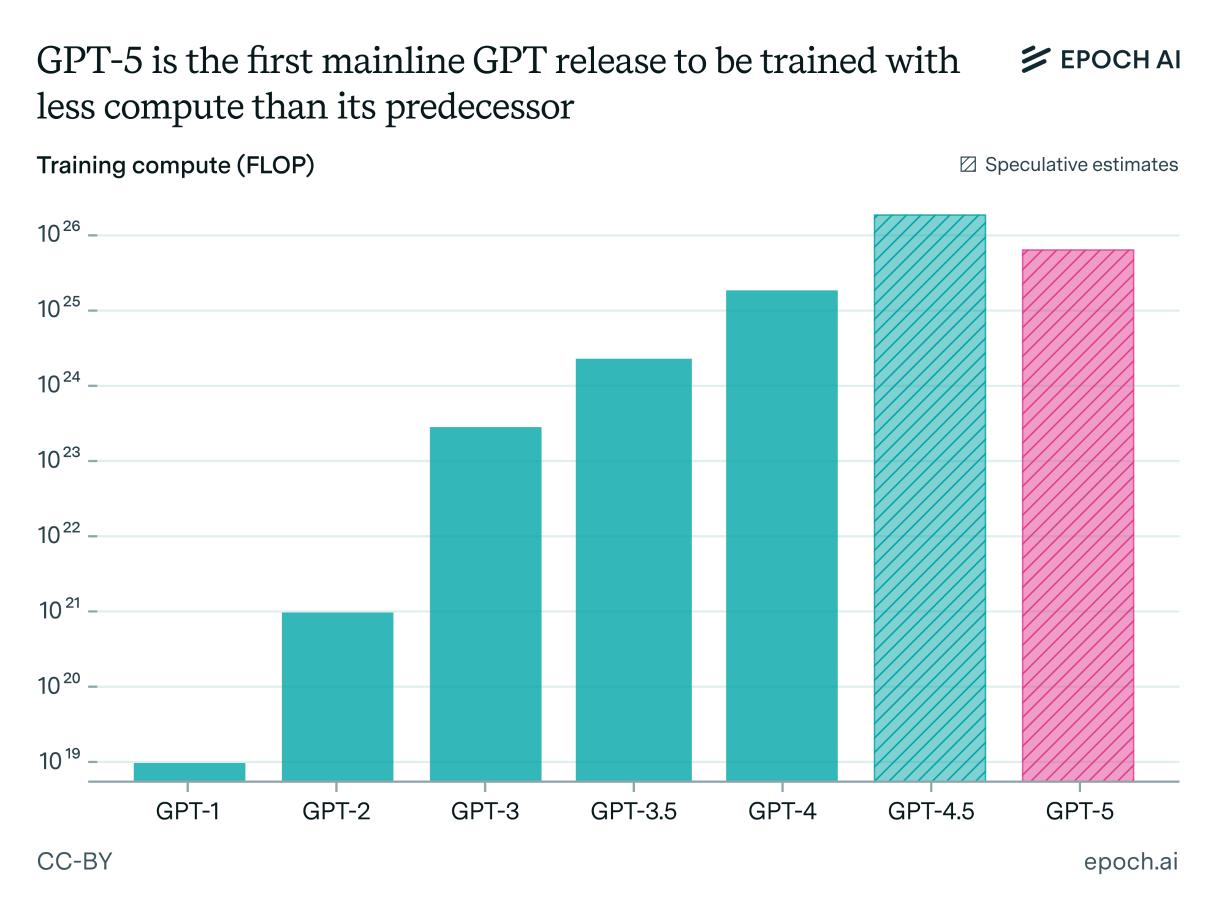
导读:研究机构Epoch AI最新数据显示,GPT-5 的训练算力投入竟然比 GPT-4.5 更少,这打破了人们对“更强版本一定需要更大算力”的固有认知。为什么会有这样的结果?答案指向了一个趋势:算力的重点,正在从训练前期转向训练后的优化。
算力重心转移:从“前期训练”到“后期优化”
过去,几乎所有的大规模AI系统都遵循一个规律:前期训练投入的算力是后期优化的上百倍。但在2024年下半年,研究人员找到了新的突破口:通过“推理优化”技术,把更多算力用在训练后的调优阶段,可以让其价值被迅猛放大。
举个简单的对比:GPT-4.5大概需要2亿美元级别的前期训练,后期优化只占200万。但到GPT-5,OpenAI可以把前期投入压缩十倍,同时依靠后期优化追平甚至超越前代效果。这样一来,整体训练算力投入少了,而且结果更好。
 为什么不是GPT-4.5继续强化?
为什么不是GPT-4.5继续强化?
有人可能会问:既然后期优化这么有效,为何不直接在 GPT-4.5 上加码?答案在于时间和成本的双重限制。
要在像 GPT-4.5 这样的大规模系统上尝试后期优化,需要更多实验、更长周期以及高质量的训练数据。而彼时市场竞争激烈,比如Anthropic在代码能力上持续领先,OpenAI没有时间等待,只能选择在相对“小一些”的模型上,把后期优化做到极致,快速推出GPT-5。
GPT-6:算力或将再度放量
那么,未来会怎样?从目前的趋势看,GPT-6 很可能重回“大算力路线”。
原因有三点:
- 后期优化的红利正在趋于见顶,继续扩大难度不小;
- OpenAI正在扩充基础设施,比如更大规模的GPU集群即将上线;
- 随着算力库存增加,未来训练再度大幅扩张成为可能。
当然,也存在一些不确定性,比如高质量数据是否足够、后期优化环境能否跟上等。但整体来看,算力投入的曲线、大概率会再次抬升。
参考资料:https://epoch.ai/gradient-updates/why-gpt5-used-less-training-compute-than-gpt45-but-gpt6-probably-wont
 豫公网安备41010702003375号
豫公网安备41010702003375号